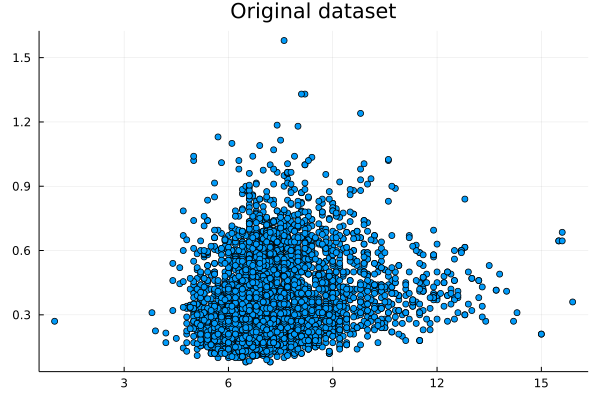
 I was never into Sampling techniques, even though I had to code a couple of them from scratch during my Ph.D. as there was no K-fold cross-validation method in Matlab at the time. Although nowadays it seems masochistic for me to code in Matlab, I am grateful for the experience. After all, the Julia language that I use regularly is very similar to Matlab in terms of syntax so this experience with Matlab coding made the learning of Julia easier and faster. Could it be possible that we could make data summarization easy and fast too, hopefully without resorting to any closed-source software like Matlab? This question has kept me wondering for a while now (perhaps more than I'm willing to admit!) partly because my data structures know-how wasn't there yet. Lately, however, I learned all about K-D trees, which are a more generalized form of binary search trees. I even published an article about it on the AIgents platform. In any case, K-D trees enable the quick finding of nearest neighbors as well as the filtering of data points within a given distance (I deliberately avoid saying hypersphere because if you've dealt with high-dimensional data as I've had, you probably detest that shape too!). In any case, finding points within a given distance (or radius if you are geometrically inclined) is necessary if you were to examine different areas of the dataset, particularly if you want to do that a lot. Since K-D trees make that easy and scalable, one can only wonder why no one ever thought about using them in data summarization yet. In simple terms, data summarization is representing the information of the original dataset with fewer data points (the fewer the better). Of course, you can do that using a centrality metric of your preference but summarizing a whole dataset, or even a variable, with one point creates more problems than it solves. It's this naive approach to data summarization that has brought about all the prejudices and discriminatory behavior over the years. Nassim Taleb is also very critical of all this and that's someone who has been around more and thought about things in more depth than most of us. Anyhow, data summarization is tricky and relatively slow. It's much easier to take a (hopefully random and unbiased) sample, right? Sure, but what if we don't want to take any chances and want to reduce the dataset optimally instead? Well, then we have no choice but to employ a data summarization method. The one I've developed recently, employing a couple of heuristics, does the trick relatively fast, plus it scales reasonably well (also, it's entirely automated, so there's no need to worry about normalization or the size of the summary dataset). Attached are the dataset I used (related to Portuguese wines) and a couple of plots, one for the first two variables of the dataset and one for the reduced version of that. The method works with K-dimensional data, but for the sake of demonstration, I only used two of them. For all this, along with a vector for the weights of the created data points, it took around 0.4 seconds on my 5-year-old machine. The reduction rate was about 65%, which is quite decent. For the whole dataset (all 13 variables) it took a bit longer: ~ 29 seconds, with a 54% reduction rate. Although the method seems promising, there are probably a few more optimizations that can be performed to it, to make it even more scalable. However, it’s a good start, particularly if you consider the new possibilities such a method offers. The one obvious one, which I’ve already explored, is data generation. The latter can be done independently from the data summarization part, but it works better if summarized data is used as an input. Another low-hanging fruit kind of application that's worth looking into is dimensionality reduction, based on the summarized dataset. All of these, however, is a story for another time. Cheers!
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
April 2024
Categories
All
|
||

 RSS Feed
RSS Feed