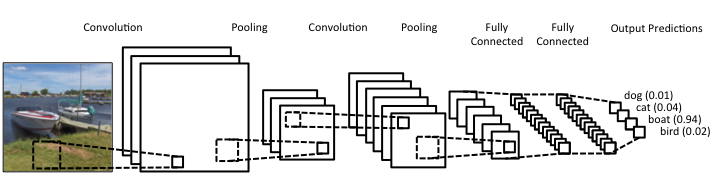
 Image originally posted on www.clarifai.com Lately (and I use this term loosely), there's been a lot of talk about deep learning. It's hard to find an article about data science that doesn't mention Deep Learning in one way or another. Yet, despite all its publicity, Deep Learning is still conflated with machine learning by most of the people consuming this sort of article. This misrepresentation can lead to misunderstandings that can be costly in a business setting, as there can be a disconnect between the data science team and the project stakeholders. Let's look into this topic more closely and clarify it a bit. Machine Learning is a relatively broad field that has become an instrumental part of data science. Complementary to Statistics, Machine Learning incorporates a data-driven approach to analyzing data. This approach involves the use of heuristics and predictive models. Most models used by data scientists today tend to fall into this category. Things like Random Forests and Boosted Trees are commonplace and powerful, while they are classic examples of machine learning. But these aren't the only ones, and lately, they have started to give way to other, more powerful models. The latter is in deep learning territory. Deep Learning is part of AI and deals with machine learning problems. It's still an innate part of the AI field, but because of its applicability in Machine Learning, it is often considered to be part of the latter too. After all, AI has spread in various domains these days, and as predictive analytics is one domain where it can add lots of value, its presence there is considerable. In a nutshell, Deep Learning involves large artificial neural networks (ANNs) that are trained and deployed for tackling data science-related problems. There are several such networks, but they all share one key characteristic: they go deep into the data, through the development of thousands of features, in an automated manner, for understanding the intricacies of the data. This sophistication enables them to yield higher accuracy and harness even the weakest signals in the data they are given. Deep Learning has been quite popular lately, not just because of its innovative approach to analytics but primarily because of the value it adds to data science projects. In particular, deep learning systems are versatile and can be used across different domains, given sufficient data and enough diversity in that data. They aren't handy just for images, while newer areas of application are being discovered constantly. Additionally, deep learning systems can do without a lot of data engineering (e.g., feature engineering) since this is something they undertake themselves. In other words, they offer a shortcut of sorts for the data scientists who use them, making their projects more efficient. Finally, deep learning systems can be customized considerably, making them specialized for different domains. That's particularly useful for developing better models geared towards the specific data available to you. Of course, the whole topic of deep learning is much deeper than all this. What's more, despite its usefulness, it's not always appropriate since conventional machine learning is also quite relevant in data science today. Moreover, there are other AI-based systems usable in data science, such as those based on Fuzzy Logic. In any case, there is no one-size-fits-all solution, which is why it's better to be well-versed on the various options out there. A great place to start learning about these options in a hands-on way is my latest book, Julia for Machine Learning, where we tackle various data science problems using various machine learning methods. Check it out when you have a moment!
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
 RSS Feed
RSS Feed