 Lately, we've put together a new survey to better understand this area and the main pain points associated with it. It would be great if you could contribute through a response and perhaps through sharing this survey with friends and colleagues. Cheers! https://s.surveyplanet.com/arw5bz4a Due to the success of the Analytics and Privacy podcast in the previous few months, when the first season aired, I decided to renew it for another season. So, this September, I launched the second season of the podcast. So far, I have three interviews planned, two of which have already been recorded. Also, there are a few solo episodes too, where I talk about various topics, such as Passwords, AI as a privacy threat, and more. Since I joined Polywork, many people have connected with me on various podcast-related collaborations, some of which are related to this podcast. So, expect to see more interview episodes in the months to come.
There is no official sponsor for this season of the podcast yet, so if you have a company or organization that you wish to promote through an ad in the various episodes (it doesn’t have to be all the remaining episodes!), feel free to contact me. Cheers!  My latest book, The Data Path Less Traveled, published by Technics Publications, is going to make its official debut this Friday, September 9. If you are up for it, you can participate in a short presentation for it, along with Q&A, to get acquainted with the topic (and me). This online event is at 10 am EST (7 am PST, 4 pm CET) and you can register for it here. It's entirely free and you don't need to have any experience or expertise on this topic to follow it. I hope to see you there!
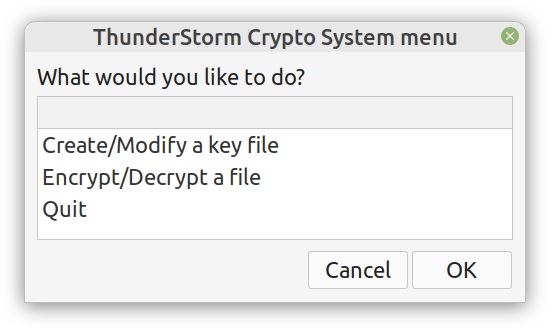
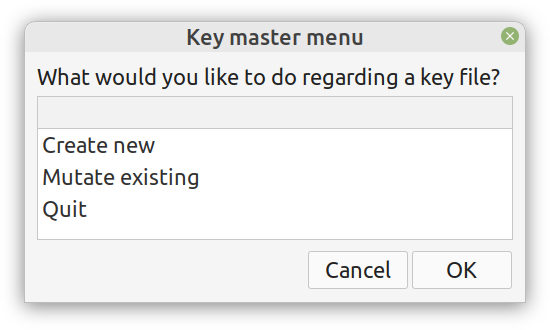
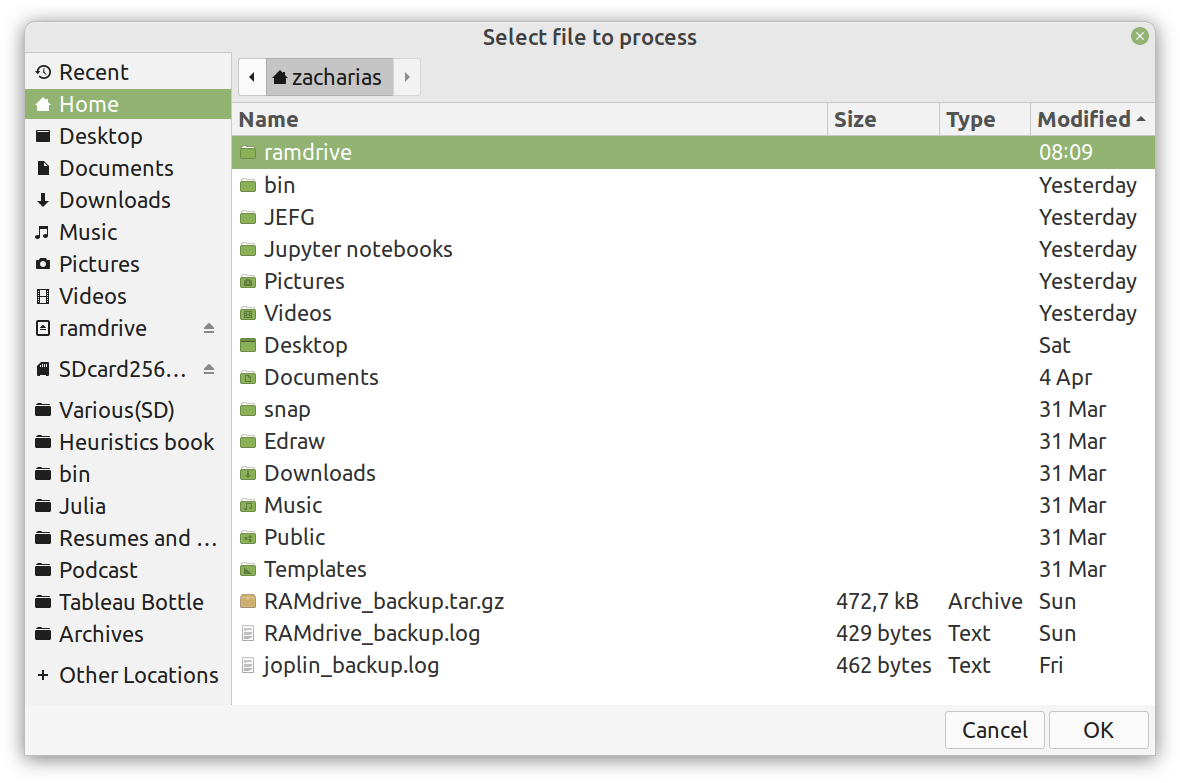
 Although I really enjoy Julia and other new programming languages, I also use Python, SQL, etc. for various projects. Beyond that, I tend to mentor students in these more conventional languages, as it's part of their curriculum. Learning these languages, however, often comes at a cost and if someone has already shelled thousands of dollars in a course, it's doubtful they would be willing to spend more to go deeper on these subjects. Fortunately, AIgents has you covered. This Data Science and AI platform for practitioners and learners in these fields recently launched a learning branch on its website, featuring a selection of useful resources for learning these technologies (these live on various sites, which you can find on your own but AIgents saves you time by do this tedious task for you and curating them to some extent). The best part is that all of these resources are free while there is also a community this platform has, to facilitate further such initiatives. You can check it out here. Cheers!  Remember all those videos I used to make for Safari / O'Reily's Learning platform? Well, most of them are now gone but the best ones (according to the publisher) are still available for you, in a pay-per-view mode. Learn more about them through this 1-minute video I made about them. It's just six of them at the moment, but I may get more of them out there in the months to come. Cheers  It's been about 7.5 months since I signed the contract for this book and now it's already on the bookshelves (so to speak). At least the book is available to buy at the publisher's website, in print format, PDF format, or a bundle of both. If you have been paying attention through this blog, you may be aware that you can get it with a 20% discount if you use a certain 4-letter code, when buying it from the publisher (hint: the code it DSML). I put a lot of work into this book because it's probably going to be my last (technical) book, at least for the foreseeable future. Its topic is one that I've been very passionate about for many years and continue to delve into even today. Even though the book is very hands-on, accompanied by code notebooks (or codebooks as I often call them), you can read it without getting into the code aspects of it. Also, the concepts covered in it are applicable in any programming language used in data science and A.I. If you want to learn more about the book, feel free to attend the (free) event on Friday, September 9th at 10 am ET (register through this link). I hope to see you then! Update: I've made a short video about this, which I encourage you to share with anyone who might be interested: https://share.vidyard.com/watch/d58yZn9Y1cnWq6rQAsrotq?  Overview I've been working on this cipher for several years now, and although it's not the first one I've developed, it's the best one, so far. Not just in terms of security but also in speed and customization. I haven't touched the algorithm in a couple of years now, but I recently did some updates on its shell functions and its GUI for better usability. But I'm getting ahead of myself. Let's start with some basics first, in case you are not familiar with it. What ThunderStorm Is ThunderStorm is a semi-symmetric encryption system designed for codes impenetrable by conventional cryptanalysis methods. Unlike other encryption methods, it doesn't rely on prime numbers and factoring, while it employs true randomness in the keys it uses for additional security. It currently exists in two versions: one that's order-sensitive and one that's purely symmetric and order-indifferent. The former makes for a stronger cipher, while the latter is lighter. ThunderStorm is implemented entirely in Julia (recently tested in v.1.7.2 with no issues) and has minimal dependencies on any libraries. How It Works In a nutshell, ThunderStorm works as follows. It captures all the relevant information regarding the size of the original file and its hash. It then encrypts it using the hash of the key. This is the header of the encrypted archive. Then a random amount of noise is created and added to the original file. After that, the data is encrypted and shuffled using the key, in a byte-wise fashion. The resulting archive, which is somewhat larger than the original is outputted using a file extension that makes it clear what it is. For the decryption process, the reverse is done. Note that if a single bit in the key file is off, the decryption process won't work, or if it does, it will yield a completely different file that would be unrecognizable. Also, if you were to take a random byte in the encrypted archive there is no way of knowing if that byte is an encrypted part of the original file (it could be just noise) or if it is which part of the file it comes from or what it is exactly. Also, only part of the key is usually used for the encryption, while its parts are shuffled before being utilized in the encryption process. I had published a video on ThunderStorm back in my Safari days, but it's no longer available since the contract with O'Reilly (which acquired Safari at one point) came to an end. ThunderStorm Use Cases The ThunderStorm system has several real-world use cases. Primarily, it is ideal for individual use, particularly for static documents (e.g., a password archive, financial records, etc.). This includes documents that are stored in the cloud or a web server. Additionally, ThunderStorm can be modified to be used for exchanging sensitive documents, where increased cybersecurity is a requirement. For all the use cases, large encryption keys are strongly recommended, something possible through an auxiliary method of the ThunderStorm system. A large key can be manufactured in such a way that it has zero ectropy (i.e., maximal entropy possible), making cryptanalysis extremely difficult if not altogether impossible. The fact that keys can be reused in ThunderStorm with minimal risk is an asset that can be harnessed for efficiency. Latest Improvements Since I'm a big fan of continuous improvement (Total Quality Management), I decided to make a GUI for ThunderStorm, even though I'm not a GUI kind of guy. Still, after having developed my BASH scripting skills enough, I was able to do that. So, recently I came up with a new script that leverages a few window screens to facilitate the use of this program. It still uses Julia on the back-end, but it can run directly from the shell (or the file manager, if you prefer). Below are some screenshots of the interactive aspects of that script. Note that some of the functionality of ThunderStorm was removed to make the whole program easier for the average user. For the more tech-savvy users, the functionality remains and can be accessed through the corresponding Julia scripts. Parting Thoughts Probably this is not the last update on ThunderStorm since it's been my pet project for a while now. Also, considering how feeble most ciphers are when it comes to the quantum threat, someday enough people may see value in a robust and unconventional cipher, to warrant further R&D on it. Until then, it will probably remain a niche thing, much like the language it was written in, as most high-level developers prefer to stick with the languages they know instead of going for a newer and objectively better language like Julia. Cheers!  About five months ago, I started writing a new technical book. I didn't have to, but the idea was burning me, and as I had been working on a particular data science topic the previous months, I felt it deserved to be shared with a larger audience. Of course, I could have just shared some code or perhaps put together some article, but the idea deserved more. So, I reached out to my publisher, sent him a proposal with an outline of the book, and before long, I was good to go! During these months I had been writing regularly (pretty much daily, at least on weekdays), with just a couple of weeks off, one for the Christmas holidays and one for the preparation of my podcast. This book project involved both text, images, and code (in the form of a new type of code notebook, for Julia). So, at least, I didn't get bored, plus I was a bit imaginative with a couple of the problems I tackled in the code notebooks. Although it's a bit soon to tell when the book will be out, at least the most time-consuming part is behind me now. Hopefully, I'll be able to focus more on other projects now. I'll keep you posted through this blog regarding updates on the book. Cheers!  As much as I'd love to write a (probably long) post about this, I'd rather use my voice. So, if you are interested in learning more about this topic, check out the latest episode of my podcast, available on Buzzsprout and a few other places (e.g., Spotify). Cheers!
 Alright, the new episode of my podcast, The Ethics of Analytics Work and Personally Identifiable Information, is now live! This is a fundamental one since here I try to clarify what PII is, a term that is used extensively in most future episodes of the podcast. Also, I talk about ethics, without getting all philosophical, and describe how it’s relevant to our lives, especially as professionals. So, check it out when you have a moment! Cheers.
|
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|

 RSS Feed
RSS Feed