 Remember all those videos I used to make for Safari / O'Reily's Learning platform? Well, most of them are now gone but the best ones (according to the publisher) are still available for you, in a pay-per-view mode. Learn more about them through this 1-minute video I made about them. It's just six of them at the moment, but I may get more of them out there in the months to come. Cheers
0 Comments
 Recently a new educational video platform was launched on the web. Namely, Pebble U (short for Pebble University) made its debut as a way to provide high-quality knowledge and know-how on various data-related topics. The site is subscription-based, while it requires a registration for watching the videos and any other material available on it (aka pebbles). On the bright side, it doesn't have any vexing ads! Additionally, you can request a short trial of it, for some of the available material, before you subscribe to it. Win-win! Pebble U has a unique selection of features that are very useful when consuming technical content. You can, for example, make notes and highlight parts and add bookmarks, on the books you read. As for the videos, many of them are accompanied by quizzes to embed your understanding of the topic covered. The whole platform is also available as an app for both Android and iOS devices. The topics of Pebble U cover data science (particularly machine learning and A.I., though there are some Stats related videos too), Programming (particularly Python), and Business, among other categories. As the platform grows, it is expected to include additional topics and a larger number of content creators. All the videos are organized in meaningful groups called disciplines, making it easy to build on your knowledge. Of course, if you care for a particular discipline only, you can subscribe to material of that area only, saving you some money. 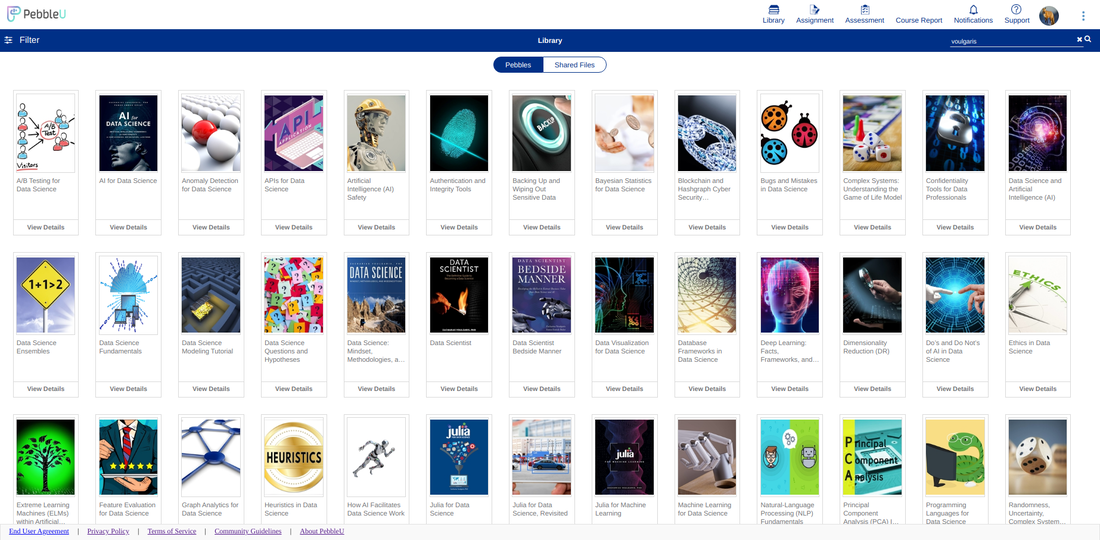 In the screenshot above, you can see some of my own material that are available on PebbleU right now. Many of them are from my Safari days, but there are also some newer ones, particularly on the topic of Cybersecurity. By the way, if you find the subscription price a bit steep, remember that you can use the coupon code DSML I've mentioned in previous posts, to get a 20% discount. So, check it out when you have some time. This may be the beginning of something great!  There is a certain kind of information in the world of data that makes it possible to identify particular individuals personally. In other words, there is a way to match a specific person to a data record based on the data alone. Such data is referred to as personally identifiable information (PII), and it's crucial when it comes to data science and data analytics projects. After all, PII's leakage would put those individuals' privacy at risk, and the organization behind the data could get sued. In this article, we'll look at a couple of popular methodologies for dealing with PII. Fortunately, Cybersecurity as a field was developed for tasks like this one. Anything that has to do with protecting information and privacy falls under this category of methods and methodologies. Since PII is such an important kind of information, several cybersecurity methodologies are designed to keep it safe and the people behind this information. The most important such methodologies are anonymization and pseudonymization. These methodologies aim to either scrap or conceal and PII-related data, securing the dataset in terms of privacy. Let’s start with anonymization. This Cybersecurity methodology involves scrapping any PII from a dataset. This methodology involves any variables containing PII (e.g., name, address, social security number, financial information, etc.) or any combination of variables closely linked to PII (e.g., medical information with general location data). Although this can ensure to a large extent that PII is not abused, while it also makes the dataset somewhat lighter and easier to work with, it's not always preferable. After all, the PII fields may contain useful information for our model, so discarding it could distort the dataset's signal. That's why it's best to use this methodology for cases when the PII variables aren't that useful, or they contain very sensitive information that you can't risk leaking out. As for pseudonymization, this is a Cybersecurity methodology that entails the masking of PII through various techniques. This way, all the relevant information is preserved in some form, although deriving the original PII fields from it is quite challenging. Although this Cybersecurity methodology is not fool-proof, it provides sufficient protection of any sensitive information involved, all while preserving the dataset's signal to a large extent. A typical pseudonymization method is hashing, whereby we hash each field (often with the addition of some "salt" in the process), turning the sensitive data into gibberish while maintaining a one-to-one correspondence with the original data. Beyond anonymization and pseudonymization, several other Cybersecurity methodologies are worth knowing about, even if you only delve in data science work. If you want to learn more about this topic, including how it ties in the whole Cybersecurity ecosystem, you can check out my latest video course: (Fundamentals of) Anonymization and Pseudonymization for Data Professionals on WintellectNow. So, check it out when you have a chance. Cheers!  Hello everyone and happy new year! I hope you all had a good holiday break. I thought about it quite a bit and I've decided this year to go a different direction with the videos I make as I plan to focus more on courses. Stay tuned for more news on this matter in the weeks to come... Throughout this blog, I've talked about all sorts of problems and how solving them can aid one's data science acumen as well as the development of the data science mindset. Problem-Solving skills rank high when it comes to the soft skills aspect of our craft, something I also mentioned in my latest video on O'Reilly. However, I haven't talked much about how you can hone this ability.
Enter Brilliant, a portal for all sorts of STEM-related courses and puzzles that can help you develop problem-solving, among other things. If you have even a vague interest in Math and the positive Sciences, Brilliant can help you grow this into a passion and even a skill-set in these disciplines. The most intriguing thing about all this is that it does so in a fun and engaging way. Naturally, most of the stuff Brilliant offers comes with a price tag (if it didn't, I would be concerned!). However, the cost of using the resources this site offers is a quite reasonable one and overall good value for money. The best part is that by signing up there you can also help me cover some of the expenses of this blog, as long as you use this link here: www.brilliant.org/fds (FDS stands for Foxy Data Science, by the way). Also, if you are among the first 200 people to sign up you'll get a 20% discount, so time is definitely of the essence! Note that I normally don't promote anything of this blog unless I'm certain about its quality standard. Also, out of respect for your time I refrain from posting any ads on the site. So, whenever I post something like this affiliate link here I do so after careful consideration, opting to find the best way to raise some revenue for the site all while providing you with something useful and relevant to it. I hope that you view this initiative the same way.  So, recently I decided to make a video on this topic, based on some things I've observed in data science candidates. The hope is that this may help them and anyone else who may be looking into becoming a more holistic data scientist, instead of just a data science technician. The video I made is now available online on O'Reilly and although it's a bit longer than others I've made (not counting the quiz ones), it's fairly easy to follow. Enjoy!
 Alright, the quiz video fever is over for the time being, so I'm back to making conventional data science videos. This latest one on APIs, for example, just got published on O'Reilly. It's more technical than others, but very useful, particularly if you know already a few things about data science. Anyway, I hope you enjoy it! Note that although you can view the list of videos and books on O'Reilly's learning platform, you need to have a valid account in order to view them in their entirety. A pretty good investment, if you ask me, but before you commit to a monthly or a yearly subscription, you can always have a trial one which lasts for 10 days. Cheers!  So, the 7th quiz video I've created is finally online on O'Reilly. This is the longest one so far spanning over 51 minutes, meaning there are lots of explanations for the various questions. It covers a bunch of topics, such as A/B testing, ANOVA, and various statistical tests. I put a lot of thought in this, much like you'd put a lot of thought in designing a data science experiment. Hopefully, you'll find it as useful and enjoyable as I did. Note that just like other videos published on O'Reilly, you'll need to have an active account (even if it's a trial one), in order to view it in its entirety. As a bonus, you'll be able to view other videos as well as books available on that platform. Enjoy!  Lately I've been down with a severe case of quiz fever! Combined with the fact that it was too hot to go outside (Mediterranean summer heat is no joke!), I was more focused on this task. As a result, I created a bunch of quizzes to publish on O'Reilly, two of which are now online. Namely, the Data Engineering and the Machine Learning Applications one are now available on the O'Reilly platform. Check them out when you have the chance. Note that in order to have full access to the quizzes, you need an account with O'Reilly, a pretty good investment. If you are unsure whether you want to go for it, you can always create a trial account first (valid for 10 days) and check out the content of this great platform, without any strings attached. However, to maximize your benefit, I recommend you get a paid account. The plethora of quality content on this platform makes it worth it! Furthermore, I recently noticed that my videos are receiving lots of hits and have fetched some very promising reviews. I'd like to thank you all for that. It's a relatively small thing for everyone of you to take the time out of your busy day and watch my work and you may not think much of it. However, it does make a difference to me, so I'm grateful for that. At a time when YouTube is the go-to option for many people, some of you choose quality over convenience and that's something I never take for granted. Cheers!  Since I'm in a quiz frame of mind these days, I've created yet another quiz video, which is now available on the O'Reilly platform. Namely, this quiz on Machine Learning vid explores a few key aspects of the subject, such as supervised, unsupervised and reinforcement learning, as well as the main model types and the hyper-parameters involved. Designed to be as inclusive as possible, this is a video that can benefit both the beginner to this topic and the more seasoned machine learning professional. Enjoy! Note that O'Reilly is a subscription based platform (formerly known as Safari). So, in order to view this or any other video in its entirety, you'll need to have an account there. Definitely a worthwhile investment, if you ask me, particularly if you are a data science professional. I don't receive any benefits from saying this, btw, since I work with a different publisher (Technics Publications), who contributes these videos to this platform. |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed