 Overview
Mentoring is one of those subjects I can talk about till the cows come home (the other such subjects are the Julia programming language, Data Science, and Cybersecurity). What makes it different, however, is that it's something that appeals to all sorts of professionals, not just data science and cybersecurity ones. In this article, I'll attempt to illustrate that through a series of questions and answers, for easier navigation and hopefully better understanding. What? So, first of all, what is mentoring? In a nutshell, it's the formal manifestation of the most natural relationship in our species, that of passing on knowledge. This knowledge transfer is usually done from parents to children (and vice versa when it comes to the latest apps and gadgets!), from the elders to the younger individuals, and among peers with different levels of growth in a particular field. It's the most natural thing in the world to share one's knowledge and experiences with other people, often just for the sake of it. In the business world, where time is valued differently, this relationship usually takes the form of a professional relationship where money is involved, while there is a certain structure about it (e.g., regular meetings, a preassigned means of communication, etc.) Why? Well, we all have blind spots and gaps in our knowledge, plus we need to learn from others (what I refer to as dynamic learning) since solitary learning strategies are sometimes inadequate. Also, mentoring is often a powerful supplement to one's established learning strategies, enabling that person to deal with practical issues and questions that often arise from the new material. It's no coincidence that anyone in academia pursuing a challenging project, such as a dissertation, is often required to have a mentor of sorts to supervise his/her work. In some cases, such as a multi-disciplinary research project, two mentors are assigned to the learner. That was my experience during my Ph.D. at the University of London. Who? Anyone intending to learn something or hone their skills is a candidate for a mentee/protege. As for mentors, anyone you can learn from systematically and helpfully qualifies for that role. Of course, there is also the matter of availability, since many people are quite busy these days, so that's a requirement too. Practically, you cannot be a mentee or a mentor if your schedule is jam-packed. It takes time to invest for such a relationship to have a chance, just like anything worthwhile in our lives. How? Mentoring usually makes use of a rhythm in the series of meetings involved. It doesn't have to be frequent, but having a rhythm is useful nevertheless. You can use the mentoring meetings to discuss 1. new topics the learner is interested in and often tackling individually, 2. problems the learner is facing, such as those related to the new material as well as its applications, 3. specific applications of the new material to understand how it applies in practice, 4. new ideas that extend the learning material and may be the product of the learner’s creativity, 5. anything else that the learner deems necessary or useful such as career-related matters How Much? As with any product or service out there, there is a price tag involved (be very careful when someone is offering mentoring or access to "mentors" for free, as this is likely to be a scam). In general, the more you value the mentoring process, the more you're willing to pay for it. Sometimes, you can even work out an exchange kind of deal, where you offer a product or service for the mentoring you receive. More often than not, however, there is money involved, while there is also an intermediary to handle the transactions and take care of the logistics of the process. When? Well, there is no better time than now, or at least, as soon as you can. Waiting for the perfect mentor or for a time when you have enough time to focus on mentoring is futile. You can always adjust your mentoring rhythm to the circumstances of your life if needed. I've had to change the weekly meetings I have with my mentees a few times because they were either dealing with a personal situation or a work-related matter. Where? Anywhere with a good internet connection (even a mobile internet connection) or, ideally, within proximity of the mentor. I remember having been paired with a mentor during my time in Microsoft and I've mentored people in person through the "Get Online" program in Greece, back in the day when the internet was a new thing and local business people were eager to utilize it for their businesses. However, most of the mentoring these days take place over a VoIP system, such as Zoom, or even over the phone. Generally, a VoIP system is preferable since it allows you to share your screen with the mentor and enable them to understand the problem better, facilitating a potential resolution. So What? All this sounds nice and dandy, but so what? The bottom line of all this is that through mentoring, you get to improve your skills (or develop new ones if you are a newcomer in a field), refine your mindset, and even upgrade your life status over time. Many people take on mentoring to shift careers or get a better job in their line of work, while others do it to become better at their current job. Every person is unique, and mentoring addresses that uniqueness, building on it. Shameless self-promotion part If you have been following my work or my blog, you're probably already aware of the fact that I'm involved in mentoring for several years. Lately, I've decided to take it to the next level and start mentoring people on other platforms too as well as one-on-one (no intermediary platform). Although I usually deal with the main currencies of the world (e.g., USD, British pounds, and Euros), I'm also open to cryptocurrencies too. You can learn more about my mentoring endeavors on the corresponding page of this blog. Cheers!
0 Comments
 Alright, the new episode of my podcast, The Ethics of Analytics Work and Personally Identifiable Information, is now live! This is a fundamental one since here I try to clarify what PII is, a term that is used extensively in most future episodes of the podcast. Also, I talk about ethics, without getting all philosophical, and describe how it’s relevant to our lives, especially as professionals. So, check it out when you have a moment! Cheers.
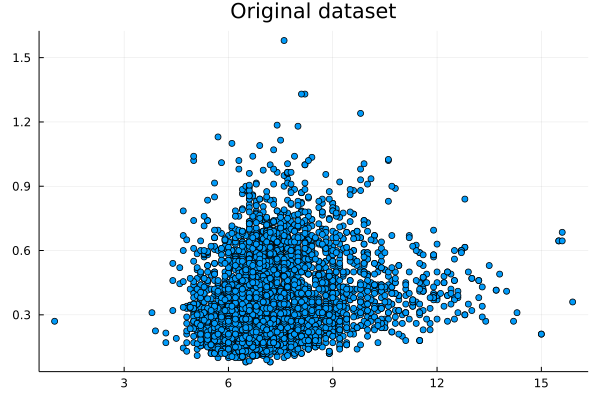
 I was never into Sampling techniques, even though I had to code a couple of them from scratch during my Ph.D. as there was no K-fold cross-validation method in Matlab at the time. Although nowadays it seems masochistic for me to code in Matlab, I am grateful for the experience. After all, the Julia language that I use regularly is very similar to Matlab in terms of syntax so this experience with Matlab coding made the learning of Julia easier and faster. Could it be possible that we could make data summarization easy and fast too, hopefully without resorting to any closed-source software like Matlab? This question has kept me wondering for a while now (perhaps more than I'm willing to admit!) partly because my data structures know-how wasn't there yet. Lately, however, I learned all about K-D trees, which are a more generalized form of binary search trees. I even published an article about it on the AIgents platform. In any case, K-D trees enable the quick finding of nearest neighbors as well as the filtering of data points within a given distance (I deliberately avoid saying hypersphere because if you've dealt with high-dimensional data as I've had, you probably detest that shape too!). In any case, finding points within a given distance (or radius if you are geometrically inclined) is necessary if you were to examine different areas of the dataset, particularly if you want to do that a lot. Since K-D trees make that easy and scalable, one can only wonder why no one ever thought about using them in data summarization yet. In simple terms, data summarization is representing the information of the original dataset with fewer data points (the fewer the better). Of course, you can do that using a centrality metric of your preference but summarizing a whole dataset, or even a variable, with one point creates more problems than it solves. It's this naive approach to data summarization that has brought about all the prejudices and discriminatory behavior over the years. Nassim Taleb is also very critical of all this and that's someone who has been around more and thought about things in more depth than most of us. Anyhow, data summarization is tricky and relatively slow. It's much easier to take a (hopefully random and unbiased) sample, right? Sure, but what if we don't want to take any chances and want to reduce the dataset optimally instead? Well, then we have no choice but to employ a data summarization method. The one I've developed recently, employing a couple of heuristics, does the trick relatively fast, plus it scales reasonably well (also, it's entirely automated, so there's no need to worry about normalization or the size of the summary dataset). Attached are the dataset I used (related to Portuguese wines) and a couple of plots, one for the first two variables of the dataset and one for the reduced version of that. The method works with K-dimensional data, but for the sake of demonstration, I only used two of them. For all this, along with a vector for the weights of the created data points, it took around 0.4 seconds on my 5-year-old machine. The reduction rate was about 65%, which is quite decent. For the whole dataset (all 13 variables) it took a bit longer: ~ 29 seconds, with a 54% reduction rate. Although the method seems promising, there are probably a few more optimizations that can be performed to it, to make it even more scalable. However, it’s a good start, particularly if you consider the new possibilities such a method offers. The one obvious one, which I’ve already explored, is data generation. The latter can be done independently from the data summarization part, but it works better if summarized data is used as an input. Another low-hanging fruit kind of application that's worth looking into is dimensionality reduction, based on the summarized dataset. All of these, however, is a story for another time. Cheers!
 Two weeks have passed since I launched the podcast and so far the number of downloads have exceeded my expectations (with over 2100 downloads so far). Yet, regardless of all this, I continue humbly with my efforts to raise awareness about the whole Privacy matter and how it's relevant to Analytics work. In the latest episode of the podcast, published just this morning, I interview Steve Hoberman, the data modeling professional and lecturer at the Columbia University I've been working with since the beginning of my career in data science. Without getting too technical, we talk about various topics related to the relationship of Analytics professionals and the Business, as well as how privacy factors in all this. This is the only episode of this podcast that doesn't contain a sponsor ad, for obvious reasons. Check it out when you have a moment!  Lately, I've been preparing a podcast on the topic of (data) Analytics and Privacy. Having completed the first few episodes, I've decided to make it available at Buzzsprout. Alternatively, you can get the RSS feed to use with either a browser add-on or some specialized program that handles RSS links: https://feeds.buzzsprout.com/1930442.rss The podcast deals with various topics related to privacy, usually from an analytics angle, or vice versa. However, it appeals to anyone who is interested in these subjects, not just specialized professionals. Clocked at around 20 minutes each, the episodes of this podcast are ideal for your daily commute or any other activity that doesn't require your full attention. Feel free to check out these links and, if you like the podcast, share these links with friends and colleagues. Cheers!  For about a month now, I’ve been working on a new technical book for Technics Publications. This is a project that I've been thinking about for a while, which is why it took me so long to start. Just like my previous book, this one will be hands-on, and I'll be using Julia for all the code notebooks involved. Also, I'll be tackling a niche topic that hasn't been done before in this breadth and depth, in non-academic books. Because of this book, I won't be writing on this blog as regularly as before.
If you are interested in technical books from Technics Publications, as well as any other material made available from this place, you can use the DSML coupon code to get a 20% discount. This discount applies to most of the books there and the PebbleU subscriptions. So, check them out when you have a moment!  Recently a new educational video platform was launched on the web. Namely, Pebble U (short for Pebble University) made its debut as a way to provide high-quality knowledge and know-how on various data-related topics. The site is subscription-based, while it requires a registration for watching the videos and any other material available on it (aka pebbles). On the bright side, it doesn't have any vexing ads! Additionally, you can request a short trial of it, for some of the available material, before you subscribe to it. Win-win! Pebble U has a unique selection of features that are very useful when consuming technical content. You can, for example, make notes and highlight parts and add bookmarks, on the books you read. As for the videos, many of them are accompanied by quizzes to embed your understanding of the topic covered. The whole platform is also available as an app for both Android and iOS devices. The topics of Pebble U cover data science (particularly machine learning and A.I., though there are some Stats related videos too), Programming (particularly Python), and Business, among other categories. As the platform grows, it is expected to include additional topics and a larger number of content creators. All the videos are organized in meaningful groups called disciplines, making it easy to build on your knowledge. Of course, if you care for a particular discipline only, you can subscribe to material of that area only, saving you some money. 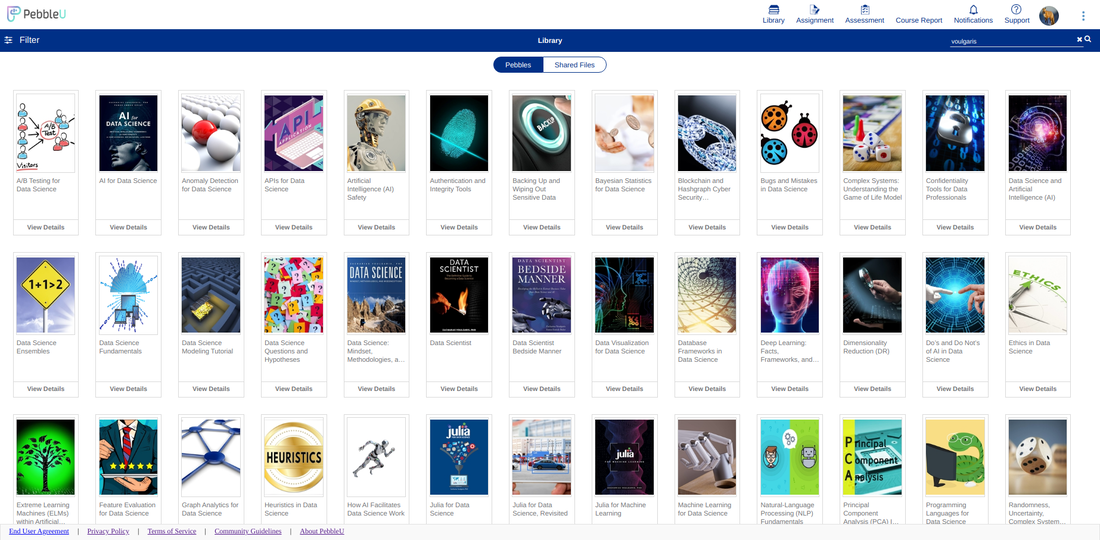 In the screenshot above, you can see some of my own material that are available on PebbleU right now. Many of them are from my Safari days, but there are also some newer ones, particularly on the topic of Cybersecurity. By the way, if you find the subscription price a bit steep, remember that you can use the coupon code DSML I've mentioned in previous posts, to get a 20% discount. So, check it out when you have some time. This may be the beginning of something great!  I've talked about mentoring before and even mentioned it a few times in my books and videos. After all, it's an integral part of learning data science and A.I., among other fields. However, not all mentoring is created equal, and that's probably one of the most valuable lessons to learn in education. Unfortunately, to learn such a lesson you usually have to rely on your own experiences (since not many people want to talk about this matter). Nowadays, everyone can sign up to particular sites and pretend to be a mentor. Sites like that often offer this for free since they know that charging for such a low-quality service would make them liable to lawsuits. However, the learner of data science and other fields often lacks the discernment to see such places for what they are in reality. Fortunately, however, there are much better alternatives. Across the web, some sites provide proper mentoring, usually at a reasonable price, for all sorts of disciplines, including data science and A.I., among other fields. Many of these sites incorporate mentoring as part of their educational services, which include online classes too. However, that's not always the case. Someone can mentor you in your field of choice without having to follow a curriculum. This option is particularly appealing to professionals and people who have a relatively full schedule. Proper mentoring involves various things, such as the following: * career advice * putting together a good resume or CV * interview practice (particularly technical interviews) * feedback on hands-on projects Ideally, mentoring is a long-term process, though you can also opt for a handful of sessions to tackle specific problems you need help with. As long as you have an open mind, a willingness to learn, and value your mentor’s time, you are good to go. Naturally, bringing a specific task into the mentoring session can also be very useful, as it can help make it focused and productive. By the way, if you wish to work with me as a mentee, I have some availability these months. What's more, I have set up a way to schedule these sessions efficiently using Calendly and have established collaboration with a freelance platform to handle payments and such (my Kwork link). So, if you are up for some proper mentoring, feel free to give me a buzz. Cheers!  Every year, there is a data modeling conference that takes place around the world. Its name is Data Modeling Zone, or DMZ for short (not to be confused with the DMZ in Korea, which isn't that good a place for data professionals!). Just like last year and the year before that, this year, I'll be participating in the conference as a speaker, talking about data science- and AI-related topics.
Namely, I'll talk about the common misconceptions about Machine Learning, something you may remember from my previous books. Still, this talk will cover the topic in more depth and help even newcomers to the field distinguish between the hype and the reality of machine learning. After my presentation, there will be some time for Q & A, so if you have any burning questions about this topic, you have a chance to have them answered. Just like last year, DMZ is going to be online this year, making it super easy for you to attend, regardless of where you are. Also, there are plenty of interesting talks on various data-related topics, as you can see from the conference’s program. I hope to see you there this November 18th!  I was never into Clustering. My Ph.D. was in Classification, and later on, I explored Regression on my own. I delved into unsupervised learning too, mostly dimensionality reduction, for which I've written extensively (even published papers on it). For some reason, Clustering seemed like a solved problem, and as one of my supervisors in my Ph.D. was a Clustering expert (he had even written books on this subject) I figured that there isn't much for me to offer there. Then I started mentoring data science students and dug deeper into this topic. At one point, I reached out to some data scientists I'd befriended over the years asking them this same question. The best responses I got were that DBSCAN is mostly deterministic (though not exactly deterministic if you look under the hood) and that K-means (along with its powerful variant, K-means++) was lightweight and scalable. So, I decided to look into this matter anew and see if I could clean up some of the dust it has accumulated with my BROOM. Please note that when I started looking into this topic, I had no intention to show off my new framework nor to diminish anyone's work on this sub-fiend of data science. I have great respect for the people who have worked on Clustering algorithms, be it in research or their application-based work. With all that out of the way, let's delve into it. First of all, deterministic Clustering is possible even if many data scientists will have you believe otherwise. One could argue that any data science algorithm can be done deterministically though this wouldn't be an efficient approach. That's why stochastic algorithms are in use, particularly in challenging problems like Clustering. There is nothing wrong with that. It's just frustrating when you get a different result every time you run the algorithm and have to set a random seed to ensure that it doesn't change the next time you use that code notebook where it lives. So, deterministic is an option, just not a popular one. What about being lightweight? Well, if it's an algorithm that requires running a particular process again and again until it converges (like K-means), maybe it's lightweight, but probably not so much since it's time-consuming. Also, most algorithms worth their salt aren't as simple as K-means, which though super-efficient, leaves a lot to be desired. Let's not forget the assumptions it makes about the clusters and its reliance on distance, which tends to fail when several dimensions are present. So, in a multi-dimensional data space, K-means isn't a good option, and just like any other clustering algorithm, it struggles. DBSCAN struggles too, but for a different reason (density calculations aren't easy, and in multi-dimensional space, they are a real drag). So, where does that leave us? Well, this is quite a beast that we have to deal with (the combination of a deterministic process and it being lightweight), so we'll need a bigger boat! We'll need an enormous boat, one armed with the latest weapons we can muster. Since we don't have the computational power for that, we'll have to make do with what we have, something that none of the other brilliant Clustering experts had at their disposal: BROOM. This framework can handle data in ways previously thought impossible (or at least unfeasible). High dimensionality? Check. Advanced heuristics for similarity? Check. An algorithm that features higher complexity without being computationally complex? Check. But the key thing BROOM yields that many Clustering experts would kill for is the initial centroids. Granted that they are way more than we need, it's better than nothing and better than the guesswork K-means relies on due to its nature. 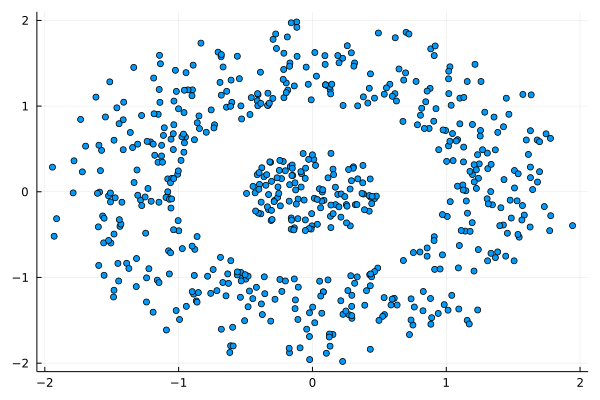 In the toy dataset visualized above, I applied the optimal clustering method I've developed based on BROOM, there were two distinct groups in the dataset across the approximately 600 data points located on a Euclidean plane. Interestingly, their centers were almost the same, so K-means wouldn't have a chance to solve this problem, no matter how many pluses you put after its name. The initial centroids provided by BROOM were in the ballpark of 75, which is way too high. After the first phase of the algorithm, they were reduced to 7 (!) though even that number was too high for that dataset. 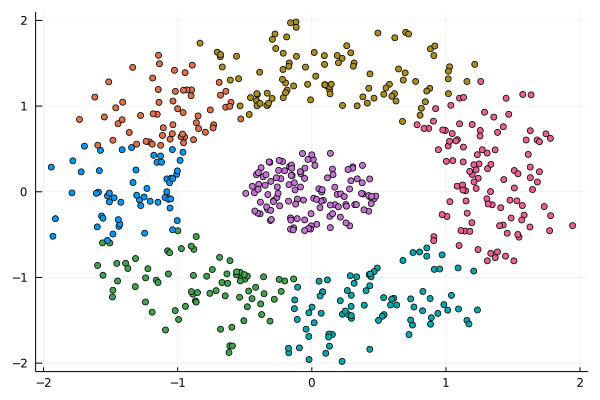 After some refinement, which took place in the second phase of the algorithm, they were reduced to 2. The whole process took less than 0.4 seconds on my 5-year-old laptop. The outputs of that Clustering algorithm included the labels, the centroids, the indexes of the data points of each cluster, the number of data points in each cluster, and the number of clusters, all as separate variables. Naturally, every time the algorithm was run it yielded the same results since it's deterministic. 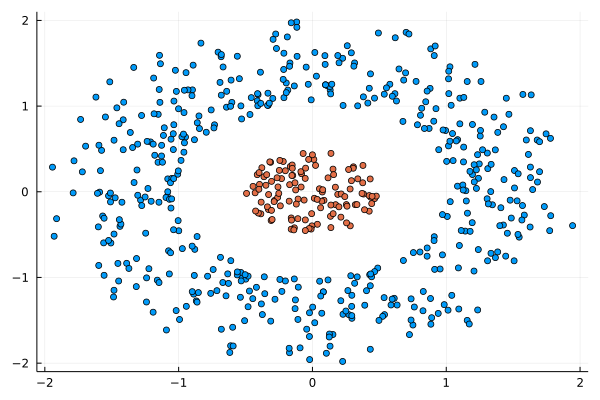 Before we can generalize the conclusions that we can draw from this case study, we need to do further experimentation. Nevertheless, this is a step in the right direction and a very promising start. Hopefully, others will join me in this research and help bring Clustering the limelight it deserves, as a powerful data exploration methodology. Cheers! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
December 2022
Categories
All
|
||

 RSS Feed
RSS Feed