 Blockchain has been making waves in the past 10 years or so, with many applications like BitCoin and other cryptocurrencies that have been developed on this platform. Yet, there is also alternative platforms like Hashgraph that promise to deliver the same services but in a more efficient manner. All these technologies are under the umbrella of Distributed Ledger Technologies and are particularly important in our era of pronounced cyber-security concerns.
Recently I’ve put together a video on this topic that’s now available on Safari. It’s more high level but it covers all the key aspects of the technologies, making it ideal for someone new to the topic. What’s more, I’ve written a short article comparing the two technologies, on the DSP blog. Feel free to check them both out. Enjoy!
0 Comments
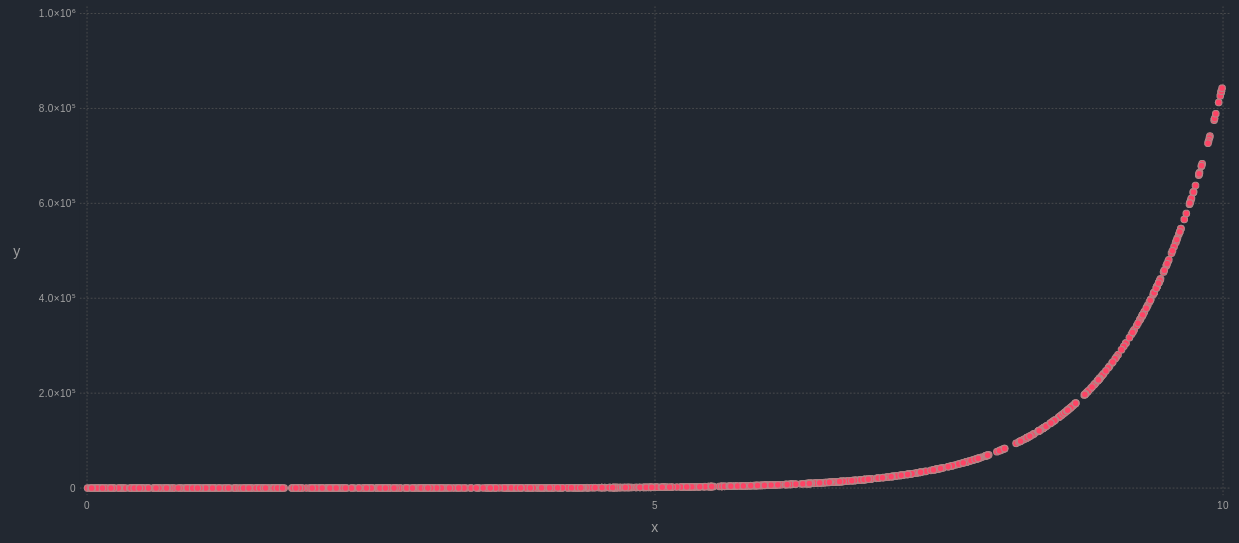 Before someone says “yes, of course; you just need to apply a non-linear transformation to one of the variables!”, let me rephrase: can we measure a non-linear relationship between two variables, without any transformations whatsoever? In other words, is there a heuristic metric that can facilitate the task of establishing whether two variables are linked in some fashion, without any data engineering from our part? The answer is “yes, of course” again. However, the relationship has to be monotonous for this to work. In other words, there needs to be a 1-1 relationship between the values of the two variables. Otherwise, it may not appear as strong, due to the nature of non-linearity. So, if we have two variables x and y, and y is something like x^10 + exp(x), that’s a relationship that is clearly non-linear, but also monotonous. Also, the Pearson correlation of the two variables in this case is not particularly strong (for the variables tested, it was about 0.67). If it were measured by a different correlation metric, however, like a custom-built one I’ve recently developed, the relationship would be somewhat stronger (for these variables, it would be around 0.75) while Kendall's ranked correlation coefficient would produce a great result too (1.00 for these variables). In a different scenario, where z = 1 / x, for example, the results of the correlation metrics differ more. Pearson’s correlation in this case would be something like -0.16, while the custom-made metric would yield something around -0.69. Also, Kendall’s coefficient would be -1.00. Although the effect is not always pronounced, in cases like this one, a different metric can make the difference between a strong correlation and a not-so-strong one, affecting our decisions about the variables. Bottom line, even if the Pearson correlation coefficient is the most popular method for measuring the relationship between two variables, it’s not the best choice when it comes to non-linear relationships. That’s why different metrics need to be used for evaluating the relationship between two variables, particularly if it’s a non-linear one. Revisiting Dimensionality Reduction (Conventional Methods with an Unconventional Approach)6/18/2018  Although I’ve talked about dimensionality reduction for data science in the corresponding video on Safari, covering various angles of the topic, I was never fully content with the methodologies out there. After all, all the good ones are fairly sophisticated, while all the easier ones are quite limited. Could there be a different (better) way of performing dimensionality reduction in a dataset? If so, what issue would such a method tackle? First of all, conventional dimensionality reduction methods tend to come from Statistics. That’s great if the dataset is fairly simple, but methods like PCA focus on the linear relationships among the features, which although it’s a good place to start, it doesn’t cover all the bases. For example, what if features F1 and F2 have a non-linear relationship? Will PCA be able to spot that? Probably not, unless there is a strong linear component to it. Also, if F1 and F2 follow some strange distribution, the PCA method won’t work very well either. What's more, what if you want to have meta-features that are independent to each other, yet still explain a lot of variance? Clearly PCA won’t always give you this sort of results, since for complex datasets the PCs will end up being tangled themselves. Also, ICA, a method designed for independent components, is not as easy to use since it’s hard to figure out exactly where to stop when it comes to selecting meta-features. In addition, what’s the deal with outliers in the features? Surely they affect the end result, by changing the whole landscape of the features, breaking the whole scale equilibrium at times. Well, that’s one of the weak point of PCA and similar dimensionality reduction methods, since they require some data engineering before they can do their magic. Finally, how much does each one of the original features contribute to the meta-features you end up with after using PCA? That’s a question that few people can answer although the answer is right there in front of them. Also, such a piece of information may be useful in evaluating the original features or providing some explanation of how much they are worth in terms of predictive potential, after the meta-features are used in a model. All of these issues and more can be tackled by using a new approach to dimensionality reduction, one that is based on a new paradigm (the same one that can tackled the clustering issues mentioned in the previous post). Also, even though the new approach doesn’t use a network architecture, it can still be considered a type of A.I. as there is some kind of optimization involved. As for the specifics of the new approach, that’s something to be discussed in another post, when the time is right...  A/B testing is a crucial methodology / application in the data science field. Although it mainly relies on Statistics, it has a remained quite relevant in this machine learning and AI oriented era of our field. It's no coincidence that in Thinkful that's one of the first things data science students learn, once they get comfortable with descriptive Stats and basic data manipulation. So, I decided to do a video on this topic to help those interested in learning about it get a good perspective of it and understand better its relationship with Hypothesis Testing. It is my hope that this video can be a good supplement to one's learning on the subject. Enjoy!
 I was never particularly fond of this unsupervised learning methodology that’s under the umbrella of machine learning. It’s not that I didn’t see value in it, but the methods that were available for it when I started delving into it were rudimentary at best and fairly crude. In fact, if I were to do a PhD now, I’d choose a clustering-related topic since there is so much room for improvement that even a simple idea for improving the most popular clustering methods out there is bound to improve them!
However, the fact that data science researchers and machine learning engineers in particular haven’t spent much time looking into clustering doesn’t make clustering a bad methodology. In fact, I’d argue that it’s one of the most insightful ones and it plays an important role in many data science projects, particularly in the data exploration stage. The key issues with clustering are: 1. The whole set of distance metrics used 2. The fact that the vast majority of clustering methods yield a (slightly) different result every time they are run 3. The need of an external parameter (K) in most clustering methods used in practice, in order to define how many clusters there are 4. The fact that it’s very shallow in its results There may be more issues with clustering, but these are the most important ones I’ve found. So, if we were to rethink clustering and do it better, we’d need to address each one of these issues. Namely: 1. A new set of distance metrics would be needed, metrics that are not influenced by the dimensional “noise” so much, in the case of many dimensions in the dataset. 2. The option for a deterministic clustering method, one that would optimize the centroid seed before starting the whole clustering process 3. An optimization process would be in place so as to find the best number of clusters. This should include the possibility of a single cluster, in the case where there isn’t enough diversity in the dataset. 4. A multi-level clustering option needs to be available, much like hierarchical clustering but in reverse, i.e. start with the main clusters in the dataset and gradually dig deeper into levels of sub-clusters. Now, all this may sound simple but it’s not as easy to put into practice. Apart from an in-depth understanding of data science, a quite refined programming ability is needed too, so that the implementation of this clustering approach can be efficient and scalable. Perhaps all this is not even possible with the conventional data analytics framework, but there is not a single doubt in my mind that it is possible in general, and if a high-performance language is used (e.g. Julia), it is even practically feasible. Naturally, a clustering framework like this one would require a certain level of A.I. to be used. This doesn’t have to be an ANN though, since A.I. can take many forms, not just network-based ones. Whatever the case, conventional statistics-based methods may be largely inadequate, while the very basic machine learning methods for clustering may not be sufficient either. This illustrates something that many data science practitioners have forgotten: that data science methods evolve, just like other aspects of the craft. New tools may be intriguing, but equally intriguing are the conventional methodological tools, especially if we were to rethink them from a more advanced perspective. This can be beneficial in many ways, such as opening new avenues of data analytics and even synthesizing new data. This, however, is a story for another time...  So, my publisher has been co-organizing this conference for a few years now, and this September it is going to be in Düsseldorf, Germany. What's so special about it? Well, I'll be participating in it too, as a speaker. But regardless of that, the DMZ conference has grown a lot since it first started and now covers a variety of topics, not just related to Data Modeling. Also, just like other good conferences, DMZ has a variety of good technical books made available, plus if you register for the conference using the code DMZEU2018_VOULGARIS you can get a 25 Euro discount on any book-related purchase you make (that's about $29 worth of reading material). So, check it out, when you get the chance, at https://datamodelingzone.com. The Biggest Mistake People Make When Learning Data Science and A.I. and What We Can Do about It6/4/2018  It’s not the programming language, as some people may think. After all, if you know what you are doing, even a suboptimal language could be used without too much of an efficiency compromise. No, the biggest mistake people make, in my experience, is that they rely too much on libraries they find as well as the methods out there. This is not the worst part though. If someone relies excessively on predefined processes and methods, the chances of that person’s role getting automated by an A.I. are quite high. So, what can you do? For starters, one needs to understand that both data science and artificial intelligence, like other modern fields, are in a state of flux. This means that what was considered gospel a few years back may be irrelevant in the near future, even if it is somewhat useful right now. Take Expert Systems, for example. These were all the rage during the time when A.I. came out as an independent field. However, nowadays, they are hardly used and in the near future, they may appear more anachronistic than ever before. That’s not to say that modern aspects of data science and A.I. are going to wane necessarily, but if one focuses too much on them, at the expense of the objective they are designed for, that person risks becoming obsolete as they become less relevant. Of course, certain things may remain relevant no matter what. Regardless of how data science and A.I. evolve, the k-fold cross-validation method will be useful still. Same goes with certain evaluation metrics. So, how do you discern what is bound to remain relevant from what isn’t? Well, you can’t unless you try to innovate. If certain methods appear too simple, for example, they may not stick around for much longer, even if they linger in the textbooks. Do these methods have variants already that outperform the original algorithms? Are people developing similar methods to overcome drawbacks that they exhibit? What would you do if you were to improve these methods? Questions like this may be hard to answer because you won’t find the necessary info on Wikipedia or on StackOverflow, but they are worth thinking about for sure, even if an exact answer may elude you. For example, I always thought that clustering had to be stochastic because everyone was telling me that it is an NP-hard problem that cannot be solved efficiently with a deterministic method. Well, with this mindset no innovations would ever take place in that method of unsupervised learning, would it? So, I questioned this matter and found out that not only are there ways to solve clustering in a deterministic way, but some of these methods are more stable than the stochastic ones. Are they easy? No. But they work. So, just like we tend to opt for mechanized transportation today, instead of the (much simpler) horse and carriage alternative, perhaps the more sophisticated clustering methods will prevail. But even if they don’t (after all, there are no limits to some people’s detest towards something new, especially if it’s difficult for them to understand), the fact that I’ve learned about them enables me to be more flexible if this change takes place. At the same time, I can be more prepared for other changes in the field, of a similar nature. I am not against stochastic methods, by the way, but if an efficient deterministic solution exists for a problem, I see no reason why we should stick with a stochastic approach to that problem. However, for optimization related scenarios, especially those involving very complex problems, the stochastic approach may be the only viable option. Bottom line, we need to be flexible about these matters. To sum up, learning about the conventional way of solving data-related problems, be it through data science methods, or via A.I. ones, is but the first step. Stopping there though would be a grave mistake, since you’d be depriving yourself the opportunity to delve deeper into the field and explore not only what’s feasible but also what’s possible. Isn’t that what science is about? |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed