 In a nutshell, Quantum Computing is the computing paradigm that uses quantum properties in computer systems, such as superposition and quantum tunneling. Experts consider quantum computing quite advanced and the state-of-the-art of computing today, even if the specialized hardware it uses makes it a bit of a niche case study. Despite its numerous merits, quantum computing is not a panacea, even though it is considered relevant in our field, particularly in A.I. This article will explore this relationship, where Q.C. is right now, and where you can access it. Quantum computers' performance is usually measured in Qubits (quantum bits) instead of traditional bits. Each qubit is a quantum particle in superposition and corresponds to the more rudimentary piece of data a quantum computer can handle. Qubits are not easy to maintain, and when they work in tandem, it's quite probable for the superposition to collapse unexpectedly, resulting in errors in the computations involved. So, having a certain number of qubits (the larger, the better) in a computer is quite an accomplishment. Larger numbers enable quantum computer users to tackle more challenging problems, potentially adding more value to the project at hand. Right now, quantum computing is at a stage where the number of qubits they can handle is in the two digits. For example, IBM's quantum machine boasts 65 qubits, although the company has plans for much larger numbers soon (they expect to have a quantum machine with 1000+ qubits by 2023). However, it's important to note that each company uses a somewhat different approach, meaning that the qubits in each computer they produce are not directly comparable to each other. Now, what about the potential disruption in data science and A.I. work due to quantum computing? Well, since our field often involves lots of heavy computations, some of them around NP-hard problems in combinatorics (e.g., selected the optimal set of features from a feature set), it can surely gain from quantum computers. That's not to say, however, that every data science or A.I. project can experience a boost from the Q.C. world. Simpler models and standard ETL work are bound to remain the same while using a quantum machine for them would waste these pricy computational resources. So, it's more likely that a combination of traditional computing and quantum computing will be normal once quantum machines become more commonplace. Additionally, for optimization-related problems, particularly those involving many variables, quantum computing may have a lot to offer. Still, whether it's worth the price is something that needs to be determined on a case-by-case basis. Let’s now look at the various quantum computing vendors out there. For starters, we have Amazon with its AWS Quantum Computing center at Caltech. Microsoft is also a significant player, with its Azure Quantum service, utilizing a specialized language (Q#). IBM is a key player, too, along with D-Wave Systems, the two being the first to develop this technology. Google Research is Alphabet's division for this tech and is now also a player in this area. What's more, there are hardware companies too in this game, such as Intel, Toshiba, and H.P. Naturally, all the companies that have developed their Q.C. product enough to make it available do so via a cloud, since it's much more practical this way. For those who like the cloud but don't have the budget or the project that lends itself to quantum machines, the Hostkey cloud provider relies on conventional computers, including some with GPUs onboard. You can learn more this and other relevant topics to A.I. and data science, though my book A.I. for Data Science: Artificial Intelligence Frameworks and Functionality for Deep Learning, Optimization, and Beyond. In this book, my co-author and I cover various aspects of data science work related to A.I., as well as A.I.-specific topics, such as optimization. What’s more, the book has a hands-on approach to this subject, with lots of code in both Python and Julia. So, check it out when you can. Cheers!
0 Comments
 Like any project in an organization, a data science project needs to have boundaries regarding how many resources are allocated to it. This resource usage translates into a monetary cost that takes the form of a budget. So, even if many professionals in this field are not aware of it, budgeting plays an essential role in every data science project and provides the framework through which it can manifest. Despite its similarities to other projects, data science projects differ in many ways. First of all, its return isn't clear or even guaranteed. A data science team may investigate a dataset for insights or predictive potential, but it may not dig up something worthwhile. The data in a company's databases may be useful for its day-to-day tasks but useless for anything data science-related. It's next to impossible to know if there is anything worthwhile beforehand, so when starting a project, you have to take significant risks. As for the project's time frame, that's also highly uncertain, especially if it's a new project. This uncertainty can veer the project off-course, and the risk of going over-budget is substantial. When creating a budget for a data science project, several factors are considered to mitigate the risk of failure. First of all, you need to have a clear plan of what you expect from the data science team to find. If possible, you