|
Due to the success of the Analytics and Privacy podcast in the previous few months, when the first season aired, I decided to renew it for another season. So, this September, I launched the second season of the podcast. So far, I have three interviews planned, two of which have already been recorded. Also, there are a few solo episodes too, where I talk about various topics, such as Passwords, AI as a privacy threat, and more. Since I joined Polywork, many people have connected with me on various podcast-related collaborations, some of which are related to this podcast. So, expect to see more interview episodes in the months to come.
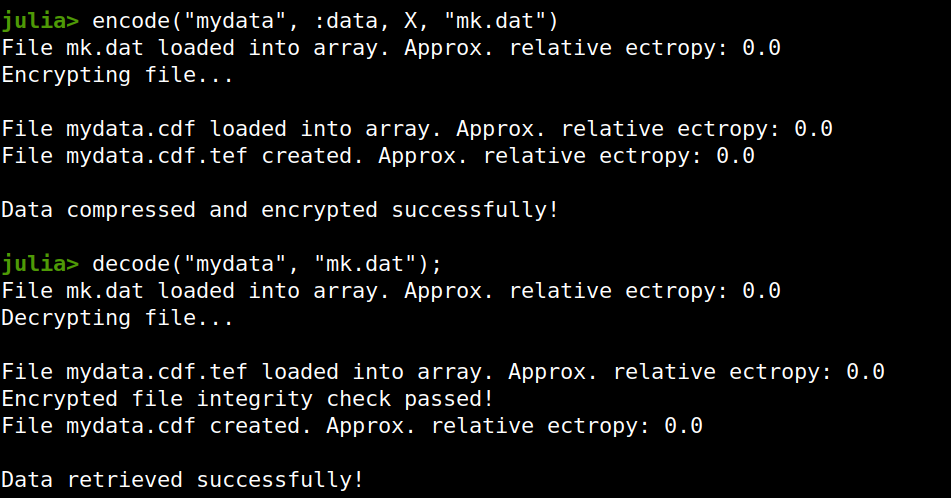
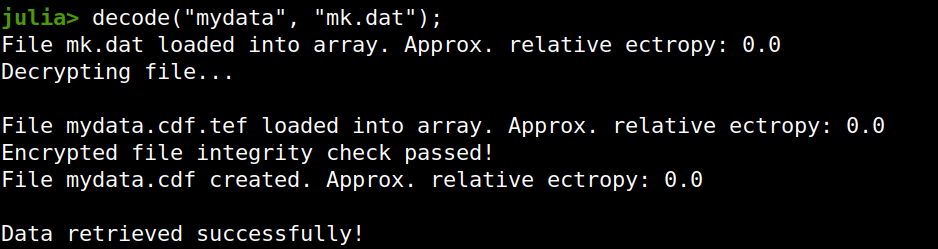
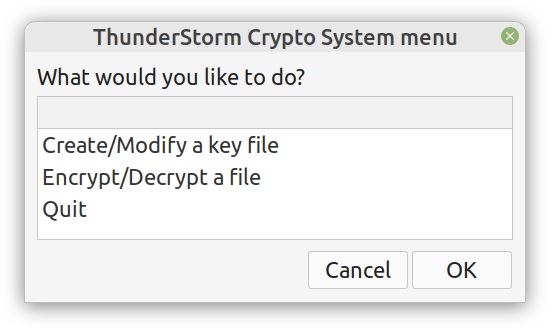
There is no official sponsor for this season of the podcast yet, so if you have a company or organization that you wish to promote through an ad in the various episodes (it doesn’t have to be all the remaining episodes!), feel free to contact me. Cheers!  Lately I published an episode of my podcast where I talk about compression and encryption as privacy tools (link). That’s all nice and dandy but how do we do any of that in practice? Well, most compression programs have an encryption option, which may be sufficient for low-confidentiality documents. But what about datasets that contain lots of PII? And if you are like me, you may use Julia for processing them, since it’s by far the most efficient programming language for the task, that’s also high-level. Enter ComCrypt, a simple script that does high-quality compression and quantum-proof encryption all in one go. Namely, it makes use of the CDF script which I’ve talked about before (it’s been about two years since I created it) for compressing the data into an archive having the .cdf extension (which stands for compressed data format and it’s native to Julia). Then it applies ThunderStorm to it, using an external key file. If anything goes wrong throughout this process, ComCrypt alerts the user with some error message informing about the part that threw the error. Otherwise, it yields a message saying that the data has been compressed successfully. The reverse process shares the same philosophy. Currently, ComCrypt at its first version so its scope is a bit limited (e.g., it handles only a single data object per file). However, there are ways to make it more usable and useful. In any case, it’s already a useful little tool for keeping your data safe when working in the Julia environment. Also, it’s very light on the dependencies (just one external library and a few Julia scripts). Cheers.  Overview I've been working on this cipher for several years now, and although it's not the first one I've developed, it's the best one, so far. Not just in terms of security but also in speed and customization. I haven't touched the algorithm in a couple of years now, but I recently did some updates on its shell functions and its GUI for better usability. But I'm getting ahead of myself. Let's start with some basics first, in case you are not familiar with it. What ThunderStorm Is ThunderStorm is a semi-symmetric encryption system designed for codes impenetrable by conventional cryptanalysis methods. Unlike other encryption methods, it doesn't rely on prime numbers and factoring, while it employs true randomness in the keys it uses for additional security. It currently exists in two versions: one that's order-sensitive and one that's purely symmetric and order-indifferent. The former makes for a stronger cipher, while the latter is lighter. ThunderStorm is implemented entirely in Julia (recently tested in v.1.7.2 with no issues) and has minimal dependencies on any libraries. How It Works In a nutshell, ThunderStorm works as follows. It captures all the relevant information regarding the size of the original file and its hash. It then encrypts it using the hash of the key. This is the header of the encrypted archive. Then a random amount of noise is created and added to the original file. After that, the data is encrypted and shuffled using the key, in a byte-wise fashion. The resulting archive, which is somewhat larger than the original is outputted using a file extension that makes it clear what it is. For the decryption process, the reverse is done. Note that if a single bit in the key file is off, the decryption process won't work, or if it does, it will yield a completely different file that would be unrecognizable. Also, if you were to take a random byte in the encrypted archive there is no way of knowing if that byte is an encrypted part of the original file (it could be just noise) or if it is which part of the file it comes from or what it is exactly. Also, only part of the key is usually used for the encryption, while its parts are shuffled before being utilized in the encryption process. I had published a video on ThunderStorm back in my Safari days, but it's no longer available since the contract with O'Reilly (which acquired Safari at one point) came to an end. ThunderStorm Use Cases The ThunderStorm system has several real-world use cases. Primarily, it is ideal for individual use, particularly for static documents (e.g., a password archive, financial records, etc.). This includes documents that are stored in the cloud or a web server. Additionally, ThunderStorm can be modified to be used for exchanging sensitive documents, where increased cybersecurity is a requirement. For all the use cases, large encryption keys are strongly recommended, something possible through an auxiliary method of the ThunderStorm system. A large key can be manufactured in such a way that it has zero ectropy (i.e., maximal entropy possible), making cryptanalysis extremely difficult if not altogether impossible. The fact that keys can be reused in ThunderStorm with minimal risk is an asset that can be harnessed for efficiency. Latest Improvements Since I'm a big fan of continuous improvement (Total Quality Management), I decided to make a GUI for ThunderStorm, even though I'm not a GUI kind of guy. Still, after having developed my BASH scripting skills enough, I was able to do that. So, recently I came up with a new script that leverages a few window screens to facilitate the use of this program. It still uses Julia on the back-end, but it can run directly from the shell (or the file manager, if you prefer). Below are some screenshots of the interactive aspects of that script. Note that some of the functionality of ThunderStorm was removed to make the whole program easier for the average user. For the more tech-savvy users, the functionality remains and can be accessed through the corresponding Julia scripts. Parting Thoughts Probably this is not the last update on ThunderStorm since it's been my pet project for a while now. Also, considering how feeble most ciphers are when it comes to the quantum threat, someday enough people may see value in a robust and unconventional cipher, to warrant further R&D on it. Until then, it will probably remain a niche thing, much like the language it was written in, as most high-level developers prefer to stick with the languages they know instead of going for a newer and objectively better language like Julia. Cheers!  As much as I'd love to write a (probably long) post about this, I'd rather use my voice. So, if you are interested in learning more about this topic, check out the latest episode of my podcast, available on Buzzsprout and a few other places (e.g., Spotify). Cheers!
 Alright, the new episode of my podcast, The Ethics of Analytics Work and Personally Identifiable Information, is now live! This is a fundamental one since here I try to clarify what PII is, a term that is used extensively in most future episodes of the podcast. Also, I talk about ethics, without getting all philosophical, and describe how it’s relevant to our lives, especially as professionals. So, check it out when you have a moment! Cheers.
 Lately, I've been preparing a podcast on the topic of (data) Analytics and Privacy. Having completed the first few episodes, I've decided to make it available at Buzzsprout. Alternatively, you can get the RSS feed to use with either a browser add-on or some specialized program that handles RSS links: https://feeds.buzzsprout.com/1930442.rss The podcast deals with various topics related to privacy, usually from an analytics angle, or vice versa. However, it appeals to anyone who is interested in these subjects, not just specialized professionals. Clocked at around 20 minutes each, the episodes of this podcast are ideal for your daily commute or any other activity that doesn't require your full attention. Feel free to check out these links and, if you like the podcast, share these links with friends and colleagues. Cheers!  Everyone can analyze data these days, given the right programming tool and some library of functions, to express practically the relevant know-how of that person. I've seen people who give away books for free (as it would be impossible for them to get others to buy them) analyze data. As data science becomes more widespread, data analysis becomes a given for a larger portion of the population. But what about data synthesis, however? What's up with that? Let's delve into this. First of all, let's get some definitions down. Data synthesis is the creation of synthetic data that follows a given pattern. The latter can be given directly to the data generation program, or it can be derived (extrapolated) via data analytics. Synthetic data is ideally indistinguishable from conventional data, and you can use it to train a data model, for example. However, there is something that makes it extremely valuable. The value of synthetic data lies in the fact that it's not tied to particular individuals, so using this data doesn't pose any PII-related issues. Because of this, it cannot be owned by any specific person, even if it can be leveraged in the data science pipeline, yielding value. Naturally, since there are no shortcuts to value-making, the value (information) of that synthetic data must come from somewhere. So, since it's not practical for someone to have a high-level mathematical representation of this value and give it to a program as a pattern, it's more likely that this value stems from the source data. So, to have valuable synthetic data (that's also free of PII), we need to have some source data of value, for starters. That's why the only practical way to generate synthetic data that's worth its space on a hard disk is via analytics. Of course, there are ways to generate such data through analytics, as in the case of some specialized deep learning networks (Autoencoders). The catch is that these A.I. systems require lots of data to do their job. After all, analyzing multiple variables isn't easy, even for an A.I. What if there was a way to perform the same task without employing these more advanced data-hungry systems? Enter the BROOM framework again! We've already described some of its functionality, but what if this was just a prelude for its more sophisticated aspects? Well, fortunately, data synthesis isn't all that different from sampling, if you know what you are doing? And if you can sample a dataset properly, it's not that much more challenging to create new data points aligned with its essence. Naturally, the synthetic data is generated in a stochastic manner since it makes more sense to leverage noise in this process. Otherwise, all the generated data would be the same every time. Oh, and did I mention that this data synthesis process is scalable to as many dimensions as you like? Because if you understand data in-depth, the cardinality of vectors in a dataset is just another number...  There is a certain kind of information in the world of data that makes it possible to identify particular individuals personally. In other words, there is a way to match a specific person to a data record based on the data alone. Such data is referred to as personally identifiable information (PII), and it's crucial when it comes to data science and data analytics projects. After all, PII's leakage would put those individuals' privacy at risk, and the organization behind the data could get sued. In this article, we'll look at a couple of popular methodologies for dealing with PII. Fortunately, Cybersecurity as a field was developed for tasks like this one. Anything that has to do with protecting information and privacy falls under this category of methods and methodologies. Since PII is such an important kind of information, several cybersecurity methodologies are designed to keep it safe and the people behind this information. The most important such methodologies are anonymization and pseudonymization. These methodologies aim to either scrap or conceal and PII-related data, securing the dataset in terms of privacy. Let’s start with anonymization. This Cybersecurity methodology involves scrapping any PII from a dataset. This methodology involves any variables containing PII (e.g., name, address, social security number, financial information, etc.) or any combination of variables closely linked to PII (e.g., medical information with general location data). Although this can ensure to a large extent that PII is not abused, while it also makes the dataset somewhat lighter and easier to work with, it's not always preferable. After all, the PII fields may contain useful information for our model, so discarding it could distort the dataset's signal. That's why it's best to use this methodology for cases when the PII variables aren't that useful, or they contain very sensitive information that you can't risk leaking out. As for pseudonymization, this is a Cybersecurity methodology that entails the masking of PII through various techniques. This way, all the relevant information is preserved in some form, although deriving the original PII fields from it is quite challenging. Although this Cybersecurity methodology is not fool-proof, it provides sufficient protection of any sensitive information involved, all while preserving the dataset's signal to a large extent. A typical pseudonymization method is hashing, whereby we hash each field (often with the addition of some "salt" in the process), turning the sensitive data into gibberish while maintaining a one-to-one correspondence with the original data. Beyond anonymization and pseudonymization, several other Cybersecurity methodologies are worth knowing about, even if you only delve in data science work. If you want to learn more about this topic, including how it ties in the whole Cybersecurity ecosystem, you can check out my latest video course: (Fundamentals of) Anonymization and Pseudonymization for Data Professionals on WintellectNow. So, check it out when you have a chance. Cheers!  The latter has been something I've been looking into for a while now. However, my skill-set hasn't been accommodating for this until recently, when I started working with GUIs for shell scripting. So, if you have a Linux-based OS, you can now use a GUI for a couple of methods in the Thunderstorm system. Well, given I'll release the code for it someday.
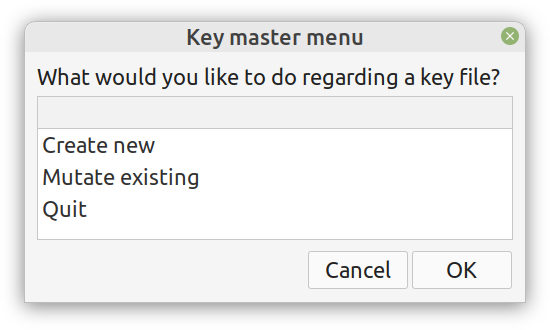
Alright, enough with the drama. This blog isn't FB or some other overly sensational platform. However, if you've been following my work since the old days, you may be aware of the fact that I've developed a nifty cipher called Thunderstorm. But that's been around for years, right? Well, yes, but now it's becoming even more intriguing. Let's see how and why this may be relevant to someone in a data-related discipline like ours. First of all, the code base of Thunderstorm has been refactored significantly since the last time I wrote about it. These days, it features ten script files, some of which are relevant in data science work, too (e.g., ectropy_lite.jl) or even simulation experiments (e.g., random.jl, the script, not the package!). One of the newest additions to this project is a simple key generation stream (keygen) based on a password. Although this is not true randomness, it's relatively robust in the sense that no repeating patterns have emerged in any of the experiments on the files it produced. Some of the key files were several MB in size. So, even though these keys are not as strong as something made using true randomness (a TRNG method), they are still random enough for cryptographic tasks. What's super interesting (at least to me and maybe some open-minded cryptographers) is a new method I put together that allows you to refresh a given key file. Naturally, the latter would be something employing true randomness, but the particular function would work for any file. This script, which I imaginatively named keys.jl, is one I've developed a GUI for too. Although I doubt I'll make Thunderstorm open-source in the foreseeable future (partly because most people are still not aware of its value-add in the quantum era we are in), I plan to keep working on it. Maybe even build more GUIs for the various methods it has. The bench-marking I did a couple of months back was very promising for all of its variants (yes, there are variants of the cipher method now), so that's nice. In any case, it's good to protect your data files in whatever way you can. What better way than a cipher for doing this, especially if PII is involved? The need for protecting sensitive data increases further if you need to share it across insecure channels, like most web-based platforms. Also, even if something is encrypted, lots of metadata from it can spill over since the encrypted file's size is generally the same as that of the original file. Well, that's not the case with the original version of Thunderstorm, which tinkers with that aspect of the data too. So, even metadata mining isn't all that useful if a data file is encrypted with the Thunderstorm cipher. I could write about this topic until the cows come home, so I’ll stop now. Stay tuned for more updates on this cryptographic system (aka cryptosystem) geared towards confidentiality. In the meantime, feel free to check out my Cybersecurity-related material on WintellectNow, for more background information on this subject. Cheers!  More and more datasets these days contain sensitive data capable of identifying the people behind those ones and zeros. We usually refer to this kind of data as personally identifiable information or PII for short. PII is a privacy concern for every data scientist or analyst working with such a dataset since if it leaks, we're all in trouble! Not just the data scientist, but also the whole organization, especially if it's complying with privacy regulations like GDPR. Let's look into this matter in more detail. First of all, PII-related privacy is inevitable in most data science projects today in the real world. Chances are that at least some of the variables you deal with contain some type of sensitive data. These can be things like names, contact details, credit card numbers, and even health-related data (this latter kind of PII is particularly important since most of it cannot be changed, in contrast to a credit card). Even geo-location data is often under the PII umbrella though on its own it's not so sensitive because it's hard to match it to a particular individual without using some other variable too. This matching of particular variables to specific individuals is the source of all privacy-related problems. It's not so much the fact that some people's identities are compromised that's the issue (who cares if it becomes public that I enjoy a cup of coffee at the local coffee shop every morning?) but the fact that this data is supposedly protected. When it's out in the open, it's a breach of some privacy legislation, while the organization that handles this data is liable for a lawsuit. To make matters worse, if word gets out that a particular company doesn't protect its clients' sensitive data adequately, its reputation is bound to suffer, and its brand can be damaged. Not to mention that some of this PII can be traded in the black market, so if a malicious hacker gets hold of it, it can make things even more challenging to manage. To avoid these problems, we need to handle PII properly. You can do this in various ways, some of which we're going to explore in future articles. As I've lately delved more into Cybersecurity and Privacy, I can provide a better perspective on this subject, which can tie into data science work more practically. However, should you wish to delve into this topic a bit now, you can check out my latest video course on WintellectNow, titled Privacy Fundamentals. There I cover various practical ways about securing privacy in your personal and professional life. It's not data science-focused, but it can help you cultivate the right mindset that will enable you to handle PII more responsibly. Stay tuned for more material in the coming months. Cheers! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|

 RSS Feed
RSS Feed