Introducing the Trinary Curve: A Novel Heuristic for Artificial Intelligence Data Science Systems11/5/2018 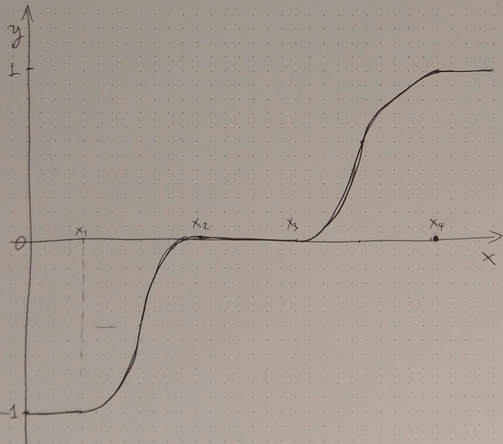 Trinary Logic is not something new. It’s been around for decades, though it was more of a mathematical / high-level framework. I should know, as I did my Masters thesis on this subject and how it applies to GIS. I even wrote code implementing the corresponding model I came up with, though in today’s programming world it seems like legacy code... Anyway, bottom line is that Trinary Logic is useful and could have a place in modern Information Systems, including data analytics projects. The question is, could it be applicable to A.I. too? The answer is, as usual, “it depends.” Trinary Logic on its own is quite limited and unless you are familiar with its 700+ gates, it may be like any novel idea: interesting but not exactly something worth delving into. After all, just like any system of reasoning, Trinary Logic is meaningless without an in-depth understanding of its key contribution to the thorny issue we always tackle through reasoning: handling uncertainty effectively. Uncertainty, oftentimes modeled as noise or randomness (depending on who you ask), is everywhere. Since we cannot eliminate it without damaging the signal too, we find ways to cope with it. Trinary Logic offers an interesting way of doing that through the 3rd value of its variables, namely the “indifferent” state. Something can be True, False, or Indifferent, the latter being something in-between. These are the states of those intermediate values in the membership functions of fuzzy variables, in Fuzzy Logic. The latter is a well-known and quite established A.I. framework with lots of applications in data science. Do you see where I’m going with this? So Trinary Logic is a framework for reasoning, much like Fuzzy Logic, but the latter is an A.I. framework too, so Trinary Logic is A.I. also, right? Well, no. Trinary Logic is a mathematical construct, so unless it is applied to A.I. programmatically, and as a well-defined process, it is yet another concept that can’t even fetch an academic publication! But if it were to manifest as a heuristic of sorts and add value to a process in the A.I. sphere, things would be different. Enter the Trinary Curve, a heuristic (or meta-heuristic, depending on how you use it) that encapsulates Trinary Logic in a simple yet not simplistic way, turning an input signal into something that an A.I. agent can understand and work with. Namely, it can engineer a new variable in the [-1, 1] interval (notice the closed brackets in this case), that enables the corresponding module to have the in-between state of uncertainty more evident. As a result, the A.I. agent is allowed to be unsure about something and examine it more closely, given the right architecture, instead of working with what it has and hope for the best. Note that the Trinary Curve can be customized, while its output can be normalized to a different interval (always closed) if needed. The Trinary Curve is differentiatable throughout the space it is defined, while it’s easy to use programmatically (at least in Julia). Perhaps the Trinary Curve is a novelty and an A.I. system can evolve adequately without it. However, it is something worth considering, instead of just experimenting with the countable parameters of existing A.I. systems solely. After all, Trinary Logic is compatible with existing A.I. frameworks so if it’s not utilized, it’s primarily because of some people’s unwillingness to think outside the box, and that’s something that doesn’t have any uncertainty about it...
0 Comments
 This week I'm away, as I prepare for my talk at the Consumer Identity World EU 2018 conference in Amsterdam (the same conference takes place in a couple of other places, but I'll be attending just the one in Europe). So, if you are in the Dutch capital, feel free to check it out. More information on my talk here. Cheers!  Dichotomy: a binary separation of a set into two mutually exclusive subsets Data Science: the interdisciplinary field for analyzing data, building models, and bringing about insights and/or data products, which add value to an organization. Data science makes use of various frameworks and methodologies, including (but not limited) to Stats, ML, and A.I. After getting these pesky definitions out of the way, in an effort to mitigate the chances of misunderstandings, let’s get to the gist of this fairly controversial topic. For starters, all this information here is for educational purposes and shouldn’t be taken as gospel since in data science there is plenty of room for experimentation and someone adept in it doesn’t need to abide to this taxonomy or any rules deriving from it. The inaccurate dichotomy issues in data science, however, can be quite problematic for newcomers to the field as well as for managers involved in data related processes. After all, in order to learn about this field a considerable amount of time is required, something that is not within the temporal budget of most people involved in data science, particularly those who are starting off now. So, let’s get some misconceptions out of the way so that your understanding of the field is not contaminated by the garbage that roams the web, especially the social media, when it comes to data science. Namely, there are (mis-)infographics out there that state that Stats and ML are mutually exclusive, or that there is no overlap between non-AI methods and ML. In other words, ML is part of AI, something that is considered blasphemy in the ML community. The reason is simple: ML as a field was developed independently of AI and has its own applications. AI can greatly facilitate ML through its various network-based models (among other systems), but ML stands on its own. After all, many ML models are not AI related, even if AI can be used to improve them in various ways. So, there is an overlap between ML and AI, but there are non-AI models that are under the ML umbrella. Same goes with Statistics. This proud sub-field of Mathematics has been the main framework for data analytics for a long time before ML started to appear, revolting against the model-based approach dictated by Stats. However, things aren’t that clear-cut. Even if the majority of Stats models are model-based, there are also models that are hybrid, having elements of Stats and ML. Take Bayesian Networks for example, or some variants of the Naive Bayes model. Although these models are inherently Statistical, they have enough elements of ML that they can be considered ML models too. In other words, they lie on the nexus of the two sets of methods. What about Stats and AI? Well, Variational AutoEncoders (VAEs) are an AI-based model for dimensionality reduction and data generation. So, there is no doubt that it lies within the AI set. However, if you look under the hood you’ll see that it makes use of Stats for the figuring out what the data generated by it would be like. Specifically, it makes use of distributions, a fundamentally statistical concept, for the understanding and the generation of the data involved. So, it wouldn’t be far-fetched to put VAEs in the Stats set too. From all this I hope it becomes clear that the taxonomy of data science models isn’t that rigid as it may seem. If there was a time when this rigid separation of models made sense, this time is now gone as hybrid systems are becoming more and more popular, while at the same time the ML field expands in various directions outside AI. So, I’d recommend you take those (mis-)infographics with a pinch of salt. After all, most likely they were created by some overworked employee (perhaps an intern) with a limited understanding of data science.  I've been writing a lot about A.I. lately and AGI has been a recurring topic lately. Although the possibility of this technology becoming a reality is still a bit futuristic, we can still ponder on the possibility and explore how such an A.I. system would affect us. Hence this fiction book I wrote in the past few months and published this week on Amazon (Kindle version only). Feel free to check it out when you have a minute. The book is dedicated to researchers of A.I. Safety.  Lately I worked on a new series of videos, this time on Optimization. This A.I. methodology is a very popular one these days, one that adds a lot of value to both data science and other processes where resources are handled. Specifically, I talk about: * Optimization in general (including its key applications) * Particle Swarm Optimization * Genetic Algorithms * Simulated Annealing * Optimization ensembles * some auxiliary material that supplements these topics You can find this video series on Safari, along with my other A.I. videos. Cheers!  Introduction When designing an A.I. system these days it seems that people focus on one thing mainly: efficiency. However, even though there is no doubt about the value of such a trait, there are other factors to consider when building such a system, so that it is not only practical but also safe and useful in other projects. Namely, in order for AGI to one day become feasible, we need to start building A.I. systems that fulfill a certain set of requirements. Transparency This is the Achilles heal of most modern A.I. Systems and a key A.I. Safety concern. However, it’s not an insolvable problem as many A.I. researchers (particularly those bold enough to think outside the black box of Deep Learning systems) have tackled this matter and some have proposed some solutions for shedding some light on the outputs of that DL network that crunches the data behind those cat pictures it is asked to process. Unfortunately, this transparency element they add is geared more towards image data since it’s easier to comprehend and interpret, when it takes the form of complex meta-features in the various layers of a DL network. Still, it is possible to have transparency in alternative A.I. systems that use a simpler architecture, perhaps non-network based. Autonomy It goes without saying that a system needs to be autonomous, even in its training, if it is to be considered intelligent. Although humans will need to play an important role in its training by providing this A.I. with data that makes sense, as well as some general directions (e.g. the terminal goal and some instrumental goals perhaps), the A.I. system needs to be able to figure out its own parameters automatically, using the data at hand. Otherwise, its effectiveness will be limited to the know-how of the “expert” involved in it, who may or may not have an in-depth understanding of the field or how data science works. Scalability For an A.I. system to be effective, it has to be scalable, i.e. able to be deployed on a large computer network, be it in a cluster or the cloud. Otherwise, that system is bound to be of very limited scope and therefore its usefulness will be quite limited. For an A.I. system to scale well, however, its various processes need to be parallelizable, something that requires a certain design. DL networks are like that but not all A.I. systems are as easy to parallelize and scale. Transduction This is an important aspect of our own thinking and one that hasn’t been implemented enough in A.I. systems, partly because of methodological limitations and partly because it’s not as easy for most A.I. people to wrap their heads around. In essence, it is the most down-to-earth form of intuition and what allows lateral thinking. An A.I. system having this attribute would be able to think like a human would and therefore be more easily understood and more relateable. It’s possible that this will mitigate the risks of the rigid rule-based thinking that many A.I. systems now have, even if it is concealed in complex architectures. Efficiency Of course we shouldn’t neglect efficiency in this whole design. An A.I. system has to be efficient in both its application and its training. If it takes a whole data center in order to train, that’s not efficient, not even if it is feasible for some people having access to such computational resources. An efficient A.I. system should be able to perform even in a small computer cluster, even if its effectiveness will be more limited in relation to the same system having access to a larger amount of resources. Putting It All Together Although A.I. systems today are fascinating and to some extent inspiring in their potential, they could be better. Namely, if we were to design them with the aforementioned principles in mind, they’d be more tasteful, if you catch my drift. Perhaps, such systems will not only be useful and practical but also safer and easier to relate with, making their integration in our society more natural and mutually beneficial.  Although lately I've been writing about the infeasibility of AGI in our current time and how an AGI can pose great threats, it is still useful to consider what would happen if an AGI actually existed and how it would see and interact with our world. Hence this novel, which through the first-person perspective of an AGI system, explores how the advent of such a technology could have noticeable consequences to our world, transcending even its creator's expectations. After all, the difference between an AGI with our level of intelligence and a super-intelligent AGI is not as large, though for the purpose of the plot of this novel, it has been shown to take place over a period of several months. In any case, if you are into science fiction and wish to contemplate on the matter of AGI and A.I. Safety, this novel may be for you. Feel free to check it out on Amazon (currently only in Kindle format). Thanks!  Lately I came across a post on Twitter about AGI and how there are some serious safety concerns about it. Although this is by no means a new idea, it is more and more relevant as A.I. evolves to previously unimaginable levels. For example, recently a new kind of deep learning networks came about that could explain themselves when it comes to the image classification task which they specialize in. It’s important to remember that even advanced systems like that are still narrow (weak) A.I. but it’s not a big leap to consider how a general (strong) A.I., aka AGI, would exhibit a similar trait. If that is the case then, couldn’t this AGI system help solve all of our problems, since it could effectively guide us through its more advanced thinking process? Well, no. An AGI would be a more general purpose version of the current A.I. tech, and even though it would be significantly superior in many ways (e.g. the interpretability aspect and its interaction capabilities with its users), it would still carry the same biases as its more specialized modules. After all, chances are that such a system would have smaller components that are likely to resemble the existing A.I. systems, though how they’d interact with each other and with the meta-cognitive module would be another story! Whatever the case, general-purpose doesn’t mean wiser, even if it would appear wiser than the current AIs since it would be able to approximate our intelligence better (even though its intelligence is bound to exhibit non-human characteristics also). In addition, an AGI is bound to be significantly more complex in its data flows and data analytics processes. We may be able to understand its structure but it’s quite unlikely we’ll ever be fully aware of its dynamics, much like neuroscientists are not sure about how exactly the human brain works, even if its “hardware” has been mapped out in detail and the functionality of its rudimentary element (the neuron) has been thoroughly understood. Now, imagine how something even more complex than the human brain would function. To expect anyone to be able to understand it would be naive and possibly dangerous. And if we cannot understand it, how can we expect in-depth communication with it to take place? It would be like a goldfish trying to communicate with a swordfish or something (we being the goldfish in this example)! That’s why it’s best to take whatever the futurists say with a pinch of salt (or even disregard it altogether in some cases). They may mean well but their “predictions” are educated guesses at best. After all, the cryptography experts of the golden age of cryptography (WW2) couldn’t have predicted the immense complexity and functionality of current cyphers and code-breakers, and these people were super smart (definitely more intelligent than today’s futurists)! I have no doubt that if things continue to progress the way they do, in the realm of technology, AGI will become a reality in the future, probably within our generation. However, I seriously doubt that it would be the superhero many people expect it to be. It will probably not destroy the world either, since it’s bound to be applied to certain areas mainly, even if theoretically anyone would be able to have access to it (based on the subscription package they are willing to buy). So, let’s be realistic about this new tech; just because it’s promising and fascinating, it doesn’t mean that it will be a panacea.  Recently an associate of mine and I have started a blog on Medium, focusing on A.I. related topics. There are no articles on it at the moment, but we are actively looking for potential authors of such articles. Every author can have a short bio of him/her and a link to their site of choice (e.g. their company’s site, their own blog, or even an online professional profile of his/hers). Right now, we don’t have very restrictive requirements regarding the articles, so anything that is related to A.I. (especially its applications and its real-world impact on fields like data science or robotics) qualifies. Also, there is no word restriction so if you want to write a whole mini-book on this blog, you can be our guest! If you are interested, feel free to let us know either through the comments below, or via a direct email to me (you can use the contact form at the corresponding page of the Foxy Data Science site). Cheers!  So, about 18 months ago I created a video on Safari about how A.I. could benefit Data Science (DS and AI). Even though at that time I was still figuring things out regarding how educational videos work, the vid was immensely popular and even today still attracts lots of views. Considering that all of my recent videos are (much) better than that one, at least technically, this is quite intriguing. Anyway, fast forward to September last year. As I was walking in the streets of suburban Seattle, thinking about what to do next (my Data Science Mindset, Methodologies, and Misconceptions book had just been released), I decided to write another book, one about A.I. since this topic continued to fascinate me, while it was becoming a popular topic among various data scientists. So, I pitched the idea of a new book to Steve Hoberman and after sorting out the details, we got a contract going. However, due to various reasons we decided to start the book in January. The whole project was quite a turbulent one, with my co-author dropping out around March, leaving me in a very difficult situation. Yet, I decided that the book was worth completing. Fortunately, another data scientist / A.I. expert decided to join me in this endeavor, Yunus E. Bulut, who I got acquainted with through Thinkful. Long story short, after a few discussions about the project he had a contract of his own as a co-author. Three months later, the first draft was complete. Of course the book went through a lot of revisions since then, partly because the technology was changing and partly because there were a lot of topics in this book, which was difficult to coordinate and merge into a coherent whole. Also, at one point Julia reached adulthood as a programming language (v. 1.0) so we had to update the code for the chapters that had programs in Julia. So, after a feverish summer, plagued by heat waves and other obstacles, we finished the edits (at least the most important ones, since a book is never really finished!) and the book went to the press. Now, it is finally available for you to buy at whatever vendor you prefer. Check out the publisher's site for more details. Cheers! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
December 2022
Categories
All
|
 RSS Feed
RSS Feed