could have some ideas as to how you could translate these findings into a value-add, be it through a revenue stream, some improvement in the customer/user experience, or some enhancement in the organization's workflow efficiency. What’s more, it's good to examine a data science project from various perspectives and ensure that the data scientists involved have peace of mind when working on it. It's not just up to them to make it work, since the other stakeholders have a responsibility in it too. For example, the data owners need to do their part and ensure that the data science teams receive all the data it needs promptly. The developers involved need to have sufficient bandwidth to help with any ETL and other project processes. Finally, the business people need to have realistic expectations of what the data science team can deliver and how to leverage their work. Beyond the above factors that you need to consider, some additional considerations are useful to have when creating a budget. For instance, the cost of cloud computing involved is something that can get out of hand quickly, especially if you are not used to working at a particular scale of data. Sometimes it's more effective to have dedicated servers available to you instead of a leasing computing power in a virtual machine. Also, it would make sense to start with a proof-of-concept project to gain a better understanding of the problem at hand before going at it with full force. You can learn more about this, and the other less technical aspects of data science work through one of the books I co-authored relatively recently. Namely, the Data Scientist Bedside Manner book delves into this topic and explores data science from a perspective few people consider. Using information from various sources, including some experienced professionals in the field, provides guidance both for the data-driven manager and the data science professional, bridging the gap between the two. Check it out when you have the chance. Cheers!  Non-Negative Matrix Factorization (NNMF or NMF) is a powerful method used in Recommender Systems, Topic Modeling in NLP, Image analysis, and various other areas. It involves breaking a matrix into a product of two other matrices, having either positive or zero values in them. The idea is to preserve meaning in the components derived since, in some cases, it doesn't make sense to have negative values in them (e.g., in Topic Modeling, you can't have a document with a negative membership to any given topic). NNMF is not an exact science, since it's an NP-hard problem. As a result, we try to find an approximate solution using various tricks. Although some people view NNMF as Stats-based, it is a machine learning technique based on Linear Algebra and Optimization. The math of NNMF is relatively straight-forward, though not something you would do with pen and paper, or even a calculator! There are various approaches to NNMF, involving finding two matrices W and H, such that the norm of the original matrix X minus W*F is minimal, all while W and H being non-negative: 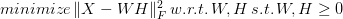 The norm part is the objective function of this minimization problem, by the way. Two common ways to accomplish this are the multiplicative update (gradually approximating W and H, using a particular rule), and the Hierarchical Alternating Least Squares (HALS) method, which attempts to find the columns of W one by one, through.
A common trick for NNMF is to use Singular Value Decomposition (SVD) first to find a rough approximation for W and H and then refine it gradually. Alternatively, we can use regularization to ensure that W and H's elements remain relatively small, resulting in a more stable solution. However, keep in mind that the solutions NNMF yields are approximate and correspond to local minima of the objective function. Fortunately, there are programming libraries that do all the heavy-lifting for us when it comes to NNMF. One such library is the NMF.jl one, in Julia. If you are more of a Python user, you can use the NMF function from the decomposition class of the sklearn package. Both of these libraries are well-documented so getting the hand of them is relatively straight-forward. You can learn more about data science methods like this one in my book, Data Science Mindset, Methodologies, and Misconceptions. In this book, I talk about all kinds of processes and techniques used in data science so that even the non-technical reader can grasp the intuition behind them and gain an understanding and appreciation of them. This book provides several external resources to go more in-depth on these topics and organize how you continue learning about this field, without getting lost in it. So, check it out when you have some time. Cheers!  Text editors are specialized programs that enable you to process text files. Although they are relatively generic, many of these text editors focus on script files, such as those used to store Julia and Python code (pretty much every programming language makes use of text files to store the source code of its scripts). So, modern text editors have evolved enough to pinpoint particular keywords in the script files and highlight them accordingly. This highlighting enables the user to understand the script better and develop a script more efficiently. Many text editors today can help pinpoint potential bugs (programming jargon for mistakes or errors), making the whole process of refining a script easier. In data science work and work related to A.I., text editors are immensely important. They help organize the code, develop it faster and easier, optimize it, and review it. Data science scripts can often get bulky and are often interconnected, meaning that you have to keep track of several script files. Text editors make that more feasible and manageable as a task, while some can provide useful shortcuts to accelerate your workflow. Additionally, some text editors integrate with the programming languages themselves, enabling you to run the code as you develop it while keeping track of your workspace and other useful information. This is what people call an IDE, short for Integrated Development Environment, something essential for any non-trivial data science project. One of the text editors that shine when it comes to data science work is Atom. This fairly minimalist text editor can handle various programming languages, while it also exhibits several plugins that extend its functionality. It's no wonder that it is so widely used by code-oriented professionals, including data scientists. Like most text editors out there, it's cross-platform and intuitive, while it's highly customizable and easy to learn. It's also useful for viewing text files, though you may want to look into more specialized software for huge files. Another text editor that gained popularity recently, particularly among Julia users, is Visual Studio Code (VS Code). This text editor is much like Atom but a bit easier and slicker in its use. It has a smoother interface, while its integration of the terminal is seamless. The debug console it features is also a big plus, along with the other options it provides for trouble-shooting your scripts. Lately, it has become the go-to editor for Julia programmers, something interesting considering how vested the Julia community had been to the Atom editor and its Julia-centric version, Juno. Beyond these two text editors, there are other ones you may want to consider. Sublime Text, for example, is noteworthy, though its full version carries a price tag. In any case, the field of text editors is quite dynamic, so it's good to be on the lookout for newer or newly-revised such software that can facilitate your scripting work. If you want to practice coding for data science and A.I. projects, there are a few books I’ve worked on that I’d recommend. Namely, the two Julia books I've written, as well as the A.I. for Data Science book I've co-authored, are great resources for data science and A.I. related coding. Check them out when you have a moment. Cheers!  Just like other fields, data science has evolved over the past few years. One of the most evident aspects of this evolution is that data scientists are found in teams nowadays. Even consultancies are often team-based, enabling them to undertake a whole project flexibly and efficiently. But how do we build a data science team exactly? First, we need to look at the different types of data scientists and explore the different specialization levels such a professional may have. Nowadays, there are several types of data scientists. The most important of them are the data engineering (delving into low-level tasks, such as ETL and handling any cloud-related operations) and the data modeling expert (usually referred to as just data scientist or machine learning expert when it's more specialized). Additionally, there are the data visualization expert, the data science manager, and the data communicator (a more niche role that's not as widely spread). Of course, depending on the data science area that a data scientist specializes in, there is also the NLP expert, the A.I. expert, etc. So, it's safe to say that the data scientist role is quite diverse these days. Speaking of specialization, that's a topic on its own that plays a role in data science work. The specialist is the most common scenario, whereby a data scientist is really good at one particular task and fairly mediocre in other tasks not related to that task. On the other hand, a generalist is quite decent in various tasks but not particularly good at any specific task. Such a person may be a good team leader, but wouldn't be ideal for tackling a particularly challenging problem. Beyond these two, there is also the versatilist, who is quite good at one (or more) tasks but also quite decent in other tasks. It's like a combination of a specialist and a generalist, making an excellent asset in a team, especially in data science work. So, how do we go about building a data science team? The team's specifics always depend on the project at hand, but in general terms, you can build a team as follows. For starters, you need to get a versatilist or experienced generalist as the team leader. This person can help build the team by finding professionals with a similar working style and cultural fit. Having a second generalist or versatilist may also be useful, depending on the size of the team. Additionally, you can have two or three specialists, one of whom would need to be a data engineer. If your team needs to work with clients directly, you may need to consider having a data communicator. Also, if the team's expected outcomes are more geared towards dashboards and graphics, you may need to have a data visualization expert onboard. Should you wish to learn more about this topic and other organizational aspects of the data science field, you can check out the Data Scientist Bedside Manner book I co-authored last year. This book examines various aspects of data science work, focusing on the non-technical ones and various useful tips as to how you can improve your data science career. Check it out when you have the chance. Cheers!  Ever since machine learning and artificial intelligence (A.I.) became mainstream, there has been a lot of confusion between the two and how they relate to data science. Considering how superficial the mainstream understanding of the subject is, it's no wonder that many people who first learn about data science consider them the same. However, if you are to learn data science in-depth and do something useful with it, it's best to know how to differentiate between the two and know when to use what, for the problem at hand. To disambiguate the two, let’s look at what each one of them is. First all, machine learning is a set of methodologies involving a data-driven approach to data modeling as well as the evaluation of the data at hand. It includes various models like decision trees, support vector machines, etc. as well as a series of heuristics. The latter is used for assessing features or models in a way that's void of any assumptions about the distributions of the data involved. Machine learning sometimes makes use of basic Stats but it is a separate field altogether, part of the core of data science. Some machine learning models are based on A.I. though most of them are not. As for artificial intelligence, it is a field separate from data science altogether. It involves systems that emulate sentient behavior, in various domains. Computer Vision, for example, is a part of A.I. that involves interpreting images (usually captured by a camera or a video stream) to understand what objects are in the vicinity. Natural Language Processing (NLP) involves looking at a piece of text and working out what it is about or even synthesizing text on the same topic. Naturally, there is an overlap between A.I. and machine learning (as in the case of deep learning models), though this is fairly limited. For example, advanced optimization methods are a key application of A.I. that has nothing to do with machine learning per se, even if it is sometimes employed in the more advanced models. Beyond the differences that emerge from the above descriptions of the two fields, there are a few more that's worth keeping in mind. Namely, machine learning models can often be interpreted, at least to some extent. On the other hand, (modern) A.I. models are black boxes, at least for the time being. What's more, machine learning models come in a variety of types, while A.I. ones are graph-based. Additionally, A.I. has a more diverse range of applications, while machine learning is limited to specific ways that are related to data science work. Finally, in machine learning, you need to do some data engineering before you work your models, while in A.I. it's rarely the case (even though it can be very helpful). If you are interested in this topic (particularly classical machine learning), you learn more about it through my book Julia for Machine Learning, published last Spring. This book is very hands-on, having plenty of examples that illustrate how machine learning methods work, be if for data engineering or data modeling tasks. The language used (Julia) is an up-and-coming data science language that boasts several packages under the machine learning umbrella. In this book, we explore the most important of them, which have stood the test of time. Check it out when you have the chance. Cheers!  Recommender systems are specialized models that make recommendations about how data points are connected within a dataset, without a clear distinction between training and testing data. They are based on the concept of interactions, which are the links between pairs of data points. Recommender systems are essential as an application of data science and are widely used today in various domains. This article will explore the various kinds of recommender systems and some useful recommendations about how you can go about building them. First of all, the data recommender systems utilize consists of two main parts: the characteristic information (user data, keywords, categories, etc.) and user-item interactions data (e.g., review scores, number of likes, items bought, etc.). This data usually dwells in two different matrices, which constitute the recommender system's dataset. Note that these matrices can increase in size as new users or new items become available, something quite common in many recommender system scenarios. There are various types of recommender systems, depending on how the data is used. There are collaborative filters (based on the interactions in the user-items data), content-based systems (employing the characteristic data), and combinations of the two, aka, hybrid models. These recommender systems types are useful, but each has its use cases, where it shines. Yet, regardless of what systems are out there, you need to make sure you understand the data at hand before you start building your recommender system. After all, just because a particular kind of RS model works well for some problems, it doesn't mean it would work well with yours. That's why you need to examine your data closely and figure out what model is best suited for it. If, for example, you don't have enough user-item interaction data at your disposal, you may want to go for a content-based model, or perhaps a hybrid one. Also, if you need to add new items or new users to your dataset often, then maybe you should avoid collaborative filters altogether. What's more, you may want to explore the deep learning option since deep neural networks (fully connected ones) handle this sort of problem. Of course, it's best to have lots of data for such a scenario for the DNNs to have a performance edge justifying the computation costs involved. So, it's good to consider other options, such as a simpler model for your recommender system. Also, note that the model you build has to be aligned with the project's requirements at hand. However, it’s not just DNNs that require lots of data to work well. Collaborative filtering models are also in need of lots of information to work with to be useful. This data needs to be mainly in the interactions matrix; otherwise, the model won't work correctly, making more random recommendations. That's why data acquisition and data engineering are particularly crucial for recommender systems in general. Beyond all these suggestions, you ought to have a good understanding of the functionality of recommender systems and the right mindset towards such problems. Additionally, you need to check the models after new data is added to the dataset, particularly new items. That's because these will take the form of empty columns in the user-item matrix, making the latter sparser and, therefore, the model less robust. However, there are ways around this issue, which stems from a good understanding of the recommender systems themselves. If you wish to learn more about RS and the data science mindset in general, I invite you to check out my book Data Science Mindset, Methodologies, and Misconceptions. It’s been a few years now that it was published, but its content is still relevant and useful for any data scientist. So, check it out when you have the chance. Cheers!  Data science knowledge is vast and varied. It entails an in-depth understanding of data, the impact of models on this data, and various ways to refine the data making it more useful for these models. Also, it has to do with ways to depict this data graphically and make useful predictions based on it, using new data as inputs. Specialized data science knowledge also involves depicting this data in different ways (e.g. via a graph structure), gathering it from various sources (e.g. text), and creating interactive applications based on the data models built. Naturally, all this can be of value not just to data scientists but also to other data-related professionals. Let's examine how. So, how can data science knowledge help data analysts and business intelligence professionals? After all, they are the closest to the role of a data scientist and deal with data in similar ways. These professionals can benefit from data science knowledge through a more in-depth understanding of the data, particularly when it comes to ETL processes and data wrangling. Also, for those more geared towards data models, they can learn more advanced models such as the machine learning models data scientists use and start using them in their work. As for data modelers (data architects), data science knowledge can help those professionals too. After all, designing a useful information flow or implementing such a design into a database is closely linked to how this information is used. So, by understanding the potential different variables have (something that's bread and butter for a data scientist), a data modeler can optimize his work and build systems that are more future-tolerant. That is particularly useful in cases where the domain is dynamic, like in the e-commerce field. Programmers can benefit a lot from data science knowledge too, especially those versed in OOP and functional languages (e.g. Julia and Scala). After all, data science involves a great deal of programming so there is a good overlap in the skill set of the two types of professionals. For this reason, many programmers end up getting into data science once they familiarize themselves with data science models, something they can do easily once they get exposed to data science knowledge. Finally, data-driven managers have a lot to gain from data science knowledge, perhaps more than any other professional. The reason is that f you are involved in data-driven projects, you need to know what’s possible with the data you have and what kind of products or services you can build using this data. This is something you can do even without getting your hands dirty, by thinking in terms of data science. So, having some data science knowledge (particularly knowledge related to how data science is applicable and what data products look like), can go a long way. As a bonus, recruiting data scientists to implement your ideas is much easier if you are familiar with data science, something your recruits are bound to appreciate. If you found this article interesting, you can learn more about data science and how it is leveraged in an organization through a book I co-authored last year. Namely, the Data Scientist Bedside Manner book covers this and similar topics thoroughly, along with some other practical knowledge on this subject. So, check it when you have the chance and spread the word about it to friends and colleagues in the aforementioned lines of work. Cheers! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed