 (Image originally found in this slideshow)
Lately there is a lot of talk on AI, particularly how it applies to data science and data analytics in general. Many people even confuse it with machine learning (ML), since most modern ML systems employ AI in one way or another. In this post I’ll share my experience on this matter and hopefully shed some light on this somewhat obscure topic, highlighting the most foxy aspects of it. In essence, Machine Learning is a set of algorithms that can be programmed in a computer (or some machine with some computational capacity) enabling some kind of learning from data. The first ML systems were Stats-based, since that’s what people in the data analytics field knew back then. Systems like LDA and Logistic Regression were the norm and for some people it is still the go-to method for tackling data analytics projects. As there were fox-like people back then too, gradually we started moving towards more innovative methods of teaching computers how to achieve generalization (this is the core aspect of every learning endeavor). Systems like k nearest neighbor (kNN) and artificial neural networks (ANNs) came about and offered an interesting alternative to the Stats-based ML methods. Gradually, the spectrum of ML increased as more and more systems were developed, such as support vector machines (SVMs) and ensemble structures (amalgamations of classifiers or regressors). Artificial Intelligence developed almost independently and has to do with making computers (and machines in general) reason in an independent manner, resembling the way humans reason. That’s not to say that AI systems emulate human thought, even though there have been attempts in that direction. Human thinking is far more complex as it involves other aspects that are really hard to represent programmatically (e.g. feeling, intuition, etc.). Therefore, AI has traditionally focused on data analytics projects, particularly text analytics, though it has also been applied on the reverse process too: text synthesis and creativity. Yes, AI systems have been creative too. Although they haven’t managed to open up an art gallery lately, there have been poems, musical compositions, and even paintings that have been developed by AI-imbued computers. Although all this is quite fascinating, as a data scientist, you may not be that interested in the quaint poetry developed by an AI (like this one). If you are like me, you probably care more about how AI can be useful in deriving insights from data and doing so in an efficient manner, probably using some fast programming platform like Julia. AI-based systems like deep learning networks, neurofuzzy classifiers, and evolutionary computation systems that are on the back-end of ML ones, to name a few, are such cases. These are AI-based systems that are geared towards ML-related applications. Keep in mind though that these are but a few of these systems, since there may be more out there that fall into this category. Even if some of them are not so popular as the deep learning ones, they may be as robust. For example extreme learning machines (ELMs) promise to deliver accuracy that rivals that of deep learning networks, with a fraction of the computational cost. So, if you wish to work on this part of data science, which also happens to be the frontier of the field, be prepared for AIs that may challenge your own intelligence in one way or another!
0 Comments
 Matsuo Basho's "Frog Haiku", one of the earliest haiku poems, composed 330 years ago. The trees are growing bare As Fall comes to remind us all Of the transience of life. (Synesius, Fall of 2016) Haikus are a very singular poetry form, developed in Japan and used even today all over the world. They are in essence very short poems following the syllable structure 5-7-5 or 6-8-6 and aim to depict something transcendental usually through a reference to nature. “What does all this have to do with data science?”, you may wonder. Well, haikus are all about trying to condense a very important message in a very brief verse that complies to a very strict form, something that resembles in a way the communication of insights stemming from a data analytics project. Of course, as data scientists we don’t need to be fluent in the art of haiku, since the insights we deliver are often in non-verbal form (e.g. plots and dashboards). However, when writing data science scripts, be it in Python, Julia, or some other programming platform, we need to be concise and efficient.
Data science scripts differ from conventional scripts since the emphasis is more on getting something done, rather than optimizing for readability or some other objective that is often favored by coders. In data science we care about efficiency and try to make our scripts are fast as possible, but we don’t care so much about the form they would have. Unfortunately, we often go to the extreme and write code that is hard to maintain because it’s very dense. However, counter-intuitive as this may seem, this is a step in the right direction. A data science script has to be dense, packing a lot of computational power in a few lines of code, just like a haiku. Yet, there is no law against enriching that code with comments, just like haikus often have commentaries that aim to explain the ideas the poet wants to convey. Comments are free since they don’t cost us any CPU cycles so there is no limitation as to how many characters we devote to them. However, this humble programming element can add a lot of value to a script since it informs its user (who oftentimes is someone other than the script’s creator) of the functionality of each code block. The funny thing is that even if you feel confident that you know the script inside-out because you created it yourself, you may not have the same clarity or comprehension in the future when you revisit the script for another project. Even if the script is perfect (something rare), you may still need to change it to adjust it to another data set, so you really need to know what’s going on in every part of it. Comments can help shed light in all this. The Japanese managed to make a part of their culture (minimalistic efficiency) an integral part of world literature through the haiku poetry type. Perhaps we can do the same with our script, benefiting data analytics endeavors beyond our projects. The best part is that we don’t need to comply to a very strict syllable structure, plus we get to express our thinking not only with programming structures but also with comments, making everyone’s life easier. Can Data Science Tackle Modern Encryption Systems, Such as the Thunderstorm Coding System?10/20/2016  (image taken from thearmitageeffect.wordpress.com)
We covered the Thunderstorm Coding Sytem (TCS) in a previous post. Now, let’s look at it from a different angle. After all, that’s the foxy thing to do, esp. if you are serious about establishing its efficiency. So, what would happen if we tried to employ DS in order to perform cryptanalysis on a file that has been coded with this system? The short answer is “nothing”. Even though data science can unravel the most obscure mysteries lurking in the data, penetrating all the noise so that whatever signal that’s hidden in it can be made apparent, it doesn’t have a chance against an encryption system like TCS. The reason is simple; TCS, like other modern encryption system employs a combination of scrambling and shuffling when it encrypts the data of the file. Also, the way this is done is quite chaotic (though reversable). If there is a recoverable signal in the encrypted file that could pinpoint to the plaintext, it would take an insanely large number of features (enough to warrant the need for a supercomputer the size of a Google’s data center) to just be able to model the problem. Whether all these features would be enough to render a useful data model, however, is another story. Such a task would require an insanely large amount of computing power (another Google data center OR the use of a quantum compturer the likes of which we have never seen), to be able to reduce the dimensionality of the feature set to something manageable and dense enough in terms of information, that we can feed into a machine learning system. “What about AI?” I can hear you asking. Well, AI is very powerful in data science, but even the most sophisticated AI systems (I.e. deep learning networks) are not a panacea. For them to be effective they need a lot of data, more than the cyphertext of the file we are given to decrtypt. Also, should we attempt to apply a deep network on the aforementioned feature set and allow it to derive the best meta-features that can effectively solve the problem, we would need even more computing power (probably more that is available on a conventional cloud) to get this system to avoid halting. Of course, that’s all assuming that there is some kind of repetition in the key used for the encryption. If the key is large enough, not even all the computing power in the world could decrypt the file! That’s not to say that nothing would come out of such an endeavor. In fact, I would recommend you give it a shot, even if it is practically hopeless. Experiments like these can help one realise the limitations of the data science discipline and gain a better sense of perspective on what is and what isn’t possible (leading to a sense of humility, a rare quality among the professionals of our craft!). We all like to think that everything is possible, given enough memory and enough computing power. However, unless you are part of a Hollywood movie, this just doesn’t hold true. Some problems are just too hard to be solved (look into the various cyphers that have remain uncracked over the years if you don’t believe me). We’ll just need to find a way to be comfortable with that and focus on things that make business sense, such as deriving actionable insights from large amounts of data. 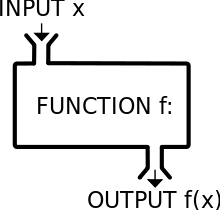 (image borrowed from the kammerath.co.uk website)
object-oriented programming paradigm (OOP) as it has been around long enough to have proven itself useful, and it has considerable advantages over the procedural programming paradigm that used to be the norm before. However, lately we have observed the emergence of a new kind of programming, namely the functional paradigm. Functional programming focuses on the use of functions rather than states and work-spaces of variables. Although this may seem alien to you if you are coming from a conventional programming background (aka imperative programming), it is very practical when dealing with complex processes as it mitigates the risk of errors, particularly logical ones that especially hard to debug. So it’s not surprising that functional programming has found its way to the data science pipeline with languages like Scala and lately Julia. Functional programming in data science allows for smoother and cleaner code, something that is particularly important when you need to put that code in production. Sometimes errors tend to appear under very specific circumstances that may not be covered in the QA testing phase (assuming you have one). This translates into the possibility of an error appearing in your pipeline when it is on the cloud (or on the computer cluster if you are the old-fashioned type!). Needless to say that this means lots of dollars leaking out of the company’s budget and doubts about your abilities as a data scientist flocking all over you. Functional programming makes all this disappear by ensuring that every part of the data science process has specific inputs and outputs, which are usually well-defined and crisp. So, if there is a chance of an error, it is not too hard to eradicate it, since it is fairly easy to test each function separately and ensure that it works as expected. So, even if Python is ideal for data science due to its breadth of packages, it may not be as robust when it comes to being put in production, compared to a functional language. This is probably why the Spark big data platform is built on Scala, a functional language, rather than Python or Java (even though Spark uses the JVM on the back-end). Also, even though Spark has a quite mature API for Python, most people tend to use Scala when working with that platform, even if they employ Python for prototyping. All in all, even though the OOP paradigm works great still and lends itself for data science applications, the functional paradigm seems to be better for this kind of tasks. Also, functional languages tend to be a bit faster overall (though low-level languages like C and Java are still faster than most functional languages). So, the choice before you is quite clear: you can either choose to remain in the OOP world with languages like Python (hedgehog approach) or venture a leap of faith in the realm of functional languages like Scala and Julia (foxy approach)…  (image taken from computerworld.com site)
A.I. is all the rage these days, esp. after Prof. Ng’s bold statement that “whoever wins A.I., wins the Internet.” Even though A.I. has been around for decades, only now has the world started to recognize its full potential, particularly in the online world. Even though A.I. is not an essential aspect of data science, it integrates quite well, particularly in the data modeling part of the pipeline. And yes, it is foxy as a discipline, definitely more than conventional computational methods! So, what is this alternative bit about? Well, conventional A.I. focuses on the stuff that all computational methods focus: getting things done! So, it often lacks the interpretability that other methods have. For example, decision trees, even though they are not the best classification/regression system out there, are excellent in that respect. Wouldn’t it be great if we had this kind of transperency in a system’s operation in the A.I. realm? “Well, duh!” you would probably say. Interpretability is great and it could of course be most welcome in an A.I. system. However, even though there have been serious attempts to make it a reality, eventually the “black box” approach came to dominate. The black box approach to A.I. is basically the exact opposite of transparency. You give a system some inputs, it spits out some outputs, and you have no idea how it came to these conclusions. You may get a confidence metric (aka probability score) as an output, but everything else in the whole process remains obscure. That’s not necessarily a bad thing though. Sometimes you just need a result and you don’t care so much about how it came about. However, if you want to explain this result to your manager or to a colleague, then you are in trouble! Black box A.I. systems may have some insightful results but are terrible at communicating them. If we were to imagine them as robots, a conversation with such a system would be something like this: Human: What do you think of this network traffic signature? AI: It is most likely malicious. Human: Are you sure? AI: Yes, at 87% Human: Why is it malicious? AI: I’m sorry Dave. I cannot answer that question! Human: Who is Dave? AI: I’m sorry Dave, I cannot answer that question either! So, even though a black box A.I. would be useful, it is doubtful if it would amiable enough or what you would call the communicative type, even if some data scientists wouldn’t mind it. As a former program manager though, I would be hesitant in relying solely on it and I would definitely want to keep my data people around even if that system produced more accurate models. I’m writing all this not to discredit the value of existing A.I. system, nor to make fun of their role in the tech world. Quite the contrary. I just want to make the point that if we are to have a truly useful and affable A.I. system that can integrate well in our society, we’ll need to look into making it more communicative. This kind of system I call an alternative artificial intelligence (or A2I for short), since it would require an alternative approach to the A.I. technology. In a nutshell, the design of such a system needs to include (but not limited to) the following features:
All these are a bit high-level but at least they paint a picture of how A.I. could evolve in a more holistic way, so as to be more amicable and less risky. Perhaps an A.I. system like this would convince even the skeptics that A.I. can be not only useful but safe. We can imagine a conversation with a system like this to be like this: Human: What do you think of this client? A2I: I find that Mr. X is a reliable client and that we should continue doing business with them. Human: Are you sure? A2I: I am fairly certain. Human: How sure are you? A2I: About 89% certain. Human: Why would you classify this client as reliable? A2I: Because X’s investments have shown to be of an acceptable ROI. Also, X’s credit score is within acceptable parameters. Furthermore, X’s social profile appears to reflect a person who is positively poised towards your company and does not seem to be interested in your competitors. Human: That’s quite useful. Please put all that in a report so that I can present this insight to the 2:00 meeting. A2I: I’ll be happy to do that, Dave! Human: Who is Dave? A2I: Just making a joke. Thank you for your feedback! So there you have it. An alternative A.I. that is geared towards a synergy between our species and its own. Will that be 100% safe? Probably. However, just like every A.I. system designed, it is bound to be limited to our perception and our values. So, if we were to make it with a collaborative approach in mind instead of winning control over something, the risk of it ever rebelling and taking control would be mitigated. Something to think about… As I hope it’s become abundantly clear throughout this blog, data science is more of a hands-on endeavor than a theoretical science. Even though it does have a solid theoretical foundation, data science was established as a practical discipline. As such, it relies heavily on programming and manipulating data structures, tasks that stem from the effective use of a programming language. Let me clarify here that by programming language I mean an application that allows its user to create executable scripts that can implement algorithms in an efficient way. Therefore, R is not a programming language in that sense, although it is a delightful data analytics platform (particularly for Stats applications). One programming language that is gaining ground as of late is Julia, which despite its quirky name, it seems to be very robust.
Julia language is very much like Python, so if you are a Pythonista like me, you will find it very familiar and intriguing. Basically, it is what Python would be if it were created in this decade (Julia was created around 2012, since that’s when the first references to it came about). However, Python was created two and a half decades ago (in February 1991 to be precise), and as a result, it does not have the merits of a modern language. Specifically, Python is not as fast, nor as data-oriented (even though the Pandas, Scikitlearn, and NumPy packages really add a lot to it in that respect). These inherent limitations of Python and other high-level programming languages of the previous century are addressed in Julia. Its creators, Dr. J. Bezanson and his associates from MIT, put a lot of effort to make a language that is both easy to use and is fast. Just like all other programming languages I know of, Julia is open-source and even its IDEs are free to license. “So what?” you may ask. “We are not programmers, right?” Well, we are indeed not programmers and the way things are going we may never be. However, we can’t do much in data science without programming, just like a physicist can’t do much without math! In fact, this is our niche, in comparison to conventional data analysts and BI professionals (although there are data analysts nowadays who know how to write and run scipts). The thing is that even though we use programming heavily, we don’t really care about the inner workings of a programming language or about the esoteric concepts that accompany it. If I can get my model to achieve a good generalization with the data I have, I don’t care if the lines of code I write to accomplish this is optimum, or whether I could have shaved a few seconds by spending a few hours cleaning up the code. At the end of the day, as long as I can meet my deadlines and have a script that doesn’t spit errors or exceptions left and right, I am a happy camper! Enter Julia. This language is like a God-sent for data science as it is as cool as Python to code in, and saves us a lot of time when running the computationally intensive data wrangling scripts. Surely it does not have the breadth of packages that Python has but hey, it manages to do what I want it to do and for me that’s all that matters. Also, if I need to tweak something or write my own auxiliary functions, applying the fox-like attitude to the craft, that’s not only possible but fairly easy with a language like Julia. Do I need to say more? |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed