 Unfortunately, datasets aren't as easy to gauge as the butterflies in this picture. Yet, even if the simpler cases where we can make a descriptive plot to highlight the geometry involved, similarity is not a binary matter. Two datasets may be somewhat similar or dissimilar, without being identical or in stark contrast. So, how could we gauge similarity in an N-dimensional space? The simplest thing to do is run a bunch of t-tests, one for each variable involved. This approach may be fine for someone new to the field (especially if the people managing this person's team aren't knowledgeable about these matters), but it won't work well. There are several underlying assumptions in this strategy that rob it of its validity and, possibly, its effectiveness. The Index of Congruence is a simple heuristic based on the Index of Peculiarity, which in turn is congruent to the Index of Discernibility (though not focused on classification scenarios per se). The Index of Congruence does one simple thing: gauge the similarity of two matrices of real numbers on a scale of 0 to 1 with high values denoting strong similarity. It's not perfect but it does what it sets out to do, and does so swiftly. If one of the datasets is larger than a given threshold, some (random) sampling takes place in both datasets, preserving the original ratio in sizes, before the heuristic is applied. Also, normalization takes place in the back-end without worrying the user, since we have better things to do than worry about the scale of the variables at hand, right? I could write about this heuristic for a while, but I'm sure you'd rather see it in action. So, I'm attaching a Jupyter notebook that you can check out on your own. No, I haven't switched to this kind of code notebook as I'm still in favor of Neptune notebooks, but when it comes to showcasing something, Jupyter notebooks remain the best option. Cheers!
0 Comments
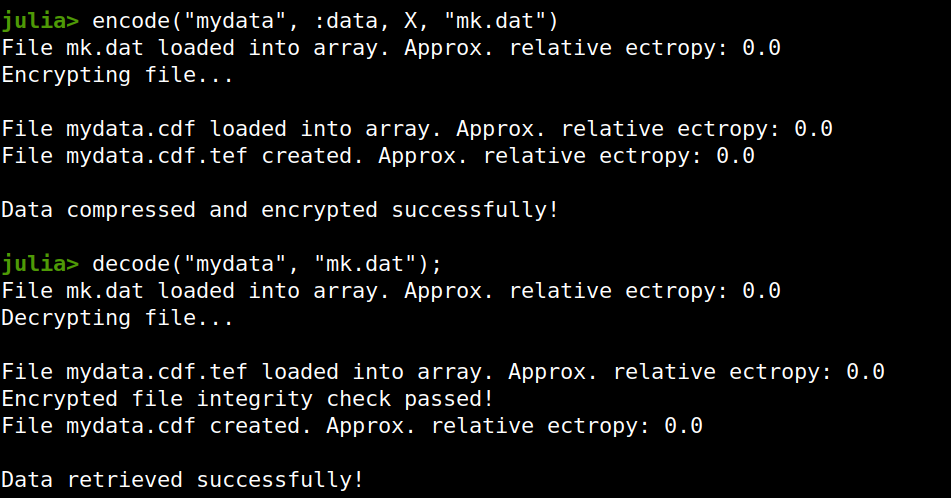
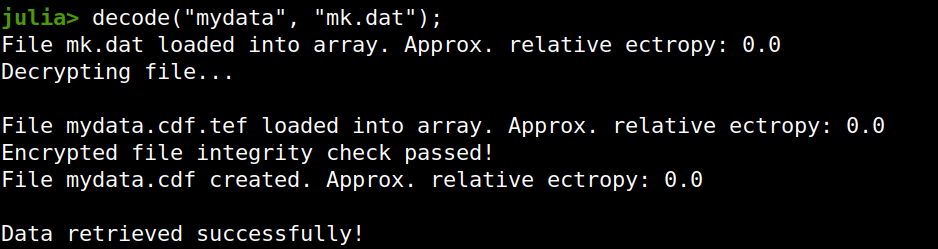
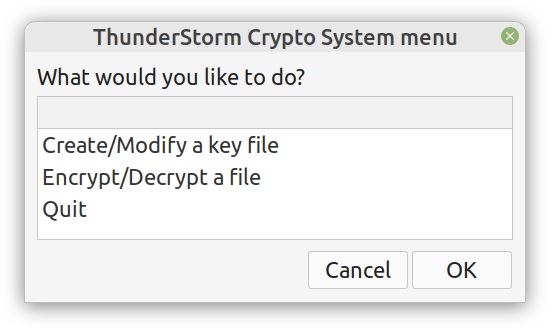
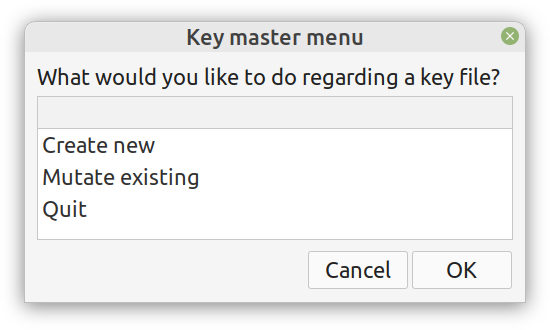
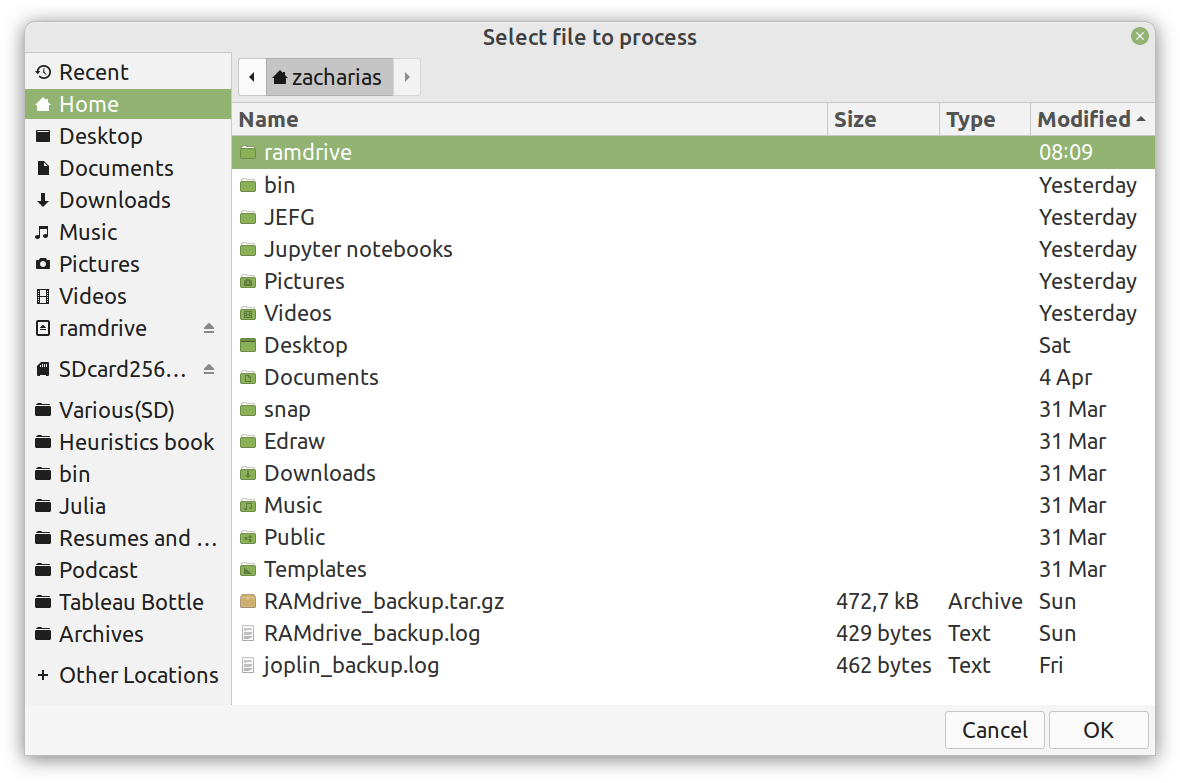
 Lately I published an episode of my podcast where I talk about compression and encryption as privacy tools (link). That’s all nice and dandy but how do we do any of that in practice? Well, most compression programs have an encryption option, which may be sufficient for low-confidentiality documents. But what about datasets that contain lots of PII? And if you are like me, you may use Julia for processing them, since it’s by far the most efficient programming language for the task, that’s also high-level. Enter ComCrypt, a simple script that does high-quality compression and quantum-proof encryption all in one go. Namely, it makes use of the CDF script which I’ve talked about before (it’s been about two years since I created it) for compressing the data into an archive having the .cdf extension (which stands for compressed data format and it’s native to Julia). Then it applies ThunderStorm to it, using an external key file. If anything goes wrong throughout this process, ComCrypt alerts the user with some error message informing about the part that threw the error. Otherwise, it yields a message saying that the data has been compressed successfully. The reverse process shares the same philosophy. Currently, ComCrypt at its first version so its scope is a bit limited (e.g., it handles only a single data object per file). However, there are ways to make it more usable and useful. In any case, it’s already a useful little tool for keeping your data safe when working in the Julia environment. Also, it’s very light on the dependencies (just one external library and a few Julia scripts). Cheers.  Overview I've been working on this cipher for several years now, and although it's not the first one I've developed, it's the best one, so far. Not just in terms of security but also in speed and customization. I haven't touched the algorithm in a couple of years now, but I recently did some updates on its shell functions and its GUI for better usability. But I'm getting ahead of myself. Let's start with some basics first, in case you are not familiar with it. What ThunderStorm Is ThunderStorm is a semi-symmetric encryption system designed for codes impenetrable by conventional cryptanalysis methods. Unlike other encryption methods, it doesn't rely on prime numbers and factoring, while it employs true randomness in the keys it uses for additional security. It currently exists in two versions: one that's order-sensitive and one that's purely symmetric and order-indifferent. The former makes for a stronger cipher, while the latter is lighter. ThunderStorm is implemented entirely in Julia (recently tested in v.1.7.2 with no issues) and has minimal dependencies on any libraries. How It Works In a nutshell, ThunderStorm works as follows. It captures all the relevant information regarding the size of the original file and its hash. It then encrypts it using the hash of the key. This is the header of the encrypted archive. Then a random amount of noise is created and added to the original file. After that, the data is encrypted and shuffled using the key, in a byte-wise fashion. The resulting archive, which is somewhat larger than the original is outputted using a file extension that makes it clear what it is. For the decryption process, the reverse is done. Note that if a single bit in the key file is off, the decryption process won't work, or if it does, it will yield a completely different file that would be unrecognizable. Also, if you were to take a random byte in the encrypted archive there is no way of knowing if that byte is an encrypted part of the original file (it could be just noise) or if it is which part of the file it comes from or what it is exactly. Also, only part of the key is usually used for the encryption, while its parts are shuffled before being utilized in the encryption process. I had published a video on ThunderStorm back in my Safari days, but it's no longer available since the contract with O'Reilly (which acquired Safari at one point) came to an end. ThunderStorm Use Cases The ThunderStorm system has several real-world use cases. Primarily, it is ideal for individual use, particularly for static documents (e.g., a password archive, financial records, etc.). This includes documents that are stored in the cloud or a web server. Additionally, ThunderStorm can be modified to be used for exchanging sensitive documents, where increased cybersecurity is a requirement. For all the use cases, large encryption keys are strongly recommended, something possible through an auxiliary method of the ThunderStorm system. A large key can be manufactured in such a way that it has zero ectropy (i.e., maximal entropy possible), making cryptanalysis extremely difficult if not altogether impossible. The fact that keys can be reused in ThunderStorm with minimal risk is an asset that can be harnessed for efficiency. Latest Improvements Since I'm a big fan of continuous improvement (Total Quality Management), I decided to make a GUI for ThunderStorm, even though I'm not a GUI kind of guy. Still, after having developed my BASH scripting skills enough, I was able to do that. So, recently I came up with a new script that leverages a few window screens to facilitate the use of this program. It still uses Julia on the back-end, but it can run directly from the shell (or the file manager, if you prefer). Below are some screenshots of the interactive aspects of that script. Note that some of the functionality of ThunderStorm was removed to make the whole program easier for the average user. For the more tech-savvy users, the functionality remains and can be accessed through the corresponding Julia scripts. Parting Thoughts Probably this is not the last update on ThunderStorm since it's been my pet project for a while now. Also, considering how feeble most ciphers are when it comes to the quantum threat, someday enough people may see value in a robust and unconventional cipher, to warrant further R&D on it. Until then, it will probably remain a niche thing, much like the language it was written in, as most high-level developers prefer to stick with the languages they know instead of going for a newer and objectively better language like Julia. Cheers!  About five months ago, I started writing a new technical book. I didn't have to, but the idea was burning me, and as I had been working on a particular data science topic the previous months, I felt it deserved to be shared with a larger audience. Of course, I could have just shared some code or perhaps put together some article, but the idea deserved more. So, I reached out to my publisher, sent him a proposal with an outline of the book, and before long, I was good to go! During these months I had been writing regularly (pretty much daily, at least on weekdays), with just a couple of weeks off, one for the Christmas holidays and one for the preparation of my podcast. This book project involved both text, images, and code (in the form of a new type of code notebook, for Julia). So, at least, I didn't get bored, plus I was a bit imaginative with a couple of the problems I tackled in the code notebooks. Although it's a bit soon to tell when the book will be out, at least the most time-consuming part is behind me now. Hopefully, I'll be able to focus more on other projects now. I'll keep you posted through this blog regarding updates on the book. Cheers! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
||

 RSS Feed
RSS Feed