 About five months ago, I started writing a new technical book. I didn't have to, but the idea was burning me, and as I had been working on a particular data science topic the previous months, I felt it deserved to be shared with a larger audience. Of course, I could have just shared some code or perhaps put together some article, but the idea deserved more. So, I reached out to my publisher, sent him a proposal with an outline of the book, and before long, I was good to go! During these months I had been writing regularly (pretty much daily, at least on weekdays), with just a couple of weeks off, one for the Christmas holidays and one for the preparation of my podcast. This book project involved both text, images, and code (in the form of a new type of code notebook, for Julia). So, at least, I didn't get bored, plus I was a bit imaginative with a couple of the problems I tackled in the code notebooks. Although it's a bit soon to tell when the book will be out, at least the most time-consuming part is behind me now. Hopefully, I'll be able to focus more on other projects now. I'll keep you posted through this blog regarding updates on the book. Cheers!
0 Comments
 For about a month now, I’ve been working on a new technical book for Technics Publications. This is a project that I've been thinking about for a while, which is why it took me so long to start. Just like my previous book, this one will be hands-on, and I'll be using Julia for all the code notebooks involved. Also, I'll be tackling a niche topic that hasn't been done before in this breadth and depth, in non-academic books. Because of this book, I won't be writing on this blog as regularly as before.
If you are interested in technical books from Technics Publications, as well as any other material made available from this place, you can use the DSML coupon code to get a 20% discount. This discount applies to most of the books there and the PebbleU subscriptions. So, check them out when you have a moment!  Good documentation is in high demand everywhere, from coding libraries to products and services to even data science projects. The funny thing is that even though many people value communication in data science, not everyone can link good communication and good documentation. Interestingly, even if you are the most charismatic communicator out there, if you don't express your communication skills in your documentation, your data science work will suffer. But why is documentation so valuable? What about visuals? Aren't they worth (at least) 1000 words each? What's the point of dressing up our code notebooks with text too? First thing's first. You don't need to be a technical writer to write good documentation. Just take a look at the documentation of the most mature packages in Julia. Do you think their creators were technical writers? The same goes for other kinds of documentation available online. As long as the reader can understand what you are doing without having to dig deep into the code (or even worse, run parts of the code), your documentation is a decent first draft. That can later be improved, but first, you need to write it! Even if you are the only person to read this documentation, perhaps on a future iteration of that data science project, it's good to do it properly. This way, you won't scratch your head trying to figure out what you were thinking when you put that notebook together. Good documentation is not just about the reader, though. It's also about organizing your thoughts and understanding your code better. Perhaps some refactoring needs to take place, simplifying the whole project. Or maybe some examples could help clarify the objective or the value-add of your script. It's easy to lose sight of these matters when you are entrenched in analytics work, especially the coding part. A well-documented data science project can be a great addition to your portfolio (assuming, of course, that you have the option of exhibiting your work publicly). It's unlikely that someone will go through every line of your code to see what you've done. Still, that person may read at least parts of your documentation, especially the text at the beginning, where you explain the objectives, assumptions, and datasets related to this project. And you can be almost certain that if someone makes it to the end of your code notebook, they'll read your conclusions too. Documentation in data science may not seem as important a skill as knowledge of machine learning, data visualization, etc., but it's a powerful catalyst for all these. After all, just because you create a fancy visual, it doesn't mean that everything is fully comprehensible in it. Perhaps there is so much to see that you need to point the reader to the key findings, which they can then verify by looking closely at the plot. Although good code is self-explanatory, because of its structure and naming conventions, it's always useful to add some text around it. I'm not talking about some comments, but also stuff going beyond the code itself. After all, the code you write is not a work of art (even if you may think that at times!) but a means to an end. That end, along with how the code achieves that end, is something the reader of your code notebook shouldn't have to think about too much. It's better to make it easy for him through good documentation, allowing him to ponder on the whole project, rather than him having to spend all his time trying to figure out what you have done and why. I can go on about this topic until the cows come home. However, an attribute of good documentation is brevity, which is why I'll stop right here. If you find this material of value, you can check out my various books, where I talk about topics like this in more detail. Cheers!  Text editors are specialized programs that enable you to process text files. Although they are relatively generic, many of these text editors focus on script files, such as those used to store Julia and Python code (pretty much every programming language makes use of text files to store the source code of its scripts). So, modern text editors have evolved enough to pinpoint particular keywords in the script files and highlight them accordingly. This highlighting enables the user to understand the script better and develop a script more efficiently. Many text editors today can help pinpoint potential bugs (programming jargon for mistakes or errors), making the whole process of refining a script easier. In data science work and work related to A.I., text editors are immensely important. They help organize the code, develop it faster and easier, optimize it, and review it. Data science scripts can often get bulky and are often interconnected, meaning that you have to keep track of several script files. Text editors make that more feasible and manageable as a task, while some can provide useful shortcuts to accelerate your workflow. Additionally, some text editors integrate with the programming languages themselves, enabling you to run the code as you develop it while keeping track of your workspace and other useful information. This is what people call an IDE, short for Integrated Development Environment, something essential for any non-trivial data science project. One of the text editors that shine when it comes to data science work is Atom. This fairly minimalist text editor can handle various programming languages, while it also exhibits several plugins that extend its functionality. It's no wonder that it is so widely used by code-oriented professionals, including data scientists. Like most text editors out there, it's cross-platform and intuitive, while it's highly customizable and easy to learn. It's also useful for viewing text files, though you may want to look into more specialized software for huge files. Another text editor that gained popularity recently, particularly among Julia users, is Visual Studio Code (VS Code). This text editor is much like Atom but a bit easier and slicker in its use. It has a smoother interface, while its integration of the terminal is seamless. The debug console it features is also a big plus, along with the other options it provides for trouble-shooting your scripts. Lately, it has become the go-to editor for Julia programmers, something interesting considering how vested the Julia community had been to the Atom editor and its Julia-centric version, Juno. Beyond these two text editors, there are other ones you may want to consider. Sublime Text, for example, is noteworthy, though its full version carries a price tag. In any case, the field of text editors is quite dynamic, so it's good to be on the lookout for newer or newly-revised such software that can facilitate your scripting work. If you want to practice coding for data science and A.I. projects, there are a few books I’ve worked on that I’d recommend. Namely, the two Julia books I've written, as well as the A.I. for Data Science book I've co-authored, are great resources for data science and A.I. related coding. Check them out when you have a moment. Cheers! It may seem surprising that a page like this would exist on this blog. After all, this is a blog on data science and A.I. Well, regardless of our field, we all need to write from time to time, be it for a blog, a report, or even the documentation that accompanies our work. Since writing in a grammatically correct way, void of typos doesn't come naturally to most of us, an online service like Grammarly can come in handy. I was recommended this service about a year back by a fellow writer. Although my texts were pretty decent, I found that I'd still make some mistakes from time to time, or build sentences that weren't easy to follow. So, I took up the suggestion and started using Grammarly for some of my articles. The result in terms of engagement was evident from the very beginning. As a result, I've been using Grammarly ever since. At the same time, it's now part of my pipeline when it comes to publishing articles on this blog. So, when I promote this service, it's out of my empirical understanding of its value and an appreciation of the tech behind it. For example, did you know that it uses deep learning and natural language processing (NLP) on the back-end? It also evaluates text based on different styles and objectives, giving you an overall score, all while pinpointing errors and points of improvement. For each one of these mistakes, it provides suggestions of how you can correct them and a rationale so that you learn from them. What more can you ask for? I invite you to try it out on your browser using this affiliate link and if you see merit in it, register for the paid version. Using this link, you can also contribute to this ad-free blog by helping cover some of its expenses. Cheers!   Normally I don't do book reviews on this blog but for this one, I thought I'd make an exception. After all, it's not every day I encounter a book that tackles topics like Logic head-on, without getting all abstract and theoretical. This book not only manages to remain practical but also gives a good overview of the topic of logic, something that every data professional can benefit from. Note that this book is on the subject of data modeling, which although related to data science, is its own field and is concerned with databases, as well as the design of such systems.
First of all, the book provides an excellent introduction to Logic, without getting too mathy about the topic. When I was looking into Ph.D. topics, I briefly considered doing my research on this subject. However, I quickly dismissed it because it was too abstract and theoretical. This book addresses this point and presents the subject in a very practical way, making it relatable and interesting. This is something it manages by providing a connection between Logic and databases, with plenty of examples. This enables the reader to maintain a practical viewpoint across the different topics covered in the book and view logic as a useful tool. What’s more, the author does a pretty good review of other books on the subject with a robust criticism of their strengths and weaknesses. In a way, it feels like reading a bunch of books, getting the gist of their approaches, without having to go through their text. It is evident that the author knows the subject in great depth, something that he exhibits through his approach on the subject, which is also quite distinct. For example, he provides a great analysis of topics that weren't covered properly elsewhere such as that of integrity. Also, the author provides lots of references for each topic at the end of each chapter, making the whole book feel a bit academic in that sense, but without the rigid style that characterizes such books. However, for someone who wishes to explore the various topics further, this list of relevant resources at the end of each chapter can be quite handy. Moreover, the book is fairly easy to understand even for non-experts in data modelings or logic. This is important since it’s not common to find a technical book that’s accessible to non-experts in the topic. This book, however, seems to have a very broad audience, even people who know very little about the subject. Finally, there are lots of definitions of key concepts and a scientific approach to the subject overall. This is also not very common since not all technical books are written by scientists. Also, many people nowadays write a book based on their experience and empirical knowledge on a subject. This book, however, was written in a scientific manner, even if it doesn't have the typical academic style. So, if you are interested in buying this book, you can do so directly from the publisher. Also, if you were to use the code coupon DSML you can get a 20% discount, making this purchase a bargain. Note that this code applies to other books available at the Technics Publications site, including some of the webinars.  Being an author has many benefits, some of which I’ve mentioned in a previous article. After all, an author (particularly a technical author) is more than just a writer. The former has undergone the scrutiny of the editing process, usually undertaken by professionals, while a writer may or may not have done the same. Also, an author has seen a writing project to its completion and has gotten a publisher to put his or her stamp of approval on that manuscript, before making it available to a larger audience. This raises the stakes significantly and adds a great deal of gravity to the book at hand. Being an author is its own reward (even though there are other tangible rewards to it too, such as the royalties checks every few months!). However, there is a benefit that is much less obvious although it is particularly useful. Namely, an author can appreciate other authors more and learn from them. This is something that I have come to learn since my first book, yet this appreciation has reached new heights since then. This is especially the case when it comes to veteran authors who have developed more than one book. All this leads to an urge to read more books and get more out of them. This is due to the value an author puts into these books. Instead of just a collection of words and ideas, he views a book as a sophisticated structure comprising of many layers. Even simple things like graphics take a new meaning. Of course, much of this detailed view of a book is a bit technical but the appreciation that this extra attention contributes to is something that lingers for long after the book is read. Nevertheless, you don't need to be an author to have the same appreciation towards other people's books. This is something that grows the more you practice it and can evolve into a sense of discernment distinguishing books worth having on your bookshelf from those that you are better off leaving on the store! At the very least this ability can help you save time and money since it can help you focus on those books that have the most to offer to you. In my experience, Technics Publications has such books worth keeping close to you, particularly if you are interested in data-related topics. This includes data science but also other disciplines like data modeling, data governance, etc. There is even a book on Blockchain, which I found very educational when I was looking into this technology, which goes beyond its cryptocurrency applications. Anyway, since good books come at a higher cost, you may want to take advantage of a special promo the publisher is doing, which gives you a 20% discount for all books, except the DMBOK ones. To get this discount, just use the DSML coupon code at the checkout (see image below). 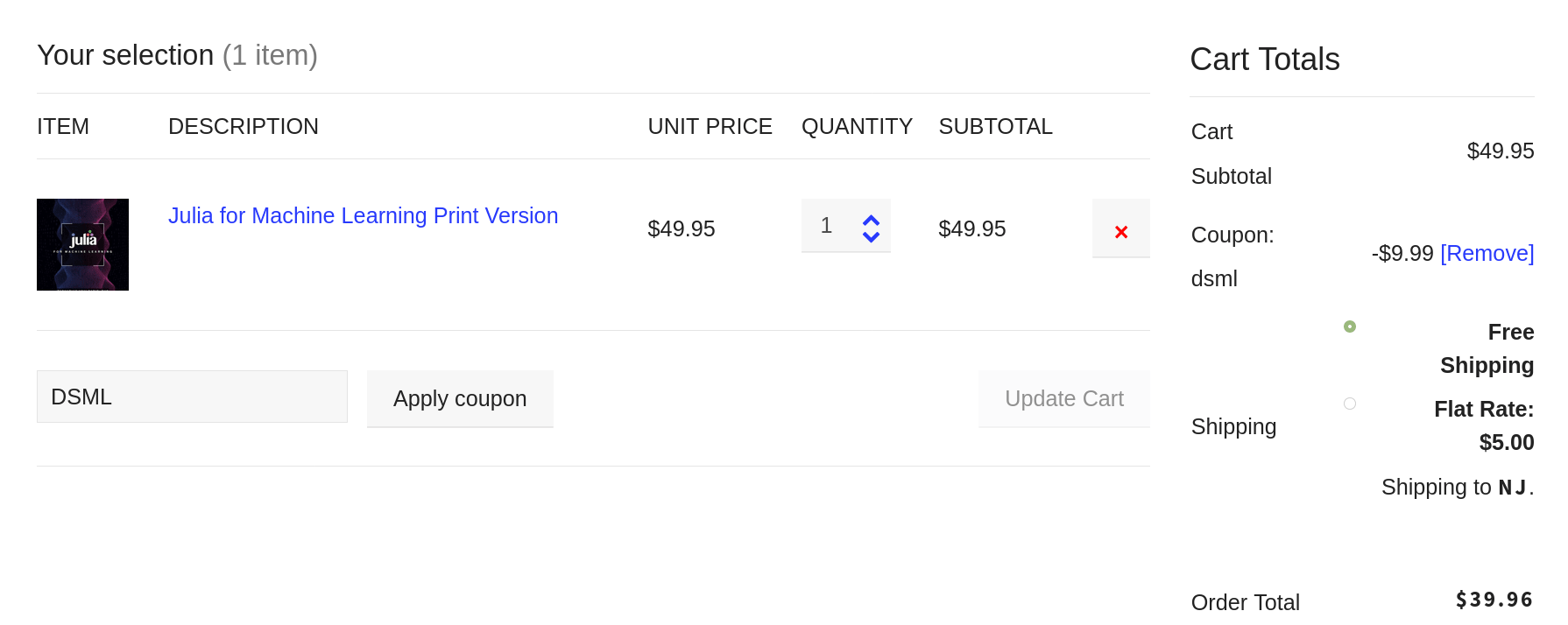 Note that this coupon code applies to virtual classes offered by Technics Publications (i.e. the virtual training courses in the ASK series). This, however, is a topic for another article. Cheers!  These days I didn't have a chance to prepare an article for my blog. Between helping out a friend of mine and preparing for my webinar this Thursday, I didn't have the headspace to write anything. Nevertheless, one of the articles I wrote for my friend's initiative, related to mentoring, is now available on Medium. Feel free to check it out! As for the webinar, it's about the data science mindset, a topic I talked about on all of my books, particularly the Data Science Mindset, Methodologies, and Misconceptions one. At the time of this writing, there are still some spots available for the webinars, so if you are interested, feel free to register for it here. On another note, my latest book is almost ready for the review stage so I'll be working on that come Friday. Stay tuned for more details in the weeks to come... That's all for now. I hope you have a great week. Stay healthy and positive!  With more and more people getting into data science and AI these days, certain aspects of the field are inevitably over-emphasized while others are neglected. Naturally, those providing the corresponding know-how are not professional educators, even if they are competent practitioners and very knowledgeable people. As a result, a lot of emphasis is given to the technical aspects, such as math and programming related skills, data visualization, etc. What about domain knowledge though? Where does that fit in the whole picture? Domain knowledge is all that knowledge that is specific to the domain data science or AI is applied on. If you are in the finance industry, it involves economics theory as well as how certain econometric indexes come into play. In the epidemiology sector, it involves some knowledge as to how viruses come about, how they propagate, and their effects on the organisms they exploit. Naturally, even if domain knowledge is specialized, it may play an important role in many cases. How much exactly depends on the problem at hand as well as how deep the data scientist or AI practitioner wants to go into the subject. Domain knowledge may also include certain business-related aspects that also factor in data science work. Understanding the role of the different individuals who participate in a project is very important, especially if you are tackling a problem that is too complex for data professionals alone. Oftentimes, in projects like this, subject matter experts (SMEs) are utilized and as a data scientist or AI professional you need to liaise with them. This is not always easy as there is limited common ground that can be used as a frame of reference. That's where some general-purpose business knowledge comes in handy. Naturally, incorporating domain knowledge in a data science project is a challenge in and of itself. Even if you do have this non-technical knowledge, you need to find ways to include it in the project organically, adding value to your analysis. That's why certain questions, particularly high-level questions that the stakeholders may want to be answered, are very important. Pairing these questions with other, more low-level questions that have to do with the data at hand, is crucial. Part of being a holistic, well-rounded data science / AI professional involves being able to accomplish this. Of course, exploring this vast topic in a single or even multiple blog posts isn’t practical. Besides, how much can someone go into depth about this subject without getting difficult to read, especially if you are accessing this blog site via a mobile device? For this purpose, my co-author and I have gathered all the material we have accumulated on this topic and put it in a more refined form, namely a technical book. We are now at the final stages of this book, which is titled “Data Scientist Bedside Manner” and is published by Technics Publications. The book should be available before the end of the season. Stay tuned for more details...  Lately, I've made some progress on a data science research project I've been working on for the past couple of years. I’ve hinted about it in previous posts, though due to the nature of this work I’ve abstained from going into any details. Besides, most people are not that open to new ideas, unless they are marketed by some established company or some renowned professor. Anyway, the other day I made a breakthrough in this work, something that can have significant implications in how we deal with private data. What’s more, I've developed a new way of summarizing a dataset (which is innately different from sampling it), with minimal loss of information. This opens new avenues of research and the possibilities of new data science and A.I. methods are vast. Naturally, I'll need to look into this more, so any online writing I do will have to take second priority. Parallel to that, I’ve been working on another project lately, something I plan to continue for the foreseeable future. However, an important part of it is completed, which I’ll make sure I’ll announce in the next few days. As a result to all this, I’m now more open to hosting other people’s articles on data science and A.I. topics, given that they are not spammy in any way. Back-links are also acceptable, given that they are towards relevant sites to the articles. So, if you have something you’d like to contribute to the blog, now is a great opportunity to do so. Whatever the case, I plan to continue writing on this blog albeit at a slower pace for the time being, so stay tuned! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed