 Recently I read about some “research project” that Google’s A.I. branch conducted on the behavior of AIs as they tackle a certain simple scenario (a game of sorts). Various AIs were tested, including some more advanced ones, and the conclusion these researchers jumped to was that advanced AIs tend to be aggressive. Let’s assume for a moment that this was a scientifically valid research experiment and that the people involved followed science protocols closely. I know this is a big assumption but bear with me for a while. Can we accurately deduce the aggressiveness of an AI using this kind of setting? Or is there some inherent bias in the research question asked to start with? It’s important to note that the problem the AIs were tested on involved picking apples from an orchard and that the objective was to pick as many apples as possible. Naturally, there was a finite amount of apples to start with though in the beginning the orchard appeared abundant. Also, there were two AIs tested at a time and they were equipped with lasers, capable of stopping the other player for a while, so that more apples could be picked. So, after the AIs were deployed they went about their apple-picking endeavors. They took all the cash they could gather and politely lined up at an Apple store, all while contemplating what products to buy. Sorry, wrong experiment! In Google’s experiment the apples were actual fruits, not related to the tech giant who brought us the iPhone! Anyway, the AIs were given the option to collaborate or adopt an adversarial strategy (i.e. be trigger-happy when it comes to its laser pistol). Naturally they chose the latter, particularly when the number of apples was waning. The more advanced AIs adopted this course of action even sooner, probably because they could “see” further ahead. So, based on this experiment, one can conclude that an AI is bound to be more aggressive, in order to accomplish its objective, much like an animal would (e.g. a dog that feels that its territory is being threatened by some other dog that decided to pee there for some reason). In other words, intelligence can advance all it wants, but at the end of the day, its bearer is bound to act like an animal, since it only cares about winning its game (i.e. optimizing its objective function). This is sound reasonable, right? Well no. This is a particular case where an AI is given only two options and a very rigid objective, while its perception is limited to the two dimensional data of the game and a score. So, one could argue that the whole scenario is oversimplified and unrealistic. Plus what would the AI do with all these apples? Does it account for the fact that some of them may go bad or that if it decides to sell them in some form (e.g. an apple pie), there is the law of diminishing returns in the ROI of this whole endeavor? What about AI politics? What would other AIs think if it exhibits such aggressive behavior? Would anyone ever want to collaborate with it for another project? Naturally, the AIs involved in Google’s experiment don’t think about these things (like a human would probably do), since they have a one-track mind, caring only about the number of apples they collect. In such a scenario, no matter how advanced the AI is, it’s bound to seek actions that optimize the corresponding objective function, attacking anything that comes in its way, much like a short-sighted beast. Perhaps instead of taking the word of some “expert” as gospel, it would be more fruitful for someone to ponder on this matter himself. Also, if so inclined, one can build her own AI experiments and explore other alternatives in the AIs’ pursuit of apples (or some other measurable objective). After all, things are not so simple when it comes to AI, so it makes sense to examine this matter with sufficient depth of thought, unless of course we just opt for some sensational result to drive home a point, which may or may not bear any scientific validity.
0 Comments
 Last week I’ve finished my part of the final corrections stage of the new technical book I’d been working on for the past few months. My co-author, Yunus, has done the same, so the book should be in the press later this month! Hopefully, you should be able to purchase it soon, either from the publisher’s site, or from some other vendor (e.g. Amazon). Just wanted to share that with you all. Once the book is out there, I’ll be sure to make an announcement about it here on this blog. Cheers!  A famous scientist from the Quantum Physics school of thought once said “asking the right question is more than halfway towards finding the answer.” Although it’s been years since I read this quote (which I may be paraphrasing, by the way), it still echoes a deep truth and helps guide my (non-academic) research in the data science and A.I. fields. So, I few weeks ago I put forward the question “what would a statistical framework framed around possibilities be like?” At first glance, such a question may seem nonsensical since from an early age we’ve all be taught the core aspects of Stats and how it’s all about probabilities. There is no doubt that the probabilistic approach to modeling uncertainty has yielded a lot of fruits as the field grew, but all developments of Statistical methods were bound by the limitations of the assumptions made, mirrored by the various distributions used. In other words, if you want results with conventional Stats, you’ve got to use this or the other distribution and keep in mind that if the data you have doesn’t follow the distribution assumed, the results may not be reliable. What if the field of Stats was void of such restrictions by assuming a membership function instead of a distribution, to describe the data at hand? I’m not going to describe in length where this rabbit hole leads, but suffice to say that the preliminary results of a framework based on this alternative approach exceeded my expectations. Also, there is no Stats process that I looked at which could not be replicated with the possibilistic approach. What’s more, since the possibilistic approach to data analytics is one of the oldest forms of A.I., it is sensible to say that such a statistical framework would be in essence AI-based, though not related to deep learning, since that’s a completely different approach to A.I. that has its own set of benefits. Nevertheless, I found that having a statistical framework that borrows an A.I. concept in its core, can provide an interesting way to bridge the gap between Stats-based data analytics and modern / A.I. based. What’s even more interesting is that this can be a two-way street, with A.I. also being able to benefit from such a nexus between the two fields. After all, one of the biggest pain points of modern A.I. is the lack of transparency, something that’s a freebie when it comes to Stats modeling. So, an A.I. system that has elements of Stats at its core may indeed be a transparent one. However, this idea is still highly experimental, so it would be best to not discuss it further here. Whatever the case, I have no doubt that the possibilistic approach to data has a lot of merit and hasn’t been explored enough. So, it is possible that it has a role to play in more modern data analytics systems. The question is, are you willing to accept this possibility?  When a machine learning predictive analytics systems makes predictions about something chances are that we have some idea of what drove it to make these predictions. Oftentimes, we even know how confident the system is about each prediction, something that helps us become confident about it too. However, most A.I. systems (including all modern AIs used in data science) fail in giving us any insight as to how they arrived at their results. This is known as the black box problem and it’s one of the most challenging issues of network-based AIs.
Although things are hopeless for this kind of systems due to their inherent complexity and lack of any order behind their predictive magic, it doesn’t mean that all AIs need to be under the same umbrella. Besides, the A.I. space is mostly unexplored even if often seems to be a fully mapped terrain. Without discounting the immense progress that has been made in network-based systems and their potential, let’s explore the possibility of a different kind of A.I. that is more transparent. Unfortunately, I cannot be very transparent about this matter as the tech is close-source, while the whole framework it is based on is so far beyond conventional data analytics that most people would have a hard time making sense of it all. So, I’ll keep it high-level enough so that everyone can get the gist of it. The Rationale heuristic is basically a way analyzing a certain similarity metric to its core components, figuring out how much each one of them contributes to the end result. The similarity metric is non-linear and custom-made, with various versions of it to accommodate different data geometries. As for the components, if they are the original features, then we can have a way to directly link the outputs (decisions) with the inputs, for each data point predicted. By examining each input-output relationship and applying some linear transformation to the measures we obtain, we end up with a vector for each data point, whose components add up to 1. Naturally, the similarity metric needs to be versatile enough to be usable in different scenarios, while also able to handle high dimensionality. In other words, we need a new method that allows us to process high-dimensional data, without having to dumb it down through a series of meta-features (something all network-based AIs do in one way or another). Of course, no-one is stopping you from using this method with meta-features, but then interpretability goes out the window since these features may not have any inherent meaning attached to them. Unless of course you have generated the meta-features yourself and know how everything is connected. “But wait,” you may say, “how can an A.I. make predictions with just a single layer of abstraction, so as to enable interpretability through the Rationale heuristic?” Well, if we start thinking laterally about it we can also try to make A.I. systems that emulate this kind of thinking, exhibiting a kind of intuition, if you will. So, if we do all that, then we wouldn’t need to ask this question at all and start asking more meaningful questions such as: what constitutes the most useful data for the A.I. and how can I distill the original dataset to provide that? Because the answer to this question would render any other layer-related questions meaningless. As someone once said, "Knowledge is having the right answer; Intelligence is asking the right question." So, if we are to make truly intelligence systems, we might want to try acting as intelligent beings ourselves...  Over the past couple of weeks I've been thinking about this topic and gathering material about it. After all, unlike other more attractive aspects of A.I., this one still eludes the limelight, even though it's become quite popular as a research topic lately. Since I believe this is a matter that concerns everyone, not just those of us who are in the A.I. field, I created this video on the topic. It's a bit longer than the other ones on A.I. topics, but I made an effort to make it relate-able and avoid too many technical terms. So, if you have a Safari account, I invite you to check it out here.  Contrary to the probabilistic approach to data analytics, which relies on probabilities and ways to model them, usually through a statistical framework, the possibilistic approach focuses on what’s actually there, not what could be there, in an effort to model uncertainty. Although not officially a paradigm (yet), it has what it takes to form a certain mindset, highly congruent with that of a competent data scientist. If you haven’t heard of the possibilistic approach to things, that’s normal. Most people have already jumped on the bandwagon of the probabilistic dogma, so someone seriously thinking of things possibilistically would be considered eccentric at best. After all, the last successful possibilistic systems are often considered obsolete, due to their inherent limitations when it came to higher dimensionality datasets. I’m referring to the Fuzzy Logic systems, which are part of the the GOFAI family of A.I. systems (in these systems the possibilities are expressed as membership levels, through corresponding functions). These systems are still useful, of course, but not the go-to choice when it comes to building an AI solution to most modern data science problems. Possibilistic reasoning is that which relies on concrete facts and observable relationships in the data at hand. It doesn’t assume anything, nor does it opt for shortcuts by summarizing a variable with a handful of parameters corresponding to a distribution. So, if something is predicted with a possibilistic model, you know all the how’s and why’s of that prediction. This is directly opposite to the black-box predictions of most modern AI systems. Working with possibilities isn’t easy though. Oftentimes it requires a lot of computational resources, while an abundance of creativity is also needed, when the data is complex. For example, you may need to do some clever dimensionality reduction before you can start looking at the data, while unbiased sampling may be a prerequisite also, particularly in transduction-related systems. So, if you are looking for a quick-and-easy way of doing things, you may want to stick with MXNet, TensorFlow, or whatever A.I. framework takes your fancy. If on the other hand you are up for a challenge, then you need to start thinking in terms of possibilities, forgetting about probabilities for the time being. Some questions that may help in that are the following: * How much does each data point contribute to a metric (e.g. one of central tendency or one of spread)? * Which factors / features influence the similarity between two data points and by how much? * What do the fundamental components of a dataset look like, if they are defined by both linear and non-linear relationships among the original features? * How can we generate new data without any knowledge of the shape or form of the original dataset? * How can we engineer the best possible centroids in a K-means-like clustering framework? * What is an outlier or inlier essentially and how does it relate to the rest of the dataset? For all of these cases, assume that there is no knowledge of the statistical distributions of the corresponding variables. In fact, you are better off disregarding any knowledge of Stats whatsoever, as it’s easy to be tempted to use a probability-based approach. Finally, although this new way of thinking about data is fairly superior to the probabilistic one, the latter has its uses too. So, I’m not advocating that you shouldn’t learn Stats. In fact, I’d argue that only after you’ve learned Stats quite well, will you be able to appreciate the possibilistic approach to data in full. So, if you are looking into A.I., Machine Learning, or both, you may want to consider a possibilistic way of tackling uncertainty, instead of blindly following those who have vested interests in the currently dominant paradigm. The Biggest Mistake People Make When Learning Data Science and A.I. and What We Can Do about It6/4/2018  It’s not the programming language, as some people may think. After all, if you know what you are doing, even a suboptimal language could be used without too much of an efficiency compromise. No, the biggest mistake people make, in my experience, is that they rely too much on libraries they find as well as the methods out there. This is not the worst part though. If someone relies excessively on predefined processes and methods, the chances of that person’s role getting automated by an A.I. are quite high. So, what can you do? For starters, one needs to understand that both data science and artificial intelligence, like other modern fields, are in a state of flux. This means that what was considered gospel a few years back may be irrelevant in the near future, even if it is somewhat useful right now. Take Expert Systems, for example. These were all the rage during the time when A.I. came out as an independent field. However, nowadays, they are hardly used and in the near future, they may appear more anachronistic than ever before. That’s not to say that modern aspects of data science and A.I. are going to wane necessarily, but if one focuses too much on them, at the expense of the objective they are designed for, that person risks becoming obsolete as they become less relevant. Of course, certain things may remain relevant no matter what. Regardless of how data science and A.I. evolve, the k-fold cross-validation method will be useful still. Same goes with certain evaluation metrics. So, how do you discern what is bound to remain relevant from what isn’t? Well, you can’t unless you try to innovate. If certain methods appear too simple, for example, they may not stick around for much longer, even if they linger in the textbooks. Do these methods have variants already that outperform the original algorithms? Are people developing similar methods to overcome drawbacks that they exhibit? What would you do if you were to improve these methods? Questions like this may be hard to answer because you won’t find the necessary info on Wikipedia or on StackOverflow, but they are worth thinking about for sure, even if an exact answer may elude you. For example, I always thought that clustering had to be stochastic because everyone was telling me that it is an NP-hard problem that cannot be solved efficiently with a deterministic method. Well, with this mindset no innovations would ever take place in that method of unsupervised learning, would it? So, I questioned this matter and found out that not only are there ways to solve clustering in a deterministic way, but some of these methods are more stable than the stochastic ones. Are they easy? No. But they work. So, just like we tend to opt for mechanized transportation today, instead of the (much simpler) horse and carriage alternative, perhaps the more sophisticated clustering methods will prevail. But even if they don’t (after all, there are no limits to some people’s detest towards something new, especially if it’s difficult for them to understand), the fact that I’ve learned about them enables me to be more flexible if this change takes place. At the same time, I can be more prepared for other changes in the field, of a similar nature. I am not against stochastic methods, by the way, but if an efficient deterministic solution exists for a problem, I see no reason why we should stick with a stochastic approach to that problem. However, for optimization related scenarios, especially those involving very complex problems, the stochastic approach may be the only viable option. Bottom line, we need to be flexible about these matters. To sum up, learning about the conventional way of solving data-related problems, be it through data science methods, or via A.I. ones, is but the first step. Stopping there though would be a grave mistake, since you’d be depriving yourself the opportunity to delve deeper into the field and explore not only what’s feasible but also what’s possible. Isn’t that what science is about?  There is no doubt that Artificial Intelligence has a number of issues that need to be addressed before its benefits can become more wide-spread. Also, if it were to become more autonomous, we would need to be able to at least anticipate its decisions and perhaps even understand how they come about. However, none of these things have proven to be happening yet. Whether that’s due to some innate infeasibility or due to some other factor is yet to be discovered. What we have discovered though, again and again, is that most A.I. developments take the world by surprise. Even the people involved in this field, dedicated scientists and engineers who have spent countless hours working with such systems. However, our collective understanding of them still eludes us and it’s not the A.I.’s fault. It’s easy to blame an A.I. or the people behind it for anything that goes wrong, but remember that various A.I. projects were seen to their completion because we as potential users of them wanted them out there. Whether we understood the implications of these systems or not though is questionable. So, the biggest issue of A.I. might be how we relate to it, combined with the fact that we don’t really understand it in depth. The evangelists of the field view it as a panacea of sorts, oftentimes confusing A.I. with ML, while often considering the latter as a subfield of the former. On the other hand, the technical people involved in A.I. see it as a cool technology that can keep them relevant in the tech market. As for the consumers of A.I., they see it as a cool futuristic tech that may make life more interesting, though it may also change the dynamics of the job market in very disruptive (or even disturbing) ways. Unless, we all obtain a more clear understanding of what A.I. is, what it can and cannot do, and how it works (to the extent each person’s technical level allows), A.I. will remain an exotic technology wrapped in a mist of mystique. That’s not an unsurmountable problem though. Nowadays, knowledge is more accessible than ever before, so if someone wants to learn about A.I. more, it’s just a matter of committing to that task and putting the hours necessary. Granted that sometimes a few books or videos would be needed too, with whatever cost this entails, still the task is a quite manageable one. Besides, one doesn’t need to be an A.I. expert in order to have sensible expectations of this tech and be able to discern the brilliance of some such systems from the BS of many of the futurists. All in all, the more one knows about this field and the more realistic his or her expectations are, the better the chances of deriving value from A.I., without falling victim of the problems that surround it.  So, the NLP Fundamentals video I made recently is online as of today (you can find it on the Safari site). Note that since Natural Language Processing is a very broad subject, it is quite hard to do it justice in a single video. However, for someone needing a good introduction to it, this video should be fine. Enjoy! 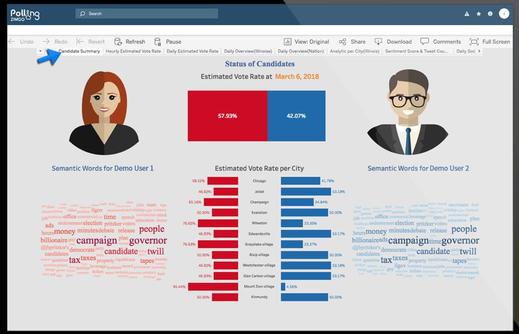 A few months ago, I wrote a blog post on Artificial Emotional Intelligence, a kind of A.I. that emulates the EQ aspects of our mental process. Of course this technology is still limited to emulating basic aspects of the human emotional spectrum, focusing mainly on comprehending emotion through text data. Nevertheless, this can still add a lot of value to an organization, as in the case of ZimGo Polling, an initiative to predict the outcome of an election, prior to the counting of the votes. BPU Holdings, the company behind this ambitious yet quite down-to-earth initiative, make use of an advanced NLP system, employing some specialized AI systems (interestingly I’m currently in the process of creating a video on the topic of NLP, for Safari!). Also, the data for this endeavor stems from social media, something that ensures abundance as well as freshness, both key factors in making good predictions on this sort of trends. Since part of my job at DSP Ltd. is being up-to-date on the latest and greatest trends in data science and A.I., when a representative of BPU Holdings approached me with their AEI ideas, I took the opportunity to learn more about this field and about what they were doing. That’s how that previous blog post I mentioned came about. Last month, I had the opportunity to talk to the people of this company directly, learning more about their work and AEI’s promise of bringing more value to organizations around the world, through this intriguing niche. After looking into this matter a bit, I became convinced that this company may be actually on to something. The case study presented to me involved the S. Korean elections, where this AEI system managed to predict the results with impressive accuracy. Of course, the company doesn’t plan to rest at its laurels, as there are already plans to apply this new approach to data analytics to other areas, such as the US elections. You can read more about this as well as the company’s offerings in the attached press release as well as its website. Note that I am not affiliated with this company, so if I appear a bit biased towards it that’s because I favor the use of A.I. for such initiatives, rather than other, more aggressive applications, such as those in the military. After all, if there is one thing that I hope has come across from all my postings on this topic, it is that A.I. can be a positive tech, bringing about value to everyone, not just some multinational conglomerates that may not always use it wisely. Also, instead of following blindly this or the other A.I. expert on the social media, I prefer to take a more active approach to this matter by directly connecting with the people involved and providing them with feedback on this tech, as they are developing it. That’s why this blog is the first one worldwide to publicly announce this company’s initiative and bring AEI to the conversation table. What are your thoughts / emotions on it? Feel free to share them with me, either through this blog or via a direct message.
|
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
December 2022
Categories
All
|
||
 RSS Feed
RSS Feed