 Lately, I’ve been thinking a lot about what information is in a data science context, partly because of a couple of projects I’m involved in, and partly because that’s what I enjoy thinking about in my leisure time. After all, there are people who care about data science in a deeper way, as it’s more than a profession for them, something that commands a certain level of dedication that others may not comprehend. As I’m one of those people, I can attest to the unique beauty of the field and the qualities of it that keep it evergreen and ever-interesting. For the longest time, I was under the impression that it’s the data points or the features that contain the information in a dataset. After all, that’s what most data science sources imply and something that makes some intuitive sense. However, lately I’ve experimented with new algorithms that can generate new data points and new features, while others manage to reduce the number of data points without information loss (aka intelligent sampling) or summarize the same information in a smaller number of features through the use of usually non-linear combinations of the original features (aka feature fusion). In all these cases, there isn’t any new information generated and there isn’t any significant information loss. What’s more, if you can effectively replace the original dataset with synthetic data, without losing any information then the claim that information is basically the original data doesn’t hold any water. In other words, information exists with or without the data at hand, since the same information can be expressed oftentimes more eloquently with a more succinct set of data points or features. Much like the essence of an ice cube is not the exact molecules of the water in it, but the fact that it consists of water and has a certain shape, dictated by the ice cube tray mold. From all this, it follows that what we need is an information-rich dataset, i.e. a dataset that contains useful information without excessive data points or excessive features. Of course, it’s not always easy to perform the transformations required to accomplish this, but it is feasible and most modern A.I. systems are proof of that. Whether, however, this black box approach is the most effective way to accomplish this information distillation is something that needs to be investigated. In my view, looking into this sort of matters and having this perspective is far more important than all the technical know-how about the latest and greatest machine learning system, know-how that is oftentimes superficial when not accompanied by the data science mindset. The latter is something super important which however cannot be described in a simple blog article. I’ve written a book trying to explain it and even that may not have done it justice. Anyway, pondering about these things may seem a bit philosophical, but if this pondering is transformed into concrete and actionable insights that can help improve existing data science methods or spawn new ones, then it’s probably more than just theoretical. Perhaps it’s this pondering that help keeps data science fresh in our minds, preventing it from becoming a mechanical process void of any life and inspiration. After all, just because many people have forgotten about what lured them to data science, it doesn’t mean that this is the only course of action. Someone can practice data science and still be enthusiastic about it while maintaining a sense of creative curiosity about the subject. It’s all a matter of perspective...
0 Comments
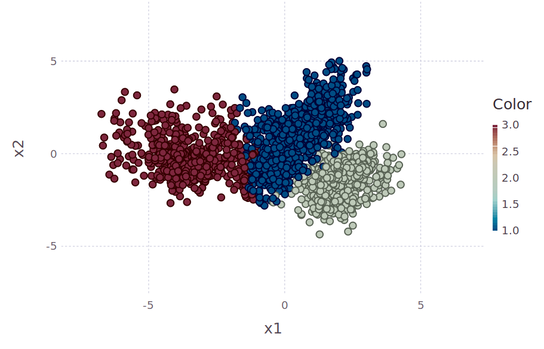 Short answer: Nope! Longer answer: clustering can be a simple deterministic problem, given that you figure out the optimal centroids to start with. But isn’t the latter the solution of a stochastic process though? Again, nope. You can meander around the feature space like a gambler, hoping to find some points that can yield a good solution, or you can tackle the whole problem scientifically. To do that, however, you have to forget everything you know about clustering and even basic statistics, since the latter are inherently limited and frankly, somewhat irrelevant to proper clustering.
Finding the optimal clusters is a two-fold problem: 1. you need to figure out which solutions make sense for the data (i.e. a good value for K), and 2. figure out these solutions in a methodical and robust manner. The former has been resolved as a problem and it’s fairly trivial. Vincent Granville talked about it in his blog, many years ago and since he is better at explaining things than I am, I’m not going to bother with that part at all. My solution to it is a bit different but it’s still heuristics-based. The 2nd part of the problem is also the more challenging one since it’s been something many people have been pursuing a while now, without much success (unless you count the super slow method of DBSCAN, with more parameters than letters in its name, as a viable solution). To find the optimal centroids, you need to take into account two things, the density of each centroid and the distances of each centroid to the other ones. Then you need to combine the two in a single metric, with you need to maximize. Each one of these problems seems fairly trivial, but something that many people don’t realize is that in practice, it’s very very hard, especially if you have multi-dimensional data (where conventional distance metrics fail) and lots of it (making the density calculations a major pain). Fortunately, I found a solution to both of these problems using 1. a new kind of distance metric, that yields a higher U value (this is the heuristic used to evaluate distance metrics in higher dimensional space), though with an inevitable compromise, and 2. a far more efficient way of calculating densities. The aforementioned compromise is that this metric cannot guarantee that the triangular inequality holds, but then again, this is not something you need for clustering anyway. As long as the clustering algo converges, you are fine. Preliminary results of this new clustering method show that it’s fairly quick (even though it searches through various values of K to find the optimum one) and computationally light. What’s more, it is designed to be fairly scalable, something that I’ll be experimenting with in the weeks to come. The reason for the scalability is that it doesn’t calculate the density of each data point, but of certain regions of the dataset only. Finding these regions is the hardest part, but you only need to do that once, before you start playing around with K values. Anyway, I’d love to go into detail about the method but the math I use is different to anything you’ve seen and beyond what is considered canon. Then again, some problems need new math to be solved and perhaps clustering is one of them. Whatever the case, this is just one of the numerous applications of this new framework of data analysis, which I call AAF (alternative analytics framework), a project I’ve been working on for more than 10 years now. More on that in the coming months.  Someone may wonder why would someone write a technical book these days, especially when the earnings of such an endeavor are small and getting smaller. I wondered about the same thing once until eventually, I came to realize some key reasons why such an endeavor is indeed worthwhile, particularly in the Data Science area. I’d like to share with you here the most important of these reasons (benefits), knowing fully well that these are just my own insights and that you’d be able to find your own ones, should you ever consider writing a technical book. First of all, when you discover something, even if it’s not entirely new, the natural next step is to try to share this with others, be it to advance your career, personal branding, or for whatever other reason drives you. If you are serious about this task, you’d want to make sure that whatever you deliver has a certain quality standard, so writing a book on the topic could help you accomplish that. If you are more inclined to use film as your medium, you may decide to go with a video instead, but that would require a longer time and sufficiently more expertise. So, a technical book would be a more viable option, especially if what you have to say can have enough commercial value to attract a publisher. You as an author may not be motivated by the royalties you’ll receive from this project, but no publisher would publish something that isn’t going to pay for the paper or digital storage it is going to need. Also, through writing such a book you realize what you don’t know and develop a more balanced approach to the whole subject since you are more aware of what’s out there. The arrogance you may have harbored as a newcomer will gradually give way to humility and a deeper appreciation of the field, as the research required to write this book is bound to cultivate in you. Besides, even the stuff you may know well, you may realize that you may not be able to express comprehensibly, something that the editor will be more than happy to let you know! So, your development as a professional in this field will be (at least) two-fold: related to the knowledge of subtle aspects of the field and related to your ability to express all that effectively and eloquently. Finally, writing a technical book, particularly one that is marketed professionally by a publisher, enables your thoughts to cross lots of borders, reaching out to people you wouldn’t normally find on your own. This will expose you to a larger variety of feedback for your work that can help you grow further as a professional. Not all of the feedback is going to be useful, but at least some of it is bound to be. Besides, the people who would normally read your work are likely to be people who have valued it enough to pay for it beforehand, be it through the publisher or through a subscription to a technical knowledge platform. Either way, they would most likely be people who are driven by genuine care about the subject, not just curiosity. I could go on about this for a while, perhaps even write a book on this topic! However, as I respect your time, I’d leave it to this. What other benefits of writing a technical book can you think of? Do they justify to you the undertaking of such a project?  Puzzles, especially programming related ones, can be very useful to hone one’s problem-solving skills. This has been known for a while among coders, who often have to come up with their own solutions to problems that lend themselves to analytical solutions. Since data science often involves similar situations, it is useful to have this kind of experiences, albeit in moderation. Programming puzzles often involve math problems, many of which require a lot of specialized knowledge to solve. This sort of problems, may not be that useful since it’s unlikely that you’ll ever need that knowledge in data science or any other applied field. Number theory, for example, although very interesting, has little to do with hands-on problems like the ones we are asked to solve in a data science setting. The kind of problems that benefit a data scientist the most are the ones where you need to come up with a clever algorithm as well as do some resource management. It’s easy to think of the computer as a system of infinite resources but that’s not the case. Even in the case of the cloud, where resource limitations are more lenient, you still have to pay for them, so it’s unwise to use them nilly-willy unless you have no other choice. Fortunately, there are lots of places on the web where you can find some good programming challenges for you. I find that the ones that are not language-specific are the best ones since they focus on the algorithms, rather than the technique. Solving programming puzzles won’t make you a data scientist for sure, but if you are new to coding or if you can use coding to express your problem-solving creativity, that’s definitely something worth exploring. Always remember though that being able to handle a dataset and build a robust model is always more useful, so budget your time accordingly.  With all the talk about Data Science and A.I., it’s easy to forget about the person doing all this and how his awareness grows as he gets more involved in the field of data science. What’s more, all those gurus at the social media will tell you anything about data science except this sort of stuff, since they prefer to have you as a dependent follower rather than an autonomous individual making his own way as a data scientist. So, as you enter the field of data science, you are naturally focused on its applications and the tangible benefits of it. As a professional in this field, you may care about the high salary such a vocation entails or the cool stuff you may build, using data science methods. Everything else seems like something you have to put up with in order to arrive at this place where you can reap the fruits of your data science related efforts. It’s usually at this level of awareness that you see people complain about the field as being too hard, or not engaging enough after a while. Still, this level is important because it often provides you with a strong incentive to continue learning about this field, growing more aware of it. The second level of data science awareness involves a deeper understanding of it and an appreciation of its various tools, methods, and algorithms. People who dwell in this level of awareness either come from academia or end up spending a lot of time in academic endeavors, while in the worst case, they become fanatics of this or the other technology, seeing all others as inferior, just like the people who prefer them. The same goes with the methods involved since there are data scientists who swear by the models they use and wouldn’t use any other ones unless they absolutely had to. This is the level where most people end up with since it’s quite challenging to transcend it, especially on your own. Finally, when you reach the third level of data science awareness, you are more interested in the data and the possibilities it offers. You have a solid understanding of most of the methods used and can see beyond them since they all seem like instances of the same thing. Your interest in data engineering grows and you become more comfortable with processes that are either esoteric or mundane, for most people. Heuristics seem far more interesting, while you begin to question things that others take for granted, regarding how data should be used. The best part is that you can see through the truisms (and other useless information) of the various “experts” in the social media and value your experience and intuition more than what you may read in this or the other book on this subject. It’s fairly easy to figure out which level you are in, in your data science journey. Most importantly, it doesn’t matter as much as being aware of it and making an effort to move on, going deeper into the field. Because, just like other aspects of science, data science can be a path of sorts, rather than just the superficial field of work that many people make it appear. So, if you want to find meaning in all this, it’s really up to you! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed