 Structured Query Language, or SQL for short, is a powerful database language geared toward structure data. As its name suggests, SQL is adept at querying databases to acquire the data you need, in a useful format. However, it includes commands that involve the creation or alteration of databases so that they can fit the requirements of your data architectural model. SQL is essential for both data scientists and other data professionals. Let's look into it more, along with its various variants. Although the tasks performed by SQL (when it comes to data wrangling), you can perform with other programming languages too, its efficiency and relative ease of use make it a great tool. Perhaps that's why it's so popular, with many variants of it. The most well-known one, MySQL, specializes in web databases, though it can also be used for other applications. Other variants, such as PostgreSQL, are mostly geared towards the industry. All this may seem somewhat overwhelming, considering that each variant has its peculiarities. However, all of these SQL variations are similar in their structure, and it doesn't take long to get accustomed to each one of them if you already know another SQL variant. Yet, all of the SQL databases tend to be limited in the structure of the data. In other words, if your data is semi-structured (i.e., there are elements of structure in it but it's not tabular data), you need a different kind of database. Namely, you require a NoSQL (i.e., Not Only SQL) one. Databases like MongoDB, MariaDB, etc. are of this category. Note that NoSQL databases have many commands in common with SQL, but they are geared toward a different organization of column-based data. This characteristic enables them to be faster and able to handle dictionary-like structures. Naturally, there are plenty more kinds of SQL variants, primarily under the NoSQL paradigm. However, beyond these SQL-like databases, there are also those related to graphs, such as GraphQL. These specialized systems are geared towards storing and querying data in graph format, which is increasingly common nowadays. All these database-related matters are under the umbrella of data modeling, a field geared towards organizing data flows, optimizing the ways this data is stored, and ensuring that all the people involved (the consumers of this data) are on the same page. Although this is not strictly related to the data science field, it's imperative, plus knowing about it, enables better communication between the data architects (aka data modelers) and us. You can learn more about SQL and other data modeling topics through the Technics Publications website. There, you can use the coupon code DSML for a 20% discount on all the titles you purchase. Note that this code may not apply to all the video material you'll find there, such as the courses offered. However, you can use it to get a discounted price for all the books. I hope you find this useful. Cheers!
0 Comments
As most of you probably know, Apache Spark is a big data platform (a data governance system), geared towards large-scale data. Employing HDFS (Hadoop Distributed File System), it handles data on a computer cluster (or a cloud), processing it and even building some basic predictive models with it (including Graph-based ones). Written in Scala, it is compatible with two more programming language: Java and Python. However, most people use it simply because it’s much faster than Hadoop, up to 100 times faster, while it offers a more intuitive and versatile toolbox to its users. Spark fills a unique need in data science: handling big data quickly, in an integrated ecosystem. If you also know Scala, that’s a big plus because you can write your own scripts to execute in this ecosystem, without having to rely on other data professionals. Also, Spark has a large enough community and resources, making it a safe option for data science work, while there are companies like DataBricks which are committed to maintaining it and evolving it. The fact that there is even a conference on Spark (and AI) by the aforementioned company adds to that. OK, but what about Spark alternatives? After all, Spark can’t be the only piece of software that does this set of tasks well, right? Well, there is also Apache Storm, a big data tool created by Twitter. One advantage it has over Apache Spark is that it can run on any programming language. Also, it’s fault-tolerant and fairly easy to use. What’s more, there is IBM Infosphere Streams, which specializes in stream processing. Also, the fact that it has an IDE based on the Eclipse one, makes it easier to work with. Although Storm is fast, this one is even faster, while it can also fuse multiple streams together. This can aid your analysis in terms of insights made available. This big data tool works with the Streams Processing Language (SPL) and comes with several auxiliary programs for monitoring and more effective administration. Additionally, there is Apache Flink, another high-speed and fault-tolerant alternative to Spark (like Apache Storm). Naturally, it’s compatible with a variety of similar tools, like Storm as well as Hadoop’s MapReduce. Because of its design, which focuses on a variety of optimizations and the use of iterative transformations, it’s a great low-latency alternative to Spark. Finally, there is TIBCO StreamBase, which is designed with real-time data analytics in mind. The niche of this software is that it creates a live data mart communicating with the users through push notifications. Then, they can analyze and create visuals of the data interactively StreamBase appeals also to non-data scientist, through its LiteView Desktop version. Beyond these four alternatives to Apache Spark there exist several ones which are beyond the scope of this article. The idea here is to show that there are other tools out there for this sort of data governance tasks, some of which can be even better than Spark. In any case, it's good to be aware of what's out there and develop a mindset that is not tied to specific software for the tasks at hand. More about all this in my book Data Science Mindset, Methodologies, and Misconceptions, which I authored a few years back, yet it remains relevant to this day. Check it out when you have a moment. Cheers!  (the lady in the picture is a metaphor for the "feature" or "set of features" in the dataset at hand)
If data science, a feature is a variable that has been cleaned and processed so that it's ready to use in a model. Most data models are sensitive to their inputs' scale, so most features are normalized before they are useful in these models. Naturally, not all features add value to a model or a data science project in general. That's why we often need to evaluate them, in various ways, before we can proceed with them in our project. Evaluating features is an often essential part of the data engineering phase in the data science pipeline. It involves comparing them with the target variable in a meaningful way to assess how well they can predict it. This assessment can be done by either evaluating the features individually or in combination. Of these approaches, the first one is more scalable and more manageable to perform. Since there are inevitable correlations among the features, the individual approach may not paint the right picture, since two "good" features may not work well together since they depict the same information. That's why evaluating a group of features is often better, even if it's not always practical. Note that the usefulness of a feature usually depends on the problem at hand. So, we need to be clear as to what we are trying to predict. Also, even though a good feature is bound to be useful in all the data models involved, it's not utilized the same way. So, having some intimate understanding of the models can be immensely useful for figuring out what features to use. What's more, the form of the feature is also essential in its value. If a continuous feature is used as is, its information is utilized differently than if it is binarized, for example. Sometimes, the latter is a good idea as we don't always care for all the information the feature may contain. However, it's best not to binarize continuous features haphazardly since that may limit the data models' performance. The methodology involved also plays a vital role in the feature evaluation. For example, if you perform classification, you need to assess your features differently than if you are performing regression. Also, note that features play a different role altogether when performing clustering as the target variable doesn't participate (or it's missing altogether). As a result of all this, evaluating features is crucial for dimensionality reduction, a methodology closely linked to it and usually follows it. You can learn more about features and their use in predictive models in my latest book, Julia for Machine Learning. This book explores the value of data from a machine learning perspective, with hands-on application of this know-how on various data science projects. Feature evaluation is one aspect of all this, which I describe through the use of specialized heuristics. Check out this book when you have a chance and learn more about this essential subject!  As we talked about in the previous article, open-mindedness is our ability to view things from a wider perspective, with as few assumptions as humanly possible. We saw how this concept is relevant and useful in a data science project. But how does open-mindedness benefit A.I. in practice? Just like in the data science case, learning A.I. also stands to benefit from open-mindedness. This is quite obvious, considering how mediocre a job most of the educators of A.I. do and the number of con artists in this field. Keeping an open mind about A.I. and learning it properly are essential for becoming a good A.I. practitioner, particularly one who can see beyond ANNs. After all, there is much more to A.I. than this graph-based family of systems and no matter how good these are, there are always other things to learn such as AI-based optimization methods and Fuzzy Logic systems. Researching A.I. is probably that case where open-mindedness not only shines but it’s also more or less essential. This is something harder and harder to do since everything in the A.I. research space seems to be geared towards either ANNs or NLP (usually ANN-based). It’s quite rare to find any originality in the A.I. research these days, though a lot of the stochastic optimization systems (which are AI-based optimizers) have some pretty good ideas behind them. Also, some AI-based dimensionality reduction methods are quite interesting too. Open-mindedness can also be applied when exploring the limits of an A.I. system. This is particularly important in a project since it’s easy to get stuck with the impression that an A.I. system is the best choice, even if it isn’t. Open-mindedness allows you to view other options and consider the limitations of an A.I. system more realistically, making more pragmatic choices. Finally, open-mindedness as an attitude can help us have a more humble view of things when it comes to A.I. After all, this is a fairly new field (compared to data analytics, for example) and has a lot of room for improvement, something many A.I. practitioners tend to forget. Perhaps that's why many such practitioners are still comparing A.I. models with Stats one (the equivalent of comparing a sports car with a toy car), instead of looking at the various non-AI-based machine learning options, which can be viable alternatives to the project at hand. In any case, you can learn more about A.I. from an open-minded perspective through a book I have co-authored a couple of years ago. Namely, the AI for Data Science book from Technics Publications covers this subject and provides a variety of stimuli for researching it properly. Although the term open-mindedness is not used per se in this book, it does delve into the way of thinking of an AI-oriented data scientist. So, check it out when you have the chance. Cheers!  Dimensionality reduction is the methodology involving the coding of a dataset's information into a new one consisting of a smaller number of features. This approach tries to address the curse of dimensionality, which involves the difficulty of handling data that comprises too many variables. This article will explore a primary taxonomy of dimensionality reduction and how this methodology ties into other aspects of data science work, particularly machine learning. There are several types of dimensionality reduction out there. You can split them into two general categories: methods involving the feature data in combination with the target variable, and methods involving the feature data only. Additionally, the second category methods can be split into those involving projection techniques (e.g., PCA, ICA, LDA, Factor Analysis, etc.), and those based on machine learning algorithms (e.g., Isomap, Self-organizing maps, Autoencoders, etc.). You can see a diagram of this classification below. 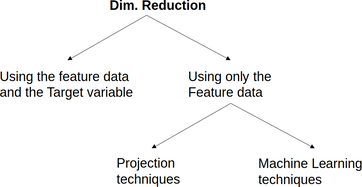 The most noteworthy dimensionality reduction methods used today are Principle Components Analysis (PCA), Uniform Manifold Approximation and Projection (UMAP), and Autoencoders. However, in cases where the target variable is used, feature selection is a great alternative. Note that you can always combine different dimensionality reduction methods for even better results. This strategy works particularly well when the methods come from different families. It's important to remember that dimensionality reduction is not always required, no matter how powerful it is as a methodology. Sometimes the original features are good enough, while the project requires a transparent model, something not always feasible when dimensionality reduction is involved. What's more, dimensionality reduction always involves some loss of information, so sometimes it's not a good idea. It's crucial to gauge all the pros and cons of applying such an approach before doing so, since it may sometimes not be worth it because of the compromises you have to make. Many of the datasets found in data science projects today involve variables that are somehow related to each other, though this correlation is a non-linear one. That's why many traditional dimensionality reduction methods may not be as good, especially if the datasets are complex. That's why machine learning methods are more prevalent in cases like this and why there is a lot of research in this area. What's more, these dimensionality reduction methods integrate well with other machine learning techniques (e.g., in the case of autoencoders). This fact makes them a useful addition to a data science pipeline. In my book Julia for Machine Learning, I dedicate a whole chapter in dimensionality reduction, focusing on these relatively advanced methods. Additionally, I cover other machine learning techniques, including several predictive models, heuristics, etc. So, if you want to learn more about this subject, check it out when you have the chance. Cheers!  In a nut-shell, open-mindedness is our ability to view things from a wider perspective, with as few assumptions as humanly possible. It’s very much like the “beginner’s mind” concept which I’ve talked about in previous posts. I’ve also written an article about the value of open-mindedness on this blog before, a post that remains somewhat popular to this day. That’s why I decided to go deeper on this topic, which is both evergreen and practical. The first scenario where open-mindedness becomes practically useful in data science is when you are learning about it. For example, you can learn the craft like some people do, blindly following some course/video/book, or you can be more open-minded about it and learn through a series of case studies, Q&A sessions with a mentor, and your own research into the topic. Having an active role in learning about the field is crucial if you want to have an open-minded approach to it. The same goes for taking initiative in practice projects and such. Of course, open-mindedness has other advantages in data science work. For example, when finding a solution in a data science project, you may consider different – somewhat unconventional – approaches to it. You may try all the standard methods, but also consider different combinations of models, or variants of them. Such an approach is bound to be beneficial in complex problems that cannot be easily tackled with conventional models. What’s more, open-mindedness can be applied to data handling too. For example, you can consider different ways of managing your features, alternative ways of combining them, and even different options for creating new features. All this can enable you to use more refined data potentially, providing you with an edge in your data engineering work. Let’s not forget that the latter constitutes the bulk of most data scientists’ workload. As such, this part of the pipeline conceals the largest potential for improvement. Communicating with data science project stakeholders is another aspect of open-mindedness, perhaps one that deserves the most attention. After all, it’s not always easy to convey one’s insights and methodology to the other stakeholders of a data science project. Sometimes you need to find the right angle and the right justifications, which may not be just technical. That’s why open-mindedness here can shine and help bring about new iterations of the data science pipeline, for a given project. Also, it can bring about spin-off data science projects, related to the original one. Although this topic is vast, you can learn more about open-mindedness and data science through one of my books. Namely, the Data Science Mindset, Methodologies, and Misconceptions book that I authored a few years ago covers such topics. Although the term open-mindedness is not used per se, the book delves into the way of thinking of a data scientist and how qualities like creativity (which is very closely related to open-mindedness) come into play. So, check it out when you have the chance. Cheers!  Personally Identifiable Information, or PII for short, is an essential aspect of data science work today. It involves sensitive data that can compromise the identity of at least some of the people involved in a dataset (e.g., someone's name, financial data, address, phone number, etc.). PII is particularly important today as it's protected by law in many countries, and any violation of this sort of data can fetch huge fines. What's more, PII is often essential in data science projects as it carries useful information that can bring about a sense of personalization to the data products developed. Due to various factors, such as using multiple data streams, datasets used in data science today are full of PII. Note that PII can result from a combination of variables since there isn't an infinite amount of people. As a result, given enough information-rich variables, you can predict several PII variables with reasonable accuracy. This ability to predict PII makes the problem even more severe since PII can be a serious liability if it leaks. As there is plenty of it in modern datasets, the risk of this happening grows with the more data you gather for your data science project. Of course, you could remove PII from your dataset, but it's not always a good option. After all, much of this PII is useful information that can help with the models built. So, even if you can eliminate certain variables, the bulk of PII will need to be retained for the models at hand to be useful and a value-add to your data science project. As for obscuring the PII variables (e.g., through a method like PCA), this is also a valid option. However, with it, any chance of transparency in your models goes out the window. Fortunately, you can protect PII with various cybersecurity methods, without compromising your models' performance or transparency. Encryption, for example, is one of the most widely used techniques to keep data secure as it's turned into gibberish when not in use. In some cases, even in that gibberish state, you can perform some operations for additional security. However, in most cases, the protection is there for the time the data is in transit, which is when it's also the most vulnerable. Since nowadays the use of the cloud for both storing and processing data is commonplace, the risk of exposing PII is more significant than ever. Fortunately, it's not too difficult to have security even in these situations, as long as the cloud provider offers this protection level. It just needs to have that in the platform it uses and in all the network connections involved. Hostkey is a Dutch company providing cloud services, targeted towards data science professionals. Just like most modern cloud providers, it offers high-quality cybersecurity for all the data handled. At the same time, if you are super serious about this matter, you can also lease a dedicated server from it. Additionally, Hostkey offers GPU servers, which are a bigger bang for your buck when it comes to high-performance data models, such as deep learning ones. So, check out this cloud company and see how you can benefit from its services. Cheers! Data visualization is a key aspect of data science work as it illustrates insights and findings very efficiently and effortlessly. It is an intriguing methodology that’s used in every data science and data analytics project at one point or another. However, many people today, particularly those in the data analytics field, entertain the idea that it’s best to perform this sort of task using Tableau, a paid data visualization tool. Note that there are several options when it comes to data visualization, many of which are either free or better-priced than Tableau. The latter appears to be popular as it was one of the first such software to become available. However, this doesn’t mean that it’s a good option, particularly for data scientists. So, what other options are there for data visualization tasks? For starters, every programming language (and even a math platform) has a set of visualization libraries. These make it possible to create plots on the fly, customizing them to your heart's content, and being able to replicate the whole process easily if needed through the corresponding script. Also, they are regularly updated and have a community around them, making it easy to seek help and advice on your data visualization tasks. Also, there are other data visualization programs, much more affordable than Tableau, which are also compatible with Linux-based operating systems. Tableau may be fine for Windows and macOS, but when it comes to GNU/Linux, it leaves you hanging. Let's shift gears a bit and look at the business aspect of data science work. In a data science team, there are various costs that can diminish its chances of being successful. After all, just like other parts of the organization, a data science team has a budget to work with. This budget has to cover a variety of tasks, from data governance costs (e.g. a big data system for storing and querying data), data analytics costs (e.g. cloud computing resources), and of course the salaries and bonuses of the people involved. Adding yet another cost to all this, for a Tableau subscription, doesn’t make much sense, especially considering how challenging it can be for a data science project to yield profits in the beginning. Also, considering that there are free alternatives for data visualization tasks, it makes more sense to invest in them (i.e. learn them instead). So what are some better ways to invest money for data science work? For starters, you can invest in the education of your team (e.g. through a course or a good book). Even if they are all adept in the essentials of data science work, they can always get up to speed on some new technology or methodology that can be used in some of their projects. Also, you can invest in additional equipment, upgrading the computers involved, and even getting more cloud resources. Finally, you can always invest in specialized software that is related to your domain or hire consultants to help out when needed. A few years ago, as I was writing the Data Science Mindset, Methodologies, and Misconceptions book, I mentioned Tableau as a data visualization alternative. However, I didn't look at the bigger picture of data science work from the organization's perspective. The latter is something my co-author and I did in our book Data Scientist Bedside Manner, which I'd encourage you to buy. In it we cover a variety of topics related to data science work and how there are better ways to invest resources for it, building towards a more successful pipeline. Cheers!  Natural Language Processing (NLP) is an essential part of data science today. Although its focus is on analyzing text, its benefits go beyond this and cover cases to improve an existing text. In a world where written communication is becoming more prevalent, this is a powerful aspect of the field. In this article, we'll look into all that through a practical and not-too-technical perspective. Let’s start with what NLP is. NLP is a specialized field on the overlap of data science and A.I., geared towards analyzing text data, mainly text forming complete sentences. NLP aims to understand things like the tone of the text, its sentiment polarity, and its intention. Specialized aspects of NLP focus on understanding the meaning of the text to provide more in-depth insights regarding it. This kind of NLP is under the Natural Language Understanding (NLU) umbrella, and it's a more advanced aspect of NLP. Other advanced aspects of NLP involve creating new text based on a given text or sometimes even just a prompt. A given text can improve in various ways. Apart from the apparent corrections (e.g., typos and incomplete sentences), it can be made clearer, less wordy, and more elegant. Changes like these involve improving the vocabulary involved as well as the sentence structure. To automate this process, some NLP work is necessary. Additionally, the user's feedback can be incorporated to enhance the text further, mitigating any inaccurate improvements. What's more, additional improvements from a human editor can be incorporated into the NLP model, even if that editor is the original text's creator. In any case, this is a long process that involves considering various factors, such as the audience the text is targeted at, the objective of the text, etc. That's why to improve a text, you need a systematic and sophisticated approach, one that is versatile enough to adapt and evolve. In short, you need an A.I. system designed for this specific task. All this may seem like a lot of work for just making a piece of text look nicer, perhaps a bit of an overkill. However, considering the effects of this work, it may be an excellent investment. In particular, by providing suitable corrections to the user (who is also the original text's creator), the latter can improve his writing style and mastery of the language. This is particularly the case when the user is not well versed in linguistics and makes many mistakes. So, this simple NLP pipeline, which is also mostly self-sufficient, can improve the user also, all while enabling her to spend her time on other, more challenging tasks. What's more, a good text can help communication among people, effectively making this NLP work an excellent time-saver for everyone involved in this text. But where can someone find such an NLP system that can improve a given text and the person who wrote it, eventually? Well, Grammarly has you covered in that regard. This company has developed a powerful A.I. system that does just that, all while having an intuitive and easy-to-use interface that integrates well with your web browser. Having used this system myself for over a year now, I can attest to its usefulness and insightful feedback. Check it out when you have the chance. Cheers! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed