 Non-Negative Matrix Factorization (NNMF or NMF) is a powerful method used in Recommender Systems, Topic Modeling in NLP, Image analysis, and various other areas. It involves breaking a matrix into a product of two other matrices, having either positive or zero values in them. The idea is to preserve meaning in the components derived since, in some cases, it doesn't make sense to have negative values in them (e.g., in Topic Modeling, you can't have a document with a negative membership to any given topic). NNMF is not an exact science, since it's an NP-hard problem. As a result, we try to find an approximate solution using various tricks. Although some people view NNMF as Stats-based, it is a machine learning technique based on Linear Algebra and Optimization. The math of NNMF is relatively straight-forward, though not something you would do with pen and paper, or even a calculator! There are various approaches to NNMF, involving finding two matrices W and H, such that the norm of the original matrix X minus W*F is minimal, all while W and H being non-negative: 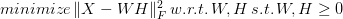 The norm part is the objective function of this minimization problem, by the way. Two common ways to accomplish this are the multiplicative update (gradually approximating W and H, using a particular rule), and the Hierarchical Alternating Least Squares (HALS) method, which attempts to find the columns of W one by one, through.
A common trick for NNMF is to use Singular Value Decomposition (SVD) first to find a rough approximation for W and H and then refine it gradually. Alternatively, we can use regularization to ensure that W and H's elements remain relatively small, resulting in a more stable solution. However, keep in mind that the solutions NNMF yields are approximate and correspond to local minima of the objective function. Fortunately, there are programming libraries that do all the heavy-lifting for us when it comes to NNMF. One such library is the NMF.jl one, in Julia. If you are more of a Python user, you can use the NMF function from the decomposition class of the sklearn package. Both of these libraries are well-documented so getting the hand of them is relatively straight-forward. You can learn more about data science methods like this one in my book, Data Science Mindset, Methodologies, and Misconceptions. In this book, I talk about all kinds of processes and techniques used in data science so that even the non-technical reader can grasp the intuition behind them and gain an understanding and appreciation of them. This book provides several external resources to go more in-depth on these topics and organize how you continue learning about this field, without getting lost in it. So, check it out when you have some time. Cheers!
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed