 In a previous article we talked about the value of data modeling and how it is related to data science as a field. Now let’s look at some great ways to learn more about this field. Specifically, Technics Publications offers a few classes/workshops on data modeling this Autumn:
What’s more, you can get a 20% discount on them, if you use the coupon code DSML. You can use the same code for most of the books available on that site. Check it out!
1 Comment
 Being an author has many benefits, some of which I’ve mentioned in a previous article. After all, an author (particularly a technical author) is more than just a writer. The former has undergone the scrutiny of the editing process, usually undertaken by professionals, while a writer may or may not have done the same. Also, an author has seen a writing project to its completion and has gotten a publisher to put his or her stamp of approval on that manuscript, before making it available to a larger audience. This raises the stakes significantly and adds a great deal of gravity to the book at hand. Being an author is its own reward (even though there are other tangible rewards to it too, such as the royalties checks every few months!). However, there is a benefit that is much less obvious although it is particularly useful. Namely, an author can appreciate other authors more and learn from them. This is something that I have come to learn since my first book, yet this appreciation has reached new heights since then. This is especially the case when it comes to veteran authors who have developed more than one book. All this leads to an urge to read more books and get more out of them. This is due to the value an author puts into these books. Instead of just a collection of words and ideas, he views a book as a sophisticated structure comprising of many layers. Even simple things like graphics take a new meaning. Of course, much of this detailed view of a book is a bit technical but the appreciation that this extra attention contributes to is something that lingers for long after the book is read. Nevertheless, you don't need to be an author to have the same appreciation towards other people's books. This is something that grows the more you practice it and can evolve into a sense of discernment distinguishing books worth having on your bookshelf from those that you are better off leaving on the store! At the very least this ability can help you save time and money since it can help you focus on those books that have the most to offer to you. In my experience, Technics Publications has such books worth keeping close to you, particularly if you are interested in data-related topics. This includes data science but also other disciplines like data modeling, data governance, etc. There is even a book on Blockchain, which I found very educational when I was looking into this technology, which goes beyond its cryptocurrency applications. Anyway, since good books come at a higher cost, you may want to take advantage of a special promo the publisher is doing, which gives you a 20% discount for all books, except the DMBOK ones. To get this discount, just use the DSML coupon code at the checkout (see image below). 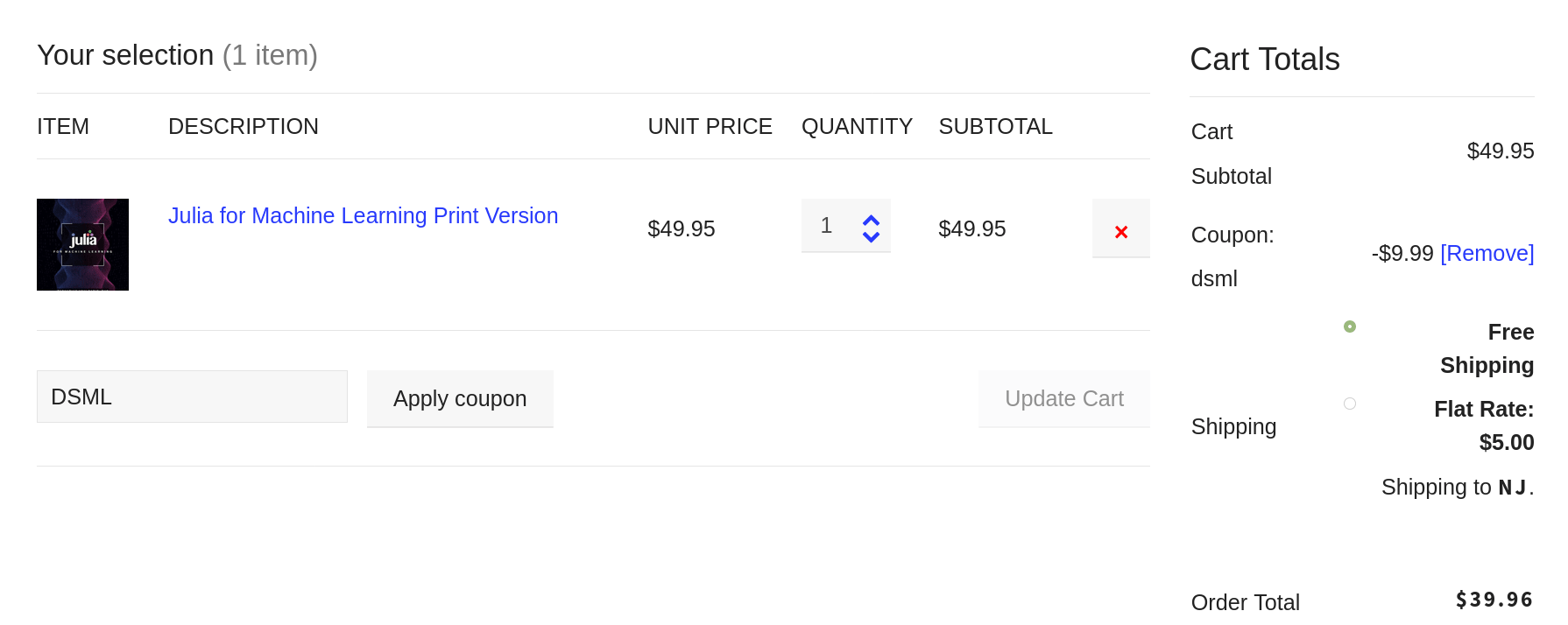 Note that this coupon code applies to virtual classes offered by Technics Publications (i.e. the virtual training courses in the ASK series). This, however, is a topic for another article. Cheers!  Hi everyone. Since these days I explore a different avenue for data science education, I've put together another webinar that's just 3 weeks away (May 18th). If you are interested in AI, be it as a data science professional or a stakeholder in data science projects, this is something that can add value to you. Also, you'll have a chance to ask me questions directly and if the time allows, even have a short discussion on this topic.
Note that due to the success of previous webinars in the Technics Publications platforms, the price of each webinar has risen. However, this upcoming webinar, which was originally designed as a talk for an international conference in Germany, is still at the very accessible price of $14.99. Feel free to check it out here and spread the word to friends or colleagues. You can also learn about the other webinars this platform offers through the corresponding web page. Cheers!  These days I didn't have a chance to prepare an article for my blog. Between helping out a friend of mine and preparing for my webinar this Thursday, I didn't have the headspace to write anything. Nevertheless, one of the articles I wrote for my friend's initiative, related to mentoring, is now available on Medium. Feel free to check it out! As for the webinar, it's about the data science mindset, a topic I talked about on all of my books, particularly the Data Science Mindset, Methodologies, and Misconceptions one. At the time of this writing, there are still some spots available for the webinars, so if you are interested, feel free to register for it here. On another note, my latest book is almost ready for the review stage so I'll be working on that come Friday. Stay tuned for more details in the weeks to come... That's all for now. I hope you have a great week. Stay healthy and positive!  With more and more people getting into data science and AI these days, certain aspects of the field are inevitably over-emphasized while others are neglected. Naturally, those providing the corresponding know-how are not professional educators, even if they are competent practitioners and very knowledgeable people. As a result, a lot of emphasis is given to the technical aspects, such as math and programming related skills, data visualization, etc. What about domain knowledge though? Where does that fit in the whole picture? Domain knowledge is all that knowledge that is specific to the domain data science or AI is applied on. If you are in the finance industry, it involves economics theory as well as how certain econometric indexes come into play. In the epidemiology sector, it involves some knowledge as to how viruses come about, how they propagate, and their effects on the organisms they exploit. Naturally, even if domain knowledge is specialized, it may play an important role in many cases. How much exactly depends on the problem at hand as well as how deep the data scientist or AI practitioner wants to go into the subject. Domain knowledge may also include certain business-related aspects that also factor in data science work. Understanding the role of the different individuals who participate in a project is very important, especially if you are tackling a problem that is too complex for data professionals alone. Oftentimes, in projects like this, subject matter experts (SMEs) are utilized and as a data scientist or AI professional you need to liaise with them. This is not always easy as there is limited common ground that can be used as a frame of reference. That's where some general-purpose business knowledge comes in handy. Naturally, incorporating domain knowledge in a data science project is a challenge in and of itself. Even if you do have this non-technical knowledge, you need to find ways to include it in the project organically, adding value to your analysis. That's why certain questions, particularly high-level questions that the stakeholders may want to be answered, are very important. Pairing these questions with other, more low-level questions that have to do with the data at hand, is crucial. Part of being a holistic, well-rounded data science / AI professional involves being able to accomplish this. Of course, exploring this vast topic in a single or even multiple blog posts isn’t practical. Besides, how much can someone go into depth about this subject without getting difficult to read, especially if you are accessing this blog site via a mobile device? For this purpose, my co-author and I have gathered all the material we have accumulated on this topic and put it in a more refined form, namely a technical book. We are now at the final stages of this book, which is titled “Data Scientist Bedside Manner” and is published by Technics Publications. The book should be available before the end of the season. Stay tuned for more details...  Webinars have been a valuable educational resource for years now, but only recently has the potential of this technology been valued so much. This is largely due to the Covid-19 situation that has made conventional conferences a no-no. Also, the low cost of webinars, coupled with the ecological advantage they have over their physical counterparts, makes webinars a great alternative. At a time when video-based content is in abundance, it's easy to find something to watch and potentially educate yourself with. However, if you want quality content and value your time more than the ease of accessibility of the stuff available for free, it's worth exploring the webinar option. Besides, nowadays the technology is more affordable than ever before, making it a high ROI endeavor. As a bonus, you get to ask the presenter questions and do a bit of networking too. How does all this fit with data science though and why is it part of this blog? Well, although webinars are good in general, they are particularly useful in data science as the latter is a hot topic. Because it's such a popular subject, data science has attracted all sorts of opportunists who brand themselves as data scientists just to make a quick buck. These people tend to create all sorts of content that is low veracity information at best (and a scam at worst). Since discerning between what's legitimate content and what's just click-bait can sometimes be difficult (these con artists have become pretty good at what they do), it makes sense to pursue reputable sources for this video content. One such source is the Technics Publications platform, which has recently started providing its own video content in the form of webinars. Although most of these webinars are on data modeling, a couple of them are on data science topics (ahem). Feel free to check them out! Disclaimer: I have a direct monetary benefit in promoting these data science webinars. However, I do so after ensuring I put a lot of work in preparing them, the same amount of work I’d put in preparing for a physical conference, like Customer Identity World and Data Modeling Zone. The only difference is the medium through which this content is delivered.  What’s a Transductive Model?
A transductive model is a predictive analytics model that makes use of distances or similarities. Contrary to inference models that make use of induction and deduction to make their predictions, transductive models tend to be direct. Oftentimes, they don’t even have a training phase in the sense that the model “learns” as it performs its predictions on the testing set. Transductive models are generally under the machine learning umbrella and so far they have always been opaque (black boxes). What’s Transparency in a Predictive Analytics Model? Transparency is an umbrella term for anything that lends itself to a clear understanding of how it makes its predictions and/or how to interpret its results. Statistical models boast transparency since they are simple enough to understand and explain (but not simplistic). Transparency is valued greatly particularly when it comes to business decisions that use the outputs of a predictive model. For example, if you decide to let an employee go, you want to be able to explain why, be it to your manager, to your team, or the employee himself. Transparent kNN? Transparent kNN sounds like an oxymoron, partly because the basic algorithm itself is a moron. It's very hard to think of a simpler and more basic algorithm in machine learning. This, however, hasn't stopped people from using it again and again due to the high speed it exhibits, particularly in smaller datasets. Still, kNN has been a black box so far, despite its many variants, some of which are ingenious indeed. Lately, I've been experimenting with distances and on how they can be broken down into their fundamental components. As a result, I managed to develop a method for a distance metric that is transparent by design. By employing this same metric on the kNN model, and by applying some tweaks in various parts of it, the transparent version of kNN came about. In particular, this transparent kNN model yields not only its predictions about the data at hand but also a confidence metric (akin to a probability score for each one of its predictions) and a weight matrix consisting of the weight each feature has in each one of its predictions. Naturally, as kNN is a model used in both classification and regression, all of the above are available in either one of its modalities. On top of that, the system can identify what modality to use based on the target variable of the training set. What’s Next? For now, I’ll probably continue with other, more useful matters, such as feature fusion. After all, just like most machine learning models, kNN is at the mercy of the features it is given. If I were in academic research, I’d probably write a series of papers on this topic, but as I work solo on these endeavors, I need to prioritize. However, for anyone interested in learning more about this, I’m happy to reply to any queries through this blog. Cheers!  (image by Arek Socha, available at pixabay) Lately, I've been working on the final parts of my latest book, which is contracted for the end of Spring this year. As this is probably going to be my last technical book for the foreseeable future, I'd like to put my best into it, given the available resources of time and energy. This is one of the reasons I haven't been very active on this blog as of late. In this book (whose details I’m going to reveal when it’s in the printing press) I examine various aspects of data science in a quite hands-on way. One of these aspects, which I often talk about with my mentees, is that of scale. Scaling is very important in data science projects, particularly those involving distance-based metrics. Although the latter may be a bit niche from a modern standpoint where A.I. based systems are often the go-to option, there is still a lot of value in distances as they are usually the prima materia of almost all similarity metrics. Similarity-based systems, aka transductive systems, are quite popular even in this era of A.I. based models. This is particularly the case in clustering problems, whereby both the clustering algorithms and the evaluation metrics (e.g. Silhouette score/width) are based on distances for evaluating cluster affinity. Also, certain dimensionality reduction methods like Principle Components Analysis (PCA) often require a certain kind of scaling to function optimally. Scaling is not as simple as it may first seem. After all, it greatly depends on the application as well as the data itself (something not everyone is aware of since the way scaling/normalization is treated in data science educational material is somewhat superficial). For example, you can have a fixed range scaling process or a fixed center one. You can even have a fixed range and fixed center one at the same time if you wish, though it's not something you'd normally see anywhere. Fixed scaling is usually in the [0, 1] interval and it involves scaling the data so that its range is constant. The center point of that data (usually measured with the arithmetic mean/average), however, could be distorted. How much so depends on the structure of the data. As for the fixed center scaling, this ensures that the center of the scaled variable is a given value, usually 0. In many cases, the spread of the scaled data is fixed too, usually by setting the standard deviation to 1. Programmatic methods for performing scaling vary, perhaps more than the Stats educators will have you think. For example, in the fixed range scaling, you could use the min-max normalization (aka 0-1 normalization, a term that shows both limited understanding of the topic and vagueness), or you could use a non-linear function that is also bound by these values. The advantage of the latter is that you can mitigate the effect of any outliers, without having to eradicate them, all through the use of good old-fashioned Math! Naturally, most Stats educators shy away at the mention of the word non-linear since they like to keep things simple (perhaps too simple) so don’t expect to learn about this kind of fixed-range scaling in a Stats book. All in all, scaling is something worth keeping in mind when dealing with data, particularly when using a distance-based method or a dimensionality reduction process like PCA. Naturally, there is more to the topic than meets the eye, plus as a process, it's not as basic as it may seem through the lens of package documentation or a Stats book. Whatever the case, it's something worth utilizing, always in tandem with other data engineering tools to ensure a better quality data science project.  Hello everyone and happy new year! I hope you all had a good holiday break. I thought about it quite a bit and I've decided this year to go a different direction with the videos I make as I plan to focus more on courses. Stay tuned for more news on this matter in the weeks to come...  Just wanted to wish you all Happy Holidays! It's been a great year and I appreciate your support through this blog. I won't be posting anything new in the next couple of weeks as I'll b traveling. Feel free to check out some of my older posts, though. I hope your holidays are insightful, inspirational, and intriguing! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
December 2022
Categories
All
|
 RSS Feed
RSS Feed