 About 2 years ago I created a video on the Julia language and how it applies to data science. Although I was still learning the ropes of video creation, I had a lot of useful things to say about the language since I had just published a book on it, a book that is still quite popular among the Julia learners as well as those getting into data science through programming. Now, after version 1.0 has come out, I decided to revisit this topic and provide an update about how Julia factors in the whole data science matter, as well as how it contributes to A.I. applications among other relevant topics. In this video, I explore all these points and without getting too technical, I showcase an updated view of how Julia is still a relevant tool when it comes to data science projects. Enjoy!
Note that you'll need a subscription in order to be able to view this video on the Safari platform. However, once you have paid for it (either for a month or a year), you'll have access to all the content published in there, including all my other videos and books. Cheers!  As you may have heard, article 13 of the European copyright legislation is seen as a major issue for content creators of all sorts, sharing their creations online. Specifically, it can basically block the viewing of various videos (and other creative content) in various EU countries (including the UK). This is because this articles for some reason sees the viewing of this content in certain countries a violation of the content creators’ rights and in an effort to protect creativity, it limits where this content is made available. I’m not going to argue here about the futility of such a legislation or why such laws don’t make any sense in a world where content creators strive for increased exposure, while it’s extremely unlikely for someone to own all the elements of their videos. Also, personal branding is something the lawyers that drafted this legislation probably don’t quite understand, something reflected in how this law is formulated. Whatever the case, this law is focused on various social media platforms, such as YouTube and Instagram and does not affect SafariBooksOnline. So, if you are like me and publish your content in respectable platforms where there is a quality control and no issue with European legislation, you are fine. I can’t say that I like this situation with some bizarre law prohibiting the viewing of videos in various countries, but I’m not going to lose sleep over it since this is but the tip of the iceberg of injustices these “free” video platforms offer. Besides, there are various platforms where someone can publish creative content, especially when it comes to educational topics, so opting for the easy way of YouTube is just not the most professional approach. After all, the focus on such a platform is on the quantity and on some ever-changing algorithm for promoting this content, something that doesn’t benefit the content creator to start with. So, if you have some ideas for educational videos, Safari is a great place to publish them and doesn’t get any headaches from the European Parliament or any other authority that claims to understand how creative content works. As a bonus, you get to collect royalties from your videos, regardless of when they were published or if they are on some “hot” topic, while click-bait is not that common in the video titles. This respect towards the viewers of the videos is reciprocated through a handsome payment from their part, instead of having to put up with annoying ads and overcrowded web pages. So perhaps going with YouTube is not as glamorous as it may seem, with or without Article 13.  For all of you celebrating Thanksgiving, happy Thanksgiving! I don't need to tell you about the importance of being grateful about the good stuff we've good going on in our lives. However, I can do need to tell you is that I'm grateful for all of you visiting my blog and checking out the content I'm developing for Data Science, Artificial Intelligence, Cyber-security, and even Programming (to a lesser extent), in an effort to clarify certain matters and inspire you to learn things in a more in-depth and more enjoyable way. Also, grateful for being in this fascinating field and watching it evolve into something useful and self-sufficient. What are you grateful for? Enjoy this great family holiday with your loved ones, and if you have some time, check out some of my videos / books!  So, after attending this truly eye-opening conference in Amsterdam last month, I felt obliged to share at least some of the stuff (most relevant to data science) I got from it with other people, through a reliable content sharing platform. So, I wrote an article about this topic on beBee and then created a video which is now available on Safari. Note that this is a bit high-level as a video, with emphasis on managerial and senior-level data science practices, rather than hands-on aspects of the craft. However, every data scientist can benefit from this knowledge, especially when dealing with sensitive data. Also, Safari content requires a subscription in order to be accessible to its full length.  In an interview I recently watched, Elon Musk put forward the case of a utility (objective) function for a hypothetical advanced A.I. (basically an AGI) and how special attention must be given to such a task to avoid undesirable results. So, he suggested we use some utility function some person had recommended (probably an A.I. expert), namely that of maximizing “freedom of action for everyone,” something that’s quite reasonable and perhaps even profound if you think about it. However, if you think more about it, it becomes evident that it’s a terrible, terrible idea! First of all, I mean no disrespect to Elon Musk. I think many of the things he’s created are great, even if some of his ideas are somewhat extreme. So even if he is not a role model of mine, I admire him as a tech entrepreneur and find that he has a lot to offer to the world through his businesses and his ideas for a better world. Except of course his idea for a utility function; that would be catastrophic, though I’m sure that in his mind it’s a brilliant solution to the utility function problem. For starters, freedom is a very abstract concept even if it’s made more specific by the term “of action” to clarify it. How do you measure freedom of action? How would an A.I. understand this concept, especially if it never gets to experience it? Then, would maximum freedom be a good thing necessarily? Isn’t that a form of anarchy in a way? These are things that need to be addressed before asking an A.I. engineer to implement such a function for this hypothetical A.I. So, unless we figure this out, we cannot be sure that this A.I. will be benign, even if its creators have the best intentions in the world for it. For example, an A.I. that makes use of this utility function may accelerate the depletion of natural resources of this planet (and any other planet it has access to), in order to ensure that everyone, even some random criminal on the streets or an inmate in a high security prison, has as much freedom of action as possible. Do you see where I’m going with this? Perhaps I’d better stop here before this whole post turns into some dystopian scenario or something. The utility function problem is a difficult one and in all fairness Elon Musk is not someone knowledgeable enough in A.I. to be able to provide a bullet-proof solution to it. He may know a lot about the topic but I doubt he’s ever created an A.I. system from scratch. And unless you are close to the metal about these things, any ideas you have about how things should be regarding the high-level aspects of such complex systems is just an opinion on the matter, not a serious candidate for a solution to the problem at hand. The latter would be something that has legs and right now it seems that Mr. Musk’s suggestion is floating in the clouds just like many futurists when they talk about A.I. Perhaps that’s why many people don’t take Elon Musk’s warnings about A.I. very seriously, although I believe that’s one of the things he’s got right. Despite the inevitable risks such an endeavor has, I’ll venture to make a suggestion of my own for a utility function, namely one that evolves over time. In other words, I propose a narrow A.I. whose sole purpose is to optimize the utility function of the AGI, perhaps in a Reinforcement Learning fashion, based on the feedback it receives from other people, while it starts with a utility function that’s as risk-free as possible (based on some simulations we run before we deploy it to the AGI). Some core heuristics may be in place to ensure a large enough diversity of signals that this A.I. will take into account, coordinating the various objectives / values that the AGI will have to uphold. Besides, it would be naive to assume that a human being, no matter how knowledgeable, can be in a position to come up with a utility function that can apply to some creature more intelligent than all the people in the world, forever. If our own evolution has taught as anything is that there are no absolutes in nature and that we evolve to become better and adjust our values according to the circumstances we face and the challenges we wish to overcome. Why should an AGI be any different, considering that it’s created in our own image?  Although the debate between Frequentist and Bayesian statisticians sometimes takes a more comical turn (XKCD strip), it is still important for a data scientist to know a few things about Bayesian Stats. Of course, purists of the craft will argue that Frequentist Stats will suffice but if you want to stand out of the crowd, it would definitely help going beyond the beaten path, when it comes to data analytics know-how.
This video I made recently highlights the key elements of Bayesian Stats, focusing on the concepts that although fairly straight-forward, may be obscure to the newcomer. Also, without disregarding the invaluable contribution of Frequentist Stats to data science, this video explores how the two differ and how Bayesian Stats has a lot in common with other, more modern, data analytics frameworks. Check it out when you get the chance! Note that a subscription to the Safari platform is necessary in order to view the video in its entirety.  Well, like most things of a certain level of sophistication, the answer is it depends. But before we delve into this matter, let’s start with defining what DS research is exactly. By this term, I refer to with the advancement of the field through the experimentation around new ideas, methods, techniques, and even the development and testing of new algorithms applicable to data science. Sounds like a lot but in practice there is a great deal of specialization so it’s not as overwhelming. For example, someone may do research in the data science technology focusing on distributed computing, while someone else focus on the design of a new supervised learning technique or a heuristic. But don’t you need funding for all this? Well, in the traditional approach to research funding, usually in the form of grants sponsored by a government or some large organization, is something essential. After all, scientific research requires a great deal of resources and people who although passionate about the subject, may not work for free. Nevertheless, the expenses of research in data science are minimal, meaning that you don’t need a huge grant in order to get the ball rolling. In essence, when you do DS research your key expenses are your time and the cloud computing rental. After all, Amazon and Microsoft need to make some money too when you are using their cloud services for your projects. Still, the prototyping is something you can do on your own computer so the cloud bill doesn’t have to be very high, unless you are working with a particularly large dataset, one that qualifies as big data. I’m not saying that everyone can do data science research on his own. However, nowadays it’s easier than ever before to experiment without a lot of facilities or some sponsorship for a research project. People have been publishing papers on their own for years now and unless you want to do some large-scale research project, you can work with limited resources. And who knows, maybe this idea of yours can morph into a business product or service that can be a data science start-up. It doesn’t hurt to try! A good tool for doing data science research is Julia, particularly through the Jupyter IDE. You can learn more about the language through the corresponding website, while my book on it can be a great resource for delving into it deeper. Note that the book was written for an earlier version of the language so the code may not be compatible with the latest version (v. 1.0) of Julia. Cheers! Introducing the Trinary Curve: A Novel Heuristic for Artificial Intelligence Data Science Systems11/5/2018 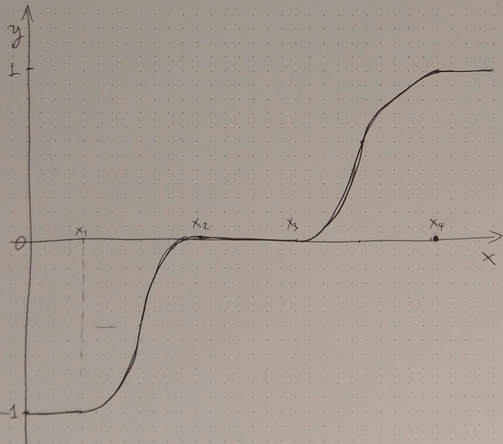 Trinary Logic is not something new. It’s been around for decades, though it was more of a mathematical / high-level framework. I should know, as I did my Masters thesis on this subject and how it applies to GIS. I even wrote code implementing the corresponding model I came up with, though in today’s programming world it seems like legacy code... Anyway, bottom line is that Trinary Logic is useful and could have a place in modern Information Systems, including data analytics projects. The question is, could it be applicable to A.I. too? The answer is, as usual, “it depends.” Trinary Logic on its own is quite limited and unless you are familiar with its 700+ gates, it may be like any novel idea: interesting but not exactly something worth delving into. After all, just like any system of reasoning, Trinary Logic is meaningless without an in-depth understanding of its key contribution to the thorny issue we always tackle through reasoning: handling uncertainty effectively. Uncertainty, oftentimes modeled as noise or randomness (depending on who you ask), is everywhere. Since we cannot eliminate it without damaging the signal too, we find ways to cope with it. Trinary Logic offers an interesting way of doing that through the 3rd value of its variables, namely the “indifferent” state. Something can be True, False, or Indifferent, the latter being something in-between. These are the states of those intermediate values in the membership functions of fuzzy variables, in Fuzzy Logic. The latter is a well-known and quite established A.I. framework with lots of applications in data science. Do you see where I’m going with this? So Trinary Logic is a framework for reasoning, much like Fuzzy Logic, but the latter is an A.I. framework too, so Trinary Logic is A.I. also, right? Well, no. Trinary Logic is a mathematical construct, so unless it is applied to A.I. programmatically, and as a well-defined process, it is yet another concept that can’t even fetch an academic publication! But if it were to manifest as a heuristic of sorts and add value to a process in the A.I. sphere, things would be different. Enter the Trinary Curve, a heuristic (or meta-heuristic, depending on how you use it) that encapsulates Trinary Logic in a simple yet not simplistic way, turning an input signal into something that an A.I. agent can understand and work with. Namely, it can engineer a new variable in the [-1, 1] interval (notice the closed brackets in this case), that enables the corresponding module to have the in-between state of uncertainty more evident. As a result, the A.I. agent is allowed to be unsure about something and examine it more closely, given the right architecture, instead of working with what it has and hope for the best. Note that the Trinary Curve can be customized, while its output can be normalized to a different interval (always closed) if needed. The Trinary Curve is differentiatable throughout the space it is defined, while it’s easy to use programmatically (at least in Julia). Perhaps the Trinary Curve is a novelty and an A.I. system can evolve adequately without it. However, it is something worth considering, instead of just experimenting with the countable parameters of existing A.I. systems solely. After all, Trinary Logic is compatible with existing A.I. frameworks so if it’s not utilized, it’s primarily because of some people’s unwillingness to think outside the box, and that’s something that doesn’t have any uncertainty about it... |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed