 It's been over two years since the Compressed Data Format (CDF) made its debut, making storing data files in Julia a breeze. Not only does it handle various types of data easily, but it also allows for comments and any other stuff you'd like to include in your data file before sharing it with other Julia users. The native data file formats the language has been okay, but when it comes to larger datasets, they fall short. Also, conventional data file formats like CSV and JSON, although mature and easy to use, tend to be bulky as the number of data points/variables grows. CDF remedies all that by employing a powerful compression algorithm on the data at hand. The CDF script consists of a series of functions while it leverages another script for handling binary files. Because if you want to do anything meaningful with files, you need to go down to the 1s and 0s level. The conventional IO handling Julia offers is fine, but it's limited to text files mainly. However, the language has binary file capabilities, which are leveraged and simplified in the binfiles.jl script that CDF relies on for its IO operations. That script has just two functions, one for reading binary files and one for writing them. Naturally, everything on that level is expressed in Int8 vectors, as a data stream related to a binary file is a series of bytes, often in the form of an 8-bit number (ranging between -128 and 127, inclusive. So, if you wish to delve into this sort of file operation, make sure you familiarize yourself with this data structure. Fortunately, the CDF script is more high-level than the binfiles.jl one. Still, it needs to deal with binary files at one point, so it has to translate the data streams it handles into Int8 vectors. To make the most of the bandwidth your machine has, it breaks down the whole process into these distinct phases, which you can view in Fig. 1: 1. Turning the data into a Dict object if it's not in that form already. 2. Turning the dictionary into a text stream (string variable). 3. Compressing the text stream. 4. Passing the compressed data into the binary files function to read/write the corresponding files. 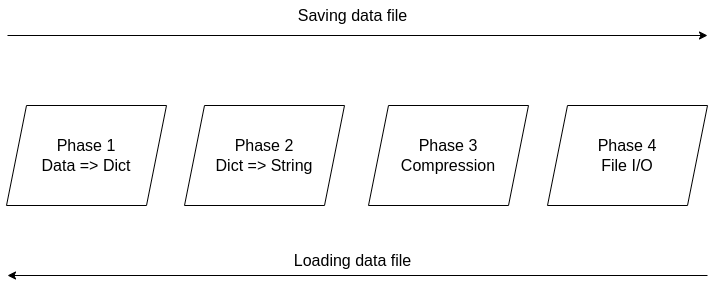 Figure 1. The four phases of the CDF file creation/loading process.
The handling of the binary files takes place using the binfiles.jl script, as mentioned previously, so we won't cover it in depth in this article. For the remaining phases, let's start from the easy part: compression (phase 3). Here the CodecZlib package is used, which contains a bunch of compression algorithms. The CDF script leverages the Deflate algorithm due to its speed and efficiency. Naturally, as everything is already in the form of a string variable by that stage utilizing the compression algorithm is pretty straightforward. Now the problem becomes turning everything into a string (phase 2). Although this seems straightforward, doing that all while ensuring that the whole process is easily reversible can be challenging. Fortunately, if everything is already in dictionary form, it's not that hard. After all, a dictionary comprises various keys which correspond to certain values, all of which can be retrieved through the keys() and values() functions of the dictionary class. So, handling a dictionary isn't that hard, and it can be done methodically. Of course, dumping the dictionary's contents into a string file isn't a great idea since the various key-value pairs need to be separated. One way to do this, which is also the way CDF is written, involves putting all the keys together in the beginning and then all the values corresponding to these keys. Each key is separated from the next using a space (the keys correspond to variable names, so they tend to be void of spaces). From that point on, for all pieces of data that need to be connected in that output string, a special character is used, one which doesn't come into play in data files. This way, it's easy to split the string between the keys and the values, using that special character as a separator. The same goes for all the different values that are added to the string. Since they might contain spaces in them, we use the special character to separate each from the next. Following that, we also store the types of these values so that we can reconstruct the original contents of the dictionary. The types are contained in a separate array and are separated by spaces. To make this information more easily accessible, we position it at the end of the string, separated from the values part using the special character. To create the dictionary (phase 1), we merely need to put the variable at hand into an empty dictionary, with the variable name as its key and its contents as its value (this is done automatically with the corresponding function of the CDF script). This process is a bit more cumbersome a process as it requires the user to input both the variable and its name, while it’s limited to a single variable (e.g., a matrix of a dataset). That’s why it’s generally better to have all the data available as a dictionary before using the CDF script. This way, if you need to add any comments to the data, you can do so by adding another key-value pair to the dictionary where the data lives. The data types supported by CDF at this stage are String, Char, Real, Float64, Int64, and Array of numbers of bits. In future versions of CDF, it may also be able to handle more complex scenarios, such as DataFrames, nested arrays, arrays of strings, etc. CDF can be useful for storing models too, with the (hyper)parameters being in a particular part of the dictionary, the operational conditions in another part and some metadata about the training data and the model's tested performance in another part. This way, by loading this CDF file, you can get all the relevant information about the model to use in your project.
0 Comments
|
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed