 At the end of last month, OpenAI released its latest product, which made (and still makes) waves in the AI arena. Namely, about three weeks ago, ChatGPT made its debut, and before long, it gathered enough traction to outshine its predecessor, GPT3. Since then, many people have started speculating on it and making interesting claims about its capabilities, role in society, business value, and future. But what about the human aspects of this technology? How can ChatGPT affect us as human beings and professionals in the next few years?
Let's start with the latter, as it's generally easier to understand. Whether you identify as a data professional (particularly one in Analytics), a Cybersecurity expert, or just someone interested in these fields, ChatGPT will affect you. As its amoral, it may not understand how any given actions are bound to have consequences on other people, so if you become obsolete because of its work in these areas, it's hard to blame it. After all, it was just trying to be helpful! And all those people who are becoming gradually more addicted to free services, free advice, and anything that doesn't part them from their cash may be bound to feel an attraction to this technology. It's not just translators and digital artists that have real problems with this software, through the rapid increase of the supply and the lowering of the prices of their services as a consequence. If someone could get insights or cybersecurity advice from ChatGPT, it's doubtful they'd consider paying you for the same services plus the additional burden of dealing with a human being. After all, we are all flawed in some way that may trigger others, while the AI system may seem relatively perfect. As resources are becoming more scarce by the year, it's not far-fetched to expect technologies like this one to get a larger share of the market in analytics and cybersecurity services soon. How many people do you know who can tell the difference between some good advice and some not-so-good one when the latter is phrased in flawless English and in a personalized way? And how many people have the maturity to appreciate and opt for the former, just out of principle? As for the effects of ChatGPT on us as human beings, these are also not too promising either. If someone is used to getting whatever they want without paying anything, it's only natural that this person would become spoiled, a taker of sorts, with a growing appetite for more free services. I don't know about you, but I find that I am better off being surrounded by people who are givers or at least matchers instead of takers (I've experienced plenty of the latter in my life, especially as a student). Now, this psychological corrosion may not happen tomorrow or even next year, plus it's unfair to assign all the blame to ChatGPT since other similar technologies do the same. However, what ChatGPT does that no other software has managed before is democratize this free stuff (at least to its users) and give the illusion of knowing everything well enough. In other words, a ChatGPT user may feel that other people are unnecessary and that this software is sufficient for all their knowledge needs. This subjective matter may be untrue, but good luck convincing that person that this is not a good option for them or the world overall! Technologically, ChatGPT may be a brilliant product and one that can open new avenues of research toward a more futuristic society. However, without preserving the human aspects of the world, all this technology is bound to backfire and do more harm than good. Not because suddenly the AI may decide to dominate us, but because we as a species may not be ready for this tech and the rapid changes it can (and probably will) incur. To make things worse, the cost of this tech, although not factored in by the futurists and the evangelists of OpenAI, is still there. It seems paradoxical to me that we try to conserve energy, even in the winter months, because of the rising cost of gas and electricity, even though we allow such an energy-hungry tech to consume large amounts of energy (computational power isn't cheap!). As I don't wish to end this article on a sad note, I'd like to invite you to ponder solutions to this moral problem (something that I sincerely doubt this or any other AI is particularly good at). For additional inspiration, I'd recommend the book The Retro Future by John Michael Greer, which covers this complex topic of progress and technology much better than I can. Maybe ChatGPT is an opportunity for us all to view things from a different (hopefully more holistic) perspective and develop some Natural Intelligence to complement the Artificial Intelligence out there. Cheers.
0 Comments
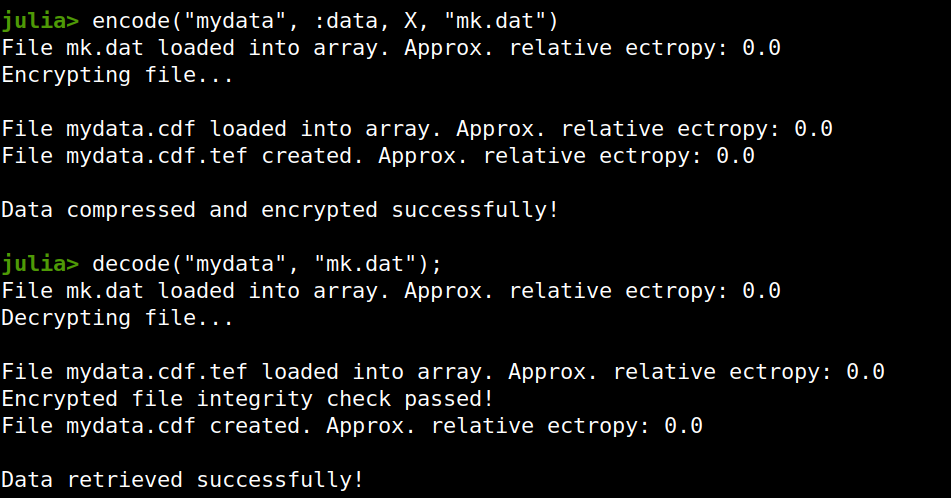
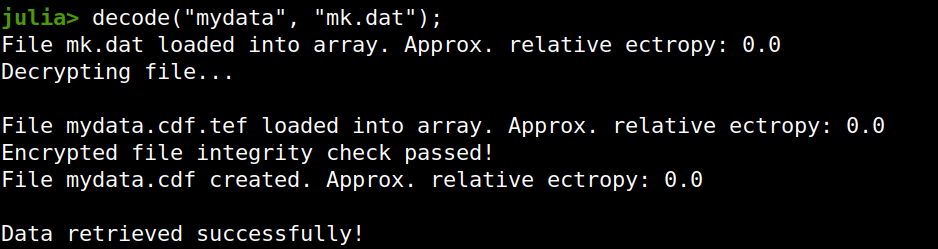
 Lately I published an episode of my podcast where I talk about compression and encryption as privacy tools (link). That’s all nice and dandy but how do we do any of that in practice? Well, most compression programs have an encryption option, which may be sufficient for low-confidentiality documents. But what about datasets that contain lots of PII? And if you are like me, you may use Julia for processing them, since it’s by far the most efficient programming language for the task, that’s also high-level. Enter ComCrypt, a simple script that does high-quality compression and quantum-proof encryption all in one go. Namely, it makes use of the CDF script which I’ve talked about before (it’s been about two years since I created it) for compressing the data into an archive having the .cdf extension (which stands for compressed data format and it’s native to Julia). Then it applies ThunderStorm to it, using an external key file. If anything goes wrong throughout this process, ComCrypt alerts the user with some error message informing about the part that threw the error. Otherwise, it yields a message saying that the data has been compressed successfully. The reverse process shares the same philosophy. Currently, ComCrypt at its first version so its scope is a bit limited (e.g., it handles only a single data object per file). However, there are ways to make it more usable and useful. In any case, it’s already a useful little tool for keeping your data safe when working in the Julia environment. Also, it’s very light on the dependencies (just one external library and a few Julia scripts). Cheers.  I was never into Clustering. My Ph.D. was in Classification, and later on, I explored Regression on my own. I delved into unsupervised learning too, mostly dimensionality reduction, for which I've written extensively (even published papers on it). For some reason, Clustering seemed like a solved problem, and as one of my supervisors in my Ph.D. was a Clustering expert (he had even written books on this subject) I figured that there isn't much for me to offer there. Then I started mentoring data science students and dug deeper into this topic. At one point, I reached out to some data scientists I'd befriended over the years asking them this same question. The best responses I got were that DBSCAN is mostly deterministic (though not exactly deterministic if you look under the hood) and that K-means (along with its powerful variant, K-means++) was lightweight and scalable. So, I decided to look into this matter anew and see if I could clean up some of the dust it has accumulated with my BROOM. Please note that when I started looking into this topic, I had no intention to show off my new framework nor to diminish anyone's work on this sub-fiend of data science. I have great respect for the people who have worked on Clustering algorithms, be it in research or their application-based work. With all that out of the way, let's delve into it. First of all, deterministic Clustering is possible even if many data scientists will have you believe otherwise. One could argue that any data science algorithm can be done deterministically though this wouldn't be an efficient approach. That's why stochastic algorithms are in use, particularly in challenging problems like Clustering. There is nothing wrong with that. It's just frustrating when you get a different result every time you run the algorithm and have to set a random seed to ensure that it doesn't change the next time you use that code notebook where it lives. So, deterministic is an option, just not a popular one. What about being lightweight? Well, if it's an algorithm that requires running a particular process again and again until it converges (like K-means), maybe it's lightweight, but probably not so much since it's time-consuming. Also, most algorithms worth their salt aren't as simple as K-means, which though super-efficient, leaves a lot to be desired. Let's not forget the assumptions it makes about the clusters and its reliance on distance, which tends to fail when several dimensions are present. So, in a multi-dimensional data space, K-means isn't a good option, and just like any other clustering algorithm, it struggles. DBSCAN struggles too, but for a different reason (density calculations aren't easy, and in multi-dimensional space, they are a real drag). So, where does that leave us? Well, this is quite a beast that we have to deal with (the combination of a deterministic process and it being lightweight), so we'll need a bigger boat! We'll need an enormous boat, one armed with the latest weapons we can muster. Since we don't have the computational power for that, we'll have to make do with what we have, something that none of the other brilliant Clustering experts had at their disposal: BROOM. This framework can handle data in ways previously thought impossible (or at least unfeasible). High dimensionality? Check. Advanced heuristics for similarity? Check. An algorithm that features higher complexity without being computationally complex? Check. But the key thing BROOM yields that many Clustering experts would kill for is the initial centroids. Granted that they are way more than we need, it's better than nothing and better than the guesswork K-means relies on due to its nature. 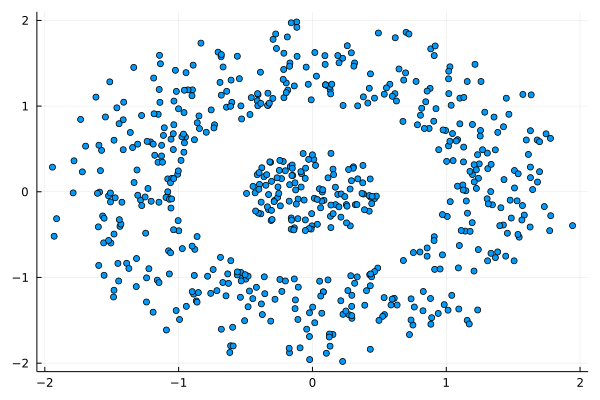 In the toy dataset visualized above, I applied the optimal clustering method I've developed based on BROOM, there were two distinct groups in the dataset across the approximately 600 data points located on a Euclidean plane. Interestingly, their centers were almost the same, so K-means wouldn't have a chance to solve this problem, no matter how many pluses you put after its name. The initial centroids provided by BROOM were in the ballpark of 75, which is way too high. After the first phase of the algorithm, they were reduced to 7 (!) though even that number was too high for that dataset. 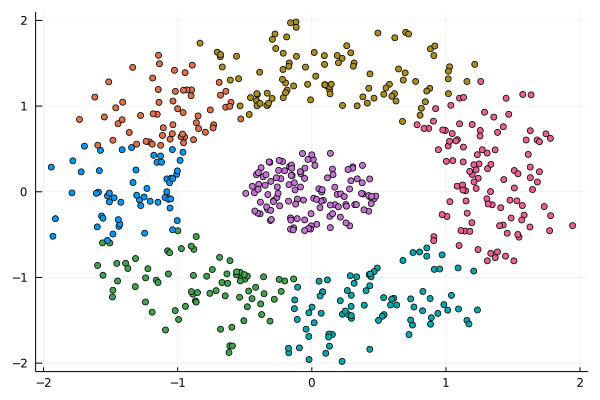 After some refinement, which took place in the second phase of the algorithm, they were reduced to 2. The whole process took less than 0.4 seconds on my 5-year-old laptop. The outputs of that Clustering algorithm included the labels, the centroids, the indexes of the data points of each cluster, the number of data points in each cluster, and the number of clusters, all as separate variables. Naturally, every time the algorithm was run it yielded the same results since it's deterministic. 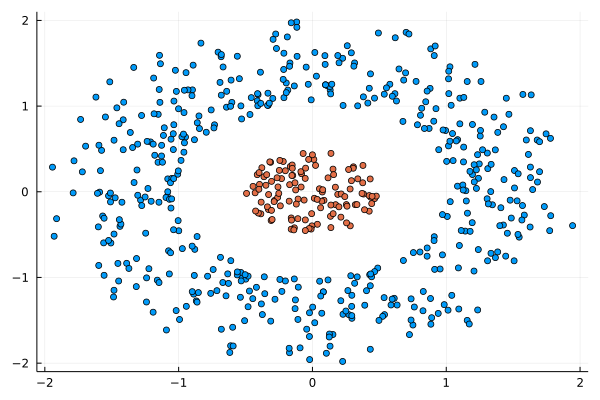 Before we can generalize the conclusions that we can draw from this case study, we need to do further experimentation. Nevertheless, this is a step in the right direction and a very promising start. Hopefully, others will join me in this research and help bring Clustering the limelight it deserves, as a powerful data exploration methodology. Cheers! 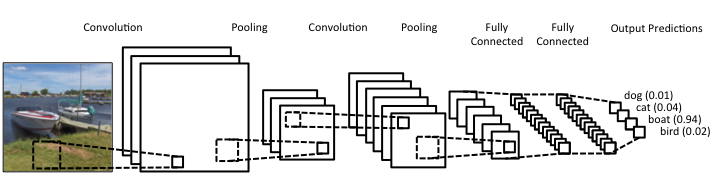 Image originally posted on www.clarifai.com Lately (and I use this term loosely), there's been a lot of talk about deep learning. It's hard to find an article about data science that doesn't mention Deep Learning in one way or another. Yet, despite all its publicity, Deep Learning is still conflated with machine learning by most of the people consuming this sort of article. This misrepresentation can lead to misunderstandings that can be costly in a business setting, as there can be a disconnect between the data science team and the project stakeholders. Let's look into this topic more closely and clarify it a bit. Machine Learning is a relatively broad field that has become an instrumental part of data science. Complementary to Statistics, Machine Learning incorporates a data-driven approach to analyzing data. This approach involves the use of heuristics and predictive models. Most models used by data scientists today tend to fall into this category. Things like Random Forests and Boosted Trees are commonplace and powerful, while they are classic examples of machine learning. But these aren't the only ones, and lately, they have started to give way to other, more powerful models. The latter is in deep learning territory. Deep Learning is part of AI and deals with machine learning problems. It's still an innate part of the AI field, but because of its applicability in Machine Learning, it is often considered to be part of the latter too. After all, AI has spread in various domains these days, and as predictive analytics is one domain where it can add lots of value, its presence there is considerable. In a nutshell, Deep Learning involves large artificial neural networks (ANNs) that are trained and deployed for tackling data science-related problems. There are several such networks, but they all share one key characteristic: they go deep into the data, through the development of thousands of features, in an automated manner, for understanding the intricacies of the data. This sophistication enables them to yield higher accuracy and harness even the weakest signals in the data they are given. Deep Learning has been quite popular lately, not just because of its innovative approach to analytics but primarily because of the value it adds to data science projects. In particular, deep learning systems are versatile and can be used across different domains, given sufficient data and enough diversity in that data. They aren't handy just for images, while newer areas of application are being discovered constantly. Additionally, deep learning systems can do without a lot of data engineering (e.g., feature engineering) since this is something they undertake themselves. In other words, they offer a shortcut of sorts for the data scientists who use them, making their projects more efficient. Finally, deep learning systems can be customized considerably, making them specialized for different domains. That's particularly useful for developing better models geared towards the specific data available to you. Of course, the whole topic of deep learning is much deeper than all this. What's more, despite its usefulness, it's not always appropriate since conventional machine learning is also quite relevant in data science today. Moreover, there are other AI-based systems usable in data science, such as those based on Fuzzy Logic. In any case, there is no one-size-fits-all solution, which is why it's better to be well-versed on the various options out there. A great place to start learning about these options in a hands-on way is my latest book, Julia for Machine Learning, where we tackle various data science problems using various machine learning methods. Check it out when you have a moment!  In a nutshell, Quantum Computing is the computing paradigm that uses quantum properties in computer systems, such as superposition and quantum tunneling. Experts consider quantum computing quite advanced and the state-of-the-art of computing today, even if the specialized hardware it uses makes it a bit of a niche case study. Despite its numerous merits, quantum computing is not a panacea, even though it is considered relevant in our field, particularly in A.I. This article will explore this relationship, where Q.C. is right now, and where you can access it. Quantum computers' performance is usually measured in Qubits (quantum bits) instead of traditional bits. Each qubit is a quantum particle in superposition and corresponds to the more rudimentary piece of data a quantum computer can handle. Qubits are not easy to maintain, and when they work in tandem, it's quite probable for the superposition to collapse unexpectedly, resulting in errors in the computations involved. So, having a certain number of qubits (the larger, the better) in a computer is quite an accomplishment. Larger numbers enable quantum computer users to tackle more challenging problems, potentially adding more value to the project at hand. Right now, quantum computing is at a stage where the number of qubits they can handle is in the two digits. For example, IBM's quantum machine boasts 65 qubits, although the company has plans for much larger numbers soon (they expect to have a quantum machine with 1000+ qubits by 2023). However, it's important to note that each company uses a somewhat different approach, meaning that the qubits in each computer they produce are not directly comparable to each other. Now, what about the potential disruption in data science and A.I. work due to quantum computing? Well, since our field often involves lots of heavy computations, some of them around NP-hard problems in combinatorics (e.g., selected the optimal set of features from a feature set), it can surely gain from quantum computers. That's not to say, however, that every data science or A.I. project can experience a boost from the Q.C. world. Simpler models and standard ETL work are bound to remain the same while using a quantum machine for them would waste these pricy computational resources. So, it's more likely that a combination of traditional computing and quantum computing will be normal once quantum machines become more commonplace. Additionally, for optimization-related problems, particularly those involving many variables, quantum computing may have a lot to offer. Still, whether it's worth the price is something that needs to be determined on a case-by-case basis. Let’s now look at the various quantum computing vendors out there. For starters, we have Amazon with its AWS Quantum Computing center at Caltech. Microsoft is also a significant player, with its Azure Quantum service, utilizing a specialized language (Q#). IBM is a key player, too, along with D-Wave Systems, the two being the first to develop this technology. Google Research is Alphabet's division for this tech and is now also a player in this area. What's more, there are hardware companies too in this game, such as Intel, Toshiba, and H.P. Naturally, all the companies that have developed their Q.C. product enough to make it available do so via a cloud, since it's much more practical this way. For those who like the cloud but don't have the budget or the project that lends itself to quantum machines, the Hostkey cloud provider relies on conventional computers, including some with GPUs onboard. You can learn more this and other relevant topics to A.I. and data science, though my book A.I. for Data Science: Artificial Intelligence Frameworks and Functionality for Deep Learning, Optimization, and Beyond. In this book, my co-author and I cover various aspects of data science work related to A.I., as well as A.I.-specific topics, such as optimization. What’s more, the book has a hands-on approach to this subject, with lots of code in both Python and Julia. So, check it out when you can. Cheers!  Ever since machine learning and artificial intelligence (A.I.) became mainstream, there has been a lot of confusion between the two and how they relate to data science. Considering how superficial the mainstream understanding of the subject is, it's no wonder that many people who first learn about data science consider them the same. However, if you are to learn data science in-depth and do something useful with it, it's best to know how to differentiate between the two and know when to use what, for the problem at hand. To disambiguate the two, let’s look at what each one of them is. First all, machine learning is a set of methodologies involving a data-driven approach to data modeling as well as the evaluation of the data at hand. It includes various models like decision trees, support vector machines, etc. as well as a series of heuristics. The latter is used for assessing features or models in a way that's void of any assumptions about the distributions of the data involved. Machine learning sometimes makes use of basic Stats but it is a separate field altogether, part of the core of data science. Some machine learning models are based on A.I. though most of them are not. As for artificial intelligence, it is a field separate from data science altogether. It involves systems that emulate sentient behavior, in various domains. Computer Vision, for example, is a part of A.I. that involves interpreting images (usually captured by a camera or a video stream) to understand what objects are in the vicinity. Natural Language Processing (NLP) involves looking at a piece of text and working out what it is about or even synthesizing text on the same topic. Naturally, there is an overlap between A.I. and machine learning (as in the case of deep learning models), though this is fairly limited. For example, advanced optimization methods are a key application of A.I. that has nothing to do with machine learning per se, even if it is sometimes employed in the more advanced models. Beyond the differences that emerge from the above descriptions of the two fields, there are a few more that's worth keeping in mind. Namely, machine learning models can often be interpreted, at least to some extent. On the other hand, (modern) A.I. models are black boxes, at least for the time being. What's more, machine learning models come in a variety of types, while A.I. ones are graph-based. Additionally, A.I. has a more diverse range of applications, while machine learning is limited to specific ways that are related to data science work. Finally, in machine learning, you need to do some data engineering before you work your models, while in A.I. it's rarely the case (even though it can be very helpful). If you are interested in this topic (particularly classical machine learning), you learn more about it through my book Julia for Machine Learning, published last Spring. This book is very hands-on, having plenty of examples that illustrate how machine learning methods work, be if for data engineering or data modeling tasks. The language used (Julia) is an up-and-coming data science language that boasts several packages under the machine learning umbrella. In this book, we explore the most important of them, which have stood the test of time. Check it out when you have the chance. Cheers!  Graphic cards deal with lots of challenging operations related to the number-crunching of image and video data. Since the computer's CPU, which traditionally manages this sort of task, has lots of stuff on its plate, it's usually the case that the graphics card has its own processor for handling all the data processing. This processor is referred to as GPUs (a CPU specializing in graphics data) and plays an essential role in our lives today, even when we don't care about the graphics on our computer. As we've seen in the corresponding book I've co-authored, it's crucial for many data science and AI-related tasks. In this article, we'll look at the latest information on this topic. First thing's first: data science and A.I. needing GPUs is a modern trend, yet it's bound to stick around for the foreseeable future. The reason is simple: many modern data science models, especially those based on A.I. (such as large-scale Artificial Neural Networks, aka, Deep Networks), require lots of computing power to train. This additional computing requirement is particularly the case when there is lots of data involved. As CPUs come at a relatively higher cost, GPUs are the next best thing, so we use them instead. If you want to do all the model training and deployment on the cloud, you can opt for servers with extra GPUs for this particular task. These are referred to as GPU servers and are a decisive factor in data science and A.I. today. What's the catch with GPUs, though? Well, first of all, most computers have a single graphics card, meaning limited GPU power on them. Even though they are cheaper than CPUs, they are still a high cost if you have large DNNs in your project. But the most critical impediment is that they require some low-level expertise to get them to work, even though it's simpler than building a computer cluster. That's why more often than not, it makes more sense to lease a GPU server on the cloud rather than build your own computer configuration utilizing GPUs. Besides, the GPU tech advances rapidly, so today's hot and trendy may be considered obsolete a couple of years down the road. Beyond the stuff mentioned earlier, there are some useful considerations that are good to have in mind when dealing with GPUs in your data science work. First of all, GPUs are not a panacea. Sometimes, you can get by with conventional CPUs (e.g., standards cloud servers) for the more traditional machine learning models and the statistical ones. What's more, you need to make sure that your deep learning framework is configured correctly and leverages the GPUs as expected. Additionally, you can obtain extra performance from GPUs and CPUs if you overclock them, which is acceptable as a last resort if you need additional computing power. For GPU servers that are state-of-the-art yet affordable, you can check out Hostkey. This company fills the GPU server niche while providing conventional server options for your data science projects. Its key advantage is that it optimizes the performance/cost metric, meaning you get a bigger bang for your buck in your data models. So, check it out when you have a moment. Cheers!  A data scientist A.I. is an A.I. system that can undertake data science work end-to-end. Systems like AutoML are in this category and it seems that the trend isn’t going to go away any time soon. After all, a data scientist A.I. is better value for money and a solution that can scale very well. Amazon, for example, makes use of such systems to ensure that you view a personalized page based on your shopping and viewing history on the well-known e-commerce website. But how feasible is all this for those not having Amazon’s immense resources? Well, A.I. systems like this are already available to some extent with the only thing missing is data. There are even people in data science who - in lack of another way to describe them - are short-sighted enough to implement them, effectively irreversibly destroying our field. So, once a critical mass of users have enough data to get such a system working well, the question of feasibility would give way to things like "how profitable is it?" or "will it be able to handle the work of other data professionals too?" What about responsibility and liability matters though? Well, A.I. systems may do a great many things but taking responsibility is not one of them. As for when things get awry and there are legal issues, they cannot be held liable. As for the companies that developed them, well, they couldn’t care less. So, if you are using an A.I. system as a data scientist, you are effectively shouldering all the responsibility yourself, all while insulating yourself from any intervention capabilities. In other words, you need to trust the damn thing to do its job right, all while the data you give it may be biased in various ways, something no A.I. system has managed to handle yet. So, what’s the bottom line in all this? Well, A.I. systems may undertake a lot of data science work successfully, but they cannot (at least at this time) be data scientists, no matter what the companies behind these systems promise. There is no doubt that A.I. is a useful tool in data science work, but you still need a human being, particularly one with some understanding of how an organization works, to be held responsible for the data science projects. Even if A.I. is leveraged in these projects at least there is someone to answer for the results, particularly if there are privacy violations or biases involved. If you want to learn more about data science and AI’s role in it, feel free to check out the AI for Data Science book I’ve co-authored a couple of years ago. This book, published by Technics Publications, covers a series of AI-related methodologies related to data science, such as deep learning, as well as others that are more generic, such as optimization. The book is supplemented by Jupyter notebooks in Python and Julia and lots of examples. Check it out when you have a moment!  I've talked a lot about GPUs and their value in data science and AI work, but let's look at the numbers. In this article I learned about recently, various servers equipped with state-of-the-art graphics cards are tested for certain common AI-related tasks. If it piques your interest, you can check out the actual server leasing options Hostkey offers. More information on that, here or in the corresponding page of this site. Cheers!  Text analytics is the field that deals with the analysis of text data in a data science context. Many of its methods are relatively simple since it's been around for a while now. However, more modern models are quite sophisticated and involve a deeper understanding of the texts involved. A widespread and relatively popular application of text analytics is sentiment analysis, which has grown significantly over the past few years. Also, its evolution, which involves the understanding of a text's tone and other stylistic aspects, has made it possible to assess text in different ways, not just as a positive-negative sentiment only. The sophistication of text analytics is mainly due to artificial intelligence in it, especially deep learning (DL) and natural language processing (NLP). The latter ensures that the text is appropriately evaluated, taking into account syntax and grammar and parts-of-speech and other relevant domain knowledge of linguistics. It also employs heuristics like the TF-IDF metric and frequency analysis of n-grams (combining n different terms forming common phrases). All these yields a relatively large feature set that needs to be analyzed for patterns before a predictive model is build using it. That's where DL comes in. This form of A.I. has evolved so much in this area that there exist DL networks nowadays that can analyzed text without any prior knowledge of the language. This growth of DL makes text analysis much more accessible and usable, though it's most useful when you combine DL with NLP. The usefulness of text analytics, mainly when A.I. is involved, is undeniable. This usefulness has driven change in this field and advanced it more than most data science use cases. From comparing different texts (e.g., plagiarism detection) to correcting mistakes, and even creating new pieces of text, text analytics has a powerful niche. Of course, it's always language-specific, which is why there are data scientists all over the world involved in it, often each team working with a particular language. Naturally, English-related text analytics has been more developed, partly because it's more widespread as a language. Because of all that, text analytics seems to remain a promising field with strong trends towards a future-proof presence. The development of advanced A.I. systems that can process and, to some extent, understand a large corpus attest to that. Nowadays, such A.I. systems can create original text that is truly indistinguishable from the text written by a human being, passing the Turing test with flying colors. A great application of text analytics that is somewhat futuristic yet available right now is Grammarly. This slick online application utilizes DL and NLP to assess any given text and provide useful suggestions on improving it. Whether the text is for personal or professional use, Grammarly enables it to deliver the message you intend it to, without any excessive words. Such a program is particularly useful for people who work with text in one way or another and are not super comfortable with English. Even the free version of it is useful enough to make it an indispensable tool for you. Check it out when you have the chance by installing the corresponding plug-in on your web browser! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed