 Contrary to what the image suggests, this article is about the born again shell, aka BASH. BASH is essential in any serious work on the GNU/Linux OS, which believe it or not is by far the most popular OS in the world, considering that the vast majority of servers run on it. Also, Linux-based OSes are popular among data scientists due to the versatility they offer, as well as their reliable performance. BASH is the way you interact with the computer directly when using a GNU/Linux system. In a way it is its own programming language, one that is on par with all the low-level languages out there, such as C. BASH is ideal for ETL processes, as well as any kind of automation. For example, the Cron jobs you may set up using Crontab are based on BASH. Of course, nothing beats a good graphical user interface (GUI) when it comes to ease-of-use, which is why most Linux-based OSes make use of a GUI too (e.g. KDE, Gnome, or Xfce). However, it's the command-line interface (CLI) that's the most powerful between the two. Also, the CLI is more or less the same in all Linux-based OSes and makes use of commands that are almost identical to those on the UNIX system. The programmatic framework of all this is naturally the BASH. BASH is not for the fainthearted, however. Unlike most programming languages used in data science (e.g. Python, Julia, Scala, etc.), BASH is not as easy to work with as it has an old-school kind of style. However, if you are proficient in any programming language, BASH doesn't seem so daunting. Also, scripts that are written in it as super fast and can do a lot of useful tasks promptly. Yet, even without getting your hands dirty with scripting on BASH, you can do a lot of stuff using aliases, which are defined in the .bash_aliases file. A cool thing about BASH is that you can call it through other programming environments too. In Julia, for example, you can either go directly to the shell using the semi-colon shortcut (;), or you can run a BASH command using the format run(`command`). Note that for this to work you need to use the appropriate character to define the command string (`). Interestingly, a lot of the commands in Julia are inspired by the BASH (e.g. pwd() is a direct reference to the pwd BASH command). So, if you are comfortable with Julia, you’ll find the BASH quite accessible too. Not easy, but accessible. Tools like BASH may not be easy to master (I’m still working on that myself, after all these years) but they can be useful even if you just know the basics. For example, it doesn’t take too much expertise to come up with a useful script that can speed up processes you normally use. For example, the RIP script I created recently can terminate up to three different processes that give you a hard time (yes, even in Linux-based OSes sometimes a process gets stuck!). Also, you can have another script to facilitate backups or even program updates and upgrades. The sky is the limit! All this may seem irrelevant to data science and A.I. work but the more comfortable you are with low-level programming like BASH, the easier it is to build high-performance pipelines, bringing your other programs to life. After all, you can’t get closer to the metal than with BASH, without using a screwdriver!
0 Comments
 Suppose we have an advanced AI system (e.g. an AGI) which is now proven to be safe enough to use on general-purpose scenarios. This system can do all sorts of things, including finding the optimal stance on a matter, given the data available on the subject. Fortunately, everyone who manages the corresponding databases has agreed to let this AI access and analyze this data, so long as it acknowledges the generous contributors of this data. So, data abundance is a given in this hypothetical scenario. Now, with this data and the immense computing resources this AI has at its disposal, it can sort out any controversial topic and come up with a mathematically sound solution that is valid beyond any doubt, given the data at hand. The question is would you trust this result, even if it is probably beyond your understanding, and accept this as the “right answer” to the controversial topic in question? Let's make this more concrete. Suppose that we are dealing with a fairly realistic situation where we have a settlement in some inhospitable environment (e.g. a research center in Antarctica or on the ISS). Due to unforeseeable circumstances, there aren't sufficient resources to save everyone and everything from that place. So, someone has to decide whether they should save all the scientific samples that these people have spent years accumulating and/or analyzing, or the scientists themselves? Or perhaps a combination of the two, prioritizing senior scientists, for example. Obviously, this isn't a decision that anyone would be comfortable making, especially if that person has a conscience. However, an AI system may be more than happy to provide a solution to this problem. A clear-cut solution may be unfathomable to us but for that AI (which has access to all sorts of data, not just the data specific to the problem at hand), it's a much more feasible task. Yet, we may not like what the AI's solution is. Would we accept it nevertheless? Who shall we attribute responsibility to for this scenario? Thinking about things like that may not help anyone gain a better understanding of the ins and outs of AI technology. However, someone could argue that solving this sort of conundrums is as important as sorting out the technical aspects of AI. After all, at one point, probably sooner rather than later, we may have to deal with real-world situations akin to this thought experiment. So, preparing ourselves for this is definitely a worthwhile task, even if it seems challenging or futile, depending on who you ask. There is no doubt that AIs help us solve all sorts of problems and we can outsource a large variety of tasks to them. Soon, an AI may be able to undertake even high-level responsibilities. It is doubtful, however, that it can act ethically if we are not able to do the same ourselves. And we don't need an AI to know that with sufficient certainty. Cheers!  Being an author has many benefits, some of which I’ve mentioned in a previous article. After all, an author (particularly a technical author) is more than just a writer. The former has undergone the scrutiny of the editing process, usually undertaken by professionals, while a writer may or may not have done the same. Also, an author has seen a writing project to its completion and has gotten a publisher to put his or her stamp of approval on that manuscript, before making it available to a larger audience. This raises the stakes significantly and adds a great deal of gravity to the book at hand. Being an author is its own reward (even though there are other tangible rewards to it too, such as the royalties checks every few months!). However, there is a benefit that is much less obvious although it is particularly useful. Namely, an author can appreciate other authors more and learn from them. This is something that I have come to learn since my first book, yet this appreciation has reached new heights since then. This is especially the case when it comes to veteran authors who have developed more than one book. All this leads to an urge to read more books and get more out of them. This is due to the value an author puts into these books. Instead of just a collection of words and ideas, he views a book as a sophisticated structure comprising of many layers. Even simple things like graphics take a new meaning. Of course, much of this detailed view of a book is a bit technical but the appreciation that this extra attention contributes to is something that lingers for long after the book is read. Nevertheless, you don't need to be an author to have the same appreciation towards other people's books. This is something that grows the more you practice it and can evolve into a sense of discernment distinguishing books worth having on your bookshelf from those that you are better off leaving on the store! At the very least this ability can help you save time and money since it can help you focus on those books that have the most to offer to you. In my experience, Technics Publications has such books worth keeping close to you, particularly if you are interested in data-related topics. This includes data science but also other disciplines like data modeling, data governance, etc. There is even a book on Blockchain, which I found very educational when I was looking into this technology, which goes beyond its cryptocurrency applications. Anyway, since good books come at a higher cost, you may want to take advantage of a special promo the publisher is doing, which gives you a 20% discount for all books, except the DMBOK ones. To get this discount, just use the DSML coupon code at the checkout (see image below). 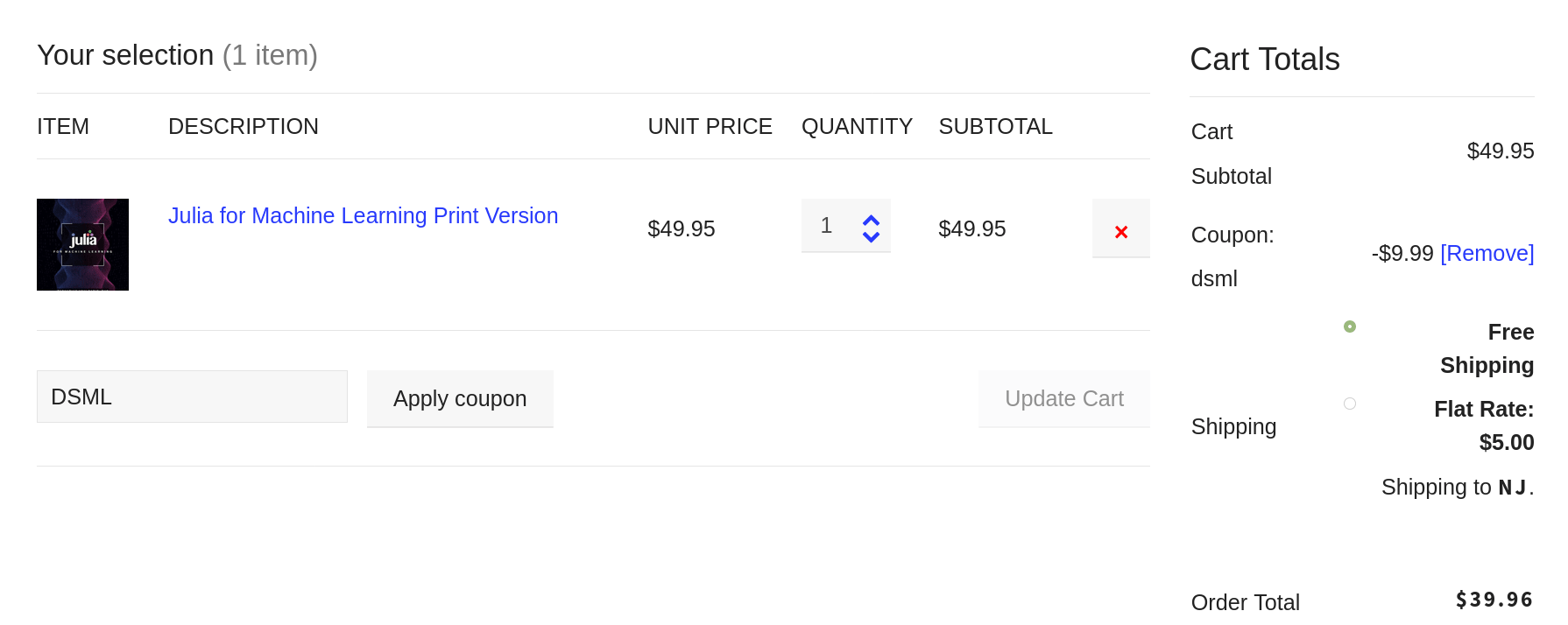 Note that this coupon code applies to virtual classes offered by Technics Publications (i.e. the virtual training courses in the ASK series). This, however, is a topic for another article. Cheers!  Lately, I've been working with Julia a lot, partly because of my new book which was released a couple of weeks ago and partly because it's fun. If you are somewhat experienced with data handling, you'll probably familiar with the JLD and JLD2 packages that are built on top of the FileIO one. Of these, JLD2 is faster and generally better but it seems that it's no longer maintained, while the files it produces are quite bulky. This may not be an issue with a smaller dataset but when you are dealing with lots of data, it can be quite time-consuming to load or save data using this package. Enter the CDF framework, which is short for Compressed Data Format. This is still work in progress so don’t expect miracles here! However, I made sure it can handle the most common data types, such as scalars of any type (including complex string variables), the most common arrays (including BitArrays) for up to two dimensions, and of course dictionaries containing the above data structures. It does not support yet tensors or any kind of Boolean array (which for some bizarre reason is distinct from the BitArray data structure). CDF has two types of functions within it: those converting data into a large text string (and vice versa) and those dealing with IO operations, using binary files. The compression algorithm employed is the Deflate one from the CodecZlib package as it seems to have better performance than the other algorithms in the package. Remember that all of these algorithms take a text variable as an input, which is why everything is converted into a string before compressed and stored into a data file. The CDF framework doesn't have many of the options JLD2 has but for the files created with it, the performance edge is quite obvious. A typical dataset can be around 20 times smaller and many times faster to read or write, as the compression algorithm is fairly fast and there is fewer data to process with the computationally heavy IO commands. As a codebase, CDF is significantly simpler than other packages while the main functions are easy as pie. In fact, the whole framework is quite intuitive that there is not really any need for documentation for it. If you are interested in using this framework and/or extending it, feel free to contact me through this blog. Be sure to mention any affiliation(s) of yours too. Cheers!  Although it's fairly easy to compare two continuous variables and assess their similarity, it's not so straight-forward when you perform the same task on categorical variables. Of course, things are fairly simple when the variables at hand are binary (aka dummy variables), but even in this case, it's not as obvious as you may think. For example, if two variables are aligned (zeros to zeros and ones to ones), that’s fine. You can use Jaccard similarity to gauge how similar they are. But what happens when the two variables are reversely similar (the zeros of the first variable correspond to the ones of the second, and vice versa)? Then Jaccard similarity finds them dissimilar though there is no doubt that such a pair of variables may be relevant and the first one could be used to predict the second variable. Enter the Symmetric Jaccard Similarity (SJS), a metric that can alleviate this shortcoming of the original Jaccard similarity. Namely, it takes the maximum of the two Jaccard similarities, one with the features as they are originally and one with one of them reversed. SJS is easy to use and scalable, while its implementation in Julia is quite straight-forward. You just need to be comfortable with contingency tables, something that’s already an easy task in this language, though you can also code it from scratch without too much of a challenge. Anyway, SJS is fairly simple a metric, and something I've been using for years now. However, only recently did I explore its generalization to nominal variables, something that’s not as simple as it may first seem. Applying the SJS metric to a pair of nominal variables entails maximizing the potential similarity value between them, just like the original SJS does for binary variables. In other words, it shuffles the first variables until the similarity of it with the second variable is maximized, something that’s done in a deterministic and scalable manner. However, it becomes apparent through the algorithm that SJS may fail to reveal the edge that a non-symmetric approach may yield, namely in the case where certain values of the first variable are more similar toward a particular value of the second variable. In a practical sense it means that certain values of the nominal feature at hand are good at predicting a specific class, but not all of the classes. That's why an exhaustive search of all the binary combinations is generally better, since a given nominal feature may have more to offer in a classification model if it's broken down into several binary ones. That's something we do anyway, but this investigation through the SJS metric illustrates why this strategy is also a good one. Of course, SJS for nominal features may be useful for assessing if one of them is redundant. Just like we apply some correlation metric for a group of continuous features, we can apply SJS for a group of nominal features, eliminating those that are unnecessary, before we start breaking them down into binary ones, something that can make the dataset explode in size in some cases. All this is something I’ve been working on the other day, as part of another project. In my latest book “Julia for Machine Learning” (Technics Publications) I talk about such metrics (not SJS in particular) and how you can develop them from scratch in this programming language. Feel free to check it out. Cheers! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed