 Happy holidays everyone! I hope you have a chance to relax, recuperate, and rejuvenate this holiday period :-) See you in 2019 with new, insightful, and fox-like blog posts!
0 Comments
 Lately I worked on a more ambitious topic for a data science video. Graph Analytics, aka Network Analytics, is one of the more niche aspects of our craft and although I've been using it for many years, creating a video on the topic has always been daunting due to the amount of material it has. However, I managed to create a fairly succinct clip (a bit less than half an hour long) and put it out there through my publisher. You can find it on the Safari portal. Note that you will need a subscription to Safari in order to view it in its entirety. Also, a subscription to this educational platform enables you to have access to a bunch of different material, including all of my books. Cheers!  Although I’ve always been a big fan of online videos and find many such projects entertaining to watch, I’ve never really seriously considered doing anything on YouTube. That’s despite the fact that I’m fully aware that some people are making a living on this endeavor. First of all, YouTube has changed dramatically over the years and not for the better. Specifically, the algorithm used for featuring what’s hot on the YouTube homepage has degraded drastically, in a desperate effort to promote “fresh” content creators. In other words, if a producer doesn’t publish videos frequently, they are not promoted much by the algorithm, something that inevitably gives rise to sloppy and cheap content, created merely to satisfy that mindless algorithm. Of course many YouTube fanatics (or YouTubers as they like to call themselves) have their own channels and networks of promoting their stuff, so they get some views regardless. However, the effort it takes to build such a network and the fact that it require constant work to keep it active, makes the whole process inefficient and problematic in many ways. In addition, YouTube has started to filter its content in an effort to block offensive videos from being made available. It’s not that the company gives a damn about what you view since there is already a plethora of super low quality videos over there, but it wants to avoid lawsuits. So, in a desperate effort to save its ass, YouTube has aggressively started filtering its content through any means necessary. This includes having its own unpaid workers, some dedicated users that have nothing else to do with their time, to do this deed for YouTube. Of course these people are not trained while the guidelines they have been given are vague at best. So, it’s up to their limited discernment to figure out what constitutes a bad video and what doesn’t, so what they flag is oftentimes seemingly random. This way, many legitimate videos have been filtered as inappropriate just because some idiot couldn’t tell what they were about. This resulted to the corresponding producer not receiving any revenue from these videos, despite the amount of work he/she has put into these projects. Moreover, the revenue YouTubers make from a single video is not that high, unless the video goes viral. What’s worse, the revenue decreases exponentially since just the most recent and most popular videos attract enough viewership. Who cares about something that was published a year ago, right? Well, wrong. If a video is of a certain quality standard, it is bound to be good to watch even after a year or two after its release date. Then again, most YouTubers have given up on quality videos since those take a lot of time and they need to get something online soon, if it is going to be fresh. So, since I don't have a whole crew working for me, if I were to do YouTube videos I'd make a fairly small income from the videos themselves, unless of course I were to have some sponsor. Sponsor ads however are not something the viewer wants to watch, so once you have a sponsor in a video, its quality immediately drops. Furthermore, as I have a better alternative to YouTube (the Safari platform), it makes no sense whatsoever to settle for a less professional platform. Besides, YouTube is only popular because it's been around the longest and with newer and better platforms entering the scene lately, it's doubtful this trend will continue. As a bonus for not working for YouTube, I don’t have to worry about the Article 13 issue that seems to trouble YouTubers, nor do I have to busk for subscriptions from my viewers. I still get some nasty comments from time to time, but the majority of the feedback I receive is positive. Finally, there is also the recent fiasco with the YouTube Rewind 2018 video (which broke the record for the number of dislikes in a single video, as well as the record of how quickly a video accumulates dislikes). This may seem insignificant to the YouTube fanatic, whose allegiance to YouTube and Alphabet trumps any rational thoughts on this matter, but the fact is that the company doesn't care about its content creators. Otherwise, it would mention the ones that actually make a contribution to it, instead of veering away from them, in favor of a celebrity and some not so relevant YouTubers. I don't know about you, but I'd rather not make videos at all than publish my videos to a platform like this, which fails to appreciate its contributors. So, if you are someone thinking of becoming a content creator and make a revenue from all this, there are better ways than YouTube. Perhaps it was a viable option once but right now it’s one of the worst places to publish your stuff. Besides, with Safari and other quality-based platforms out there, figuring out what to do with a quality video is really a no-brainer. 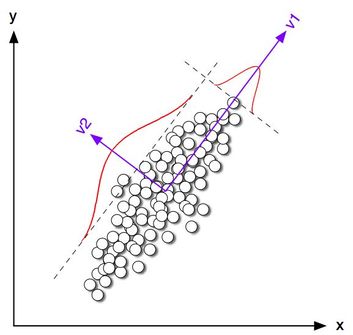 (Image by lazyprogrammer.me)
PCA has attracted a lot of questions among all of my mentees over the years, so I decided to make a fairly in-depth video on the topic. Unlike other education material on PCA, this one is light on the math, while there is a lot of emphasis on the concepts as well as how they apply to a data scientist's work. You can check out the video on Safari here. Note that in order to view the video in its entirety you'll need a subscription to the Safari platform. Cheers!  Lately it’s hard to find someone who is a legit data scientist and yet doesn’t talk about Stats as if it’s a new religion or something. Don’t get me wrong; I find Stats a very useful tool in data analytics, especially data science. However, there are other, usually most suitable options out there to have in one’s data science toolbox. First of all, Statistics is the state-of-the-art approach to data modeling, if you live in the mid 20th century. In our time, Stats, particularly frequentist Stats, is greatly outdated and many of the assumptions it makes about the data don’t make any sense. Also, transforming the data so that it fits the assumptions many Stats models make, is a time-consuming process which may or may not be worth the trouble. Of course if you know nothing else, or have trust issues with novel modeling options, then Stats may be the best option for you. In this case, however, it is best to brand yourself as a Stats professional instead of a data scientist, since the latter implies that you do more than just Stats. In addition, pretty much all of the metrics used in Stats can be improved heavily by negating the normality assumption. The more data I come across, the more certain I am that this assumption may make sense in some cases, but in the majority of cases it doesn’t hold. So, using metrics that have this assumption embedded in them doesn’t really help anyone. What’s more, all this framework inevitably shapes one’s mindset and so if you get used to the unreasonable assumptions Stats usually makes about the data, you may not be able to think of the data in a different way. Moreover, with the advent of A.I., especially the A.I. that’s directly applicable to data science, the data transformation and modeling options available to data scientists have increased dramatically. So, relying on Stats is more of a preference rather than a necessity. Besides, it’s extremely unlikely that a Stats model will be able to outperform an A.I. one when the latter is well configured. Finally, there are other new data analytics methods waiting to be discovered and used in data science. Heuristics have made a comeback and are more and more popular in data science research, especially when it comes to complex datasets. So, sticking to Stats when there is a plethora of possibilities out there that can tackle a problem more effectively is just depressing. Having said all that, Stats is a useful subject to learn, as it can aid one’s learning of the data science craft. Much like learning basic Mechanics can be useful if you want to being a Physics professional, learning Stats can be quite useful. Sticking to it and thinking of it as gospel, however, is not. That’s why after learning about it, it’s best to seek to expand your understanding of data analytics through delving into other frameworks, such as Machine Learning, A.I. based systems, and heuristics. Stats is just one of the tools available in the data scientist's toolbox...  These days I did something I’d been putting off for a while now, as if it didn’t work out, it would mean that I’d have to throw away my computer, so to speak. I didn’t exactly meddle with any of the computer’s hardware but came as close to it as I could, without physically changing the machine. Namely, I tweaked the boot software and configured a new OS that I’m now using. “What’s wrong with the old OS?” you ask. Well, I’d tweaked it way too much in the past, so it was now quite unstable. Yet, even at this pitiful state, it was better than some other OSes I’ve had over the years, so it’s hard to complain about it. Whatever the case, getting down to the nitty gritty of a computer isn’t easy and there is a surprising lack of people out there able or willing to help out. Also, the forums although generally useful, don’t always have the exact issue you are looking to solve, so you basically need to rely on your own skills. Fortunately, I did a thorough back-up of all my data beforehand, so nothing could get lost. Also, I was quite meticulous with the whole process and had a back-up plan in place. A lot of shell scripting was involved and although I'm not super confident about this type of interaction with a computer, it's not as daunting as it seems either. Of course, if you do it more, like professionals in the field, it may even seem the best way to interface with a computer. I'm not there yet though, but I have a deeper appreciation of the merits of this approach to interfacing than I did before. This whole thing is akin to the engineering approach to things, where failure is always taken into account since things break more often than people think. Thinking that everything is going to be fine, just because it worked fine in someone’s presentation or tutorial is naive and doesn’t really spell out professionalism. That’s why having the right mindset about all this stuff is essential. Algorithms, equations, and coding libraries can only get you so far. After that, you are on your own and you need more than just a solid understanding of the theory but also the ability to deal with the adverse circumstances that will probably present themselves sooner rather than later. Now, in you work as a data scientist or an A.I. professional you’ll probably have no need to do low level work on a computer (unless you are setting up a new pipeline), but if such a challenge presents itself, you are better off facing it. And who knows, maybe you’ll do more than just upgrade your computer through this whole process, since chances are that you’ll also be upgrading yourself. So, what did I learn from this whole experience? First of all, I now have a deeper appreciation to all those people who do the low-level work in a data science pipeline. It may appear straight-forward from a high-level perspective, but when you get down to it, it isn't simple at all, even if you enjoy working on a CLI. Also, I learned that just because something isn't common enough to be on a forum or a blog article, it doesn't mean it's not important or worth doing. The OS upgrade I did helped realize how vast the spectrum of possibilities is when it comes to OSes and how deviating from the most popular approaches to it is probably the best way to go (or at least the most fox-like way!). Finally, I learned that when you've assembled something yourself, even if it's a fairly straight-forward OS, it makes you appreciate it more. Most things nowadays come preassembled and we don't have to do anything to get them to work, but those things that require our own energy to come to life, be it an OS or a custom data science model, these are the things we tend to remember the most since they change us inside... |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed