 Ensembles are sophisticated machine learning models that comprise of other simpler models. They are quite useful when accuracy is the fundamental requirement, and computational resources are not a severe limitation. Ensembles are trendy in all sorts of current projects as they have significant advantages over conventional models. Let's take a closer look at this through this not-too-technical article. Ensembles are an essential part of modern data science as they are more robust and powerful as models. Additionally, ensembles are ideal in cases of complex problems (something increasingly common in data science), as they can provide better generalization and more stability. In cases where conventional models fail to provide decent results, ensembles tend to work well enough to justify using data science in the problem at hand. That's why data scientists usually use them after all attempts to solve the problem with conventional models have failed. The most common kind of ensembles is those based on the decision tree model. The main reason for this is because this kind of model is relatively fast to build and train, while it yields reasonably good performance. What's more, it's easy to interpret, something that bleeds to the ensemble itself, making it a relatively transparent model. Other ensembles are based on the combination of different models, belonging to different families. This heterogeneous architecture in the ensemble enables it to be more diverse in processing the data and to yield better performance. For all the ensembles out there, there needs to be a heuristic in place to figure out how the different outputs of the models that comprise the ensemble are fused. The most straightforward such heuristic is the majority voting, which works quite well in cases when all the ensemble models are similar. The main drawback of ensembles is a particular comprise you have to make when using them. Namely, the transparency greatly diminishes, while in some cases, it disappears altogether. This phenomenon can be an issue when you need the model you built to be somewhat interpretable. Additionally, ensembles can overfit if the dataset isn't large enough or if they comprise of a large number of models. That's why they require special care and are better off being handled by experienced data scientists. Finally, ensembles require more computational resources than most data models. As a result, you need to have a good reason for using them in a large-scale scenario, since they can be quite costly. You can learn more about ensembles and other machine learning topics in one of my recent books. Namely, in the Julia for Machine Learning book, published last year, I extensively cover ensembles and several other relative topics. Using Julia as the language through which the various machine learning models and methods are implemented, I examine how all this can be useful in handling a data science project robustly. Check it out when you have a moment. Cheers!
0 Comments
 Questions are an integral part of scientific work, especially when research is concerned. Without questions, we can't have experiments and the capability of testing our observations with our current understanding of the world. Naturally, this applies to all aspects of science, including one of its most modern expressions: data science. This article will explore the value of questions in science, how they relate to hypotheses, and how data science comes into the picture. Questions are what we ask to figure out how things fit in the puzzle of scientific work. They can be general or specific (the latter being more common), and they are always linked to hypotheses in one way or another. The latter are the formal expressions of questions and usually take a true or false label, based on the tests involved. Tests are related to experimentation, whereby we see how the evidence (data) accumulated fits the assumptions we make. Without questions and hypotheses, we cannot have scientific theories and anything else useful in this paradigm of thought. Note that all this is possible because we are open to being wrong and are genuinely curious to find out what's going on in the area we are investigating. Questions and hypotheses are also vital because they are a crucial part of the scientific method, the cornerstone of science. Since its inception a few centuries ago, the scientific method has laid the framework of scientific work, particularly in forming new theories and developing a solid understanding of the world. It's closely tied to experimentation since, at its core, science is empirical and relies on observable data rather than predefined ideas. Although it's not as prominent as it used to be, the latter is in the realm of philosophy, although it has a role in science. The scientific method is precise and relies on a disciplined methodology in scientific work, but it's also open to creativity. After all, not all questions are deterministic and predictable; some of them may be led by a deeper understanding of the world, led by intuition. But how does all this relate to data science? First of all, data science is the application of scientific methodologies in problems beyond scientific research. This way, it is a broader application of scientific principles and the scientific method, involving data from all domains. Because of this, it's crucial to think about questions and try to answer them as systematically as we can, using the various data analysis methodologies at our disposal. Not all of these methodologies are as clear-cut and easy as Statistics. Still, all of them involve some models that try to describe or predict what would happen when new data comes into play, something rudimentary in scientific work. If you wish to learn more about this topic and data science's application of the scientific method, check out my latest book Doing Science Using Data Science. In this book, my co-author and I explore various science-related topics, emphasizing the practical application of data science methodologies, describing how these ideas are implemented in practice. The book is accompanied by a series of Jupyter notebooks, using Julia and Python. Check it out when you have a moment. Cheers!  Machine Learning is the field involved in using various algorithms that enable a machine (typically a computer) to learn from the data available, without making any assumptions about it. It includes multiple models, some simpler, others more advanced, that go beyond the statistical analysis of the data. Most of these models are black-boxes, though a few exhibit some interpretability. Yet, despite how well-defined this field is, several misconceptions about it conceal it in a veil of mystique. First of all, machine learning is not the same as artificial intelligence (A.I.). There is an overlap, no doubt, but they are distinct fields. You can spend your whole life working in machine learning without ever using A.I. and vice versa. The overlap between the two takes the form of deep learning, the use of sophisticated artificial neural networks that are leveraged for machine learning tasks. Computer Vision is an area of application related to the overlap between machine learning and A.I. What’s more, machine learning is not an extension of Statistics. Contrary to what many Stats fans say, machine learning is an entirely different field distinct from Statistics. There are similarities, of course, but they have fundamental differences. One of the key ones is that machine learning is data-driven, i.e., it doesn't use any mathematical model to describe the data at hand, while Statistics does just that. It's hard to imagine Statistical models without a data distribution or some function describing the mapping, while machine learning models can be heuristics-based instead. Nevertheless, machine learning is not purely heuristics-based and, therefore, void of theoretical foundations. Even if it doesn't have the 200-year-old amalgamation of the Statistics theory, machine learning has some theoretical standing based on the few decades of research on its back. Many of its methods rely on heuristics that "just work," but it's not what people consider alchemy. Machine learning is a respectable scientific field with lots to offer both to the practitioner and the researcher. Beyond the misconceptions mentioned earlier, there are additional ones that are worth considering. For example, machine learning is not plug-and-play, as some people think, no matter how intuitive the corresponding libraries are. What's more, machine learning is not always the best option for the problem at hand, since some projects are okay with something simple that's easy to understand and interpret. In cases like that, a statistical model would do just fine. It's hard to do this topic justice in a single blog post, but hopefully, this has given you an idea of what machine learning is and what it isn't. I talk more about this subject in one of my most recent books, Julia for Machine Learning. Additionally, I plan to cover this topic in some depth in a 90-minute talk at the next Data Modeling Zone conference in Belgium this April. I hope to see you there! Cheers.  Non-Negative Matrix Factorization (NNMF or NMF) is a powerful method used in Recommender Systems, Topic Modeling in NLP, Image analysis, and various other areas. It involves breaking a matrix into a product of two other matrices, having either positive or zero values in them. The idea is to preserve meaning in the components derived since, in some cases, it doesn't make sense to have negative values in them (e.g., in Topic Modeling, you can't have a document with a negative membership to any given topic). NNMF is not an exact science, since it's an NP-hard problem. As a result, we try to find an approximate solution using various tricks. Although some people view NNMF as Stats-based, it is a machine learning technique based on Linear Algebra and Optimization. The math of NNMF is relatively straight-forward, though not something you would do with pen and paper, or even a calculator! There are various approaches to NNMF, involving finding two matrices W and H, such that the norm of the original matrix X minus W*F is minimal, all while W and H being non-negative: 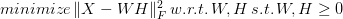 The norm part is the objective function of this minimization problem, by the way. Two common ways to accomplish this are the multiplicative update (gradually approximating W and H, using a particular rule), and the Hierarchical Alternating Least Squares (HALS) method, which attempts to find the columns of W one by one, through.
A common trick for NNMF is to use Singular Value Decomposition (SVD) first to find a rough approximation for W and H and then refine it gradually. Alternatively, we can use regularization to ensure that W and H's elements remain relatively small, resulting in a more stable solution. However, keep in mind that the solutions NNMF yields are approximate and correspond to local minima of the objective function. Fortunately, there are programming libraries that do all the heavy-lifting for us when it comes to NNMF. One such library is the NMF.jl one, in Julia. If you are more of a Python user, you can use the NMF function from the decomposition class of the sklearn package. Both of these libraries are well-documented so getting the hand of them is relatively straight-forward. You can learn more about data science methods like this one in my book, Data Science Mindset, Methodologies, and Misconceptions. In this book, I talk about all kinds of processes and techniques used in data science so that even the non-technical reader can grasp the intuition behind them and gain an understanding and appreciation of them. This book provides several external resources to go more in-depth on these topics and organize how you continue learning about this field, without getting lost in it. So, check it out when you have some time. Cheers!  Ever since machine learning and artificial intelligence (A.I.) became mainstream, there has been a lot of confusion between the two and how they relate to data science. Considering how superficial the mainstream understanding of the subject is, it's no wonder that many people who first learn about data science consider them the same. However, if you are to learn data science in-depth and do something useful with it, it's best to know how to differentiate between the two and know when to use what, for the problem at hand. To disambiguate the two, let’s look at what each one of them is. First all, machine learning is a set of methodologies involving a data-driven approach to data modeling as well as the evaluation of the data at hand. It includes various models like decision trees, support vector machines, etc. as well as a series of heuristics. The latter is used for assessing features or models in a way that's void of any assumptions about the distributions of the data involved. Machine learning sometimes makes use of basic Stats but it is a separate field altogether, part of the core of data science. Some machine learning models are based on A.I. though most of them are not. As for artificial intelligence, it is a field separate from data science altogether. It involves systems that emulate sentient behavior, in various domains. Computer Vision, for example, is a part of A.I. that involves interpreting images (usually captured by a camera or a video stream) to understand what objects are in the vicinity. Natural Language Processing (NLP) involves looking at a piece of text and working out what it is about or even synthesizing text on the same topic. Naturally, there is an overlap between A.I. and machine learning (as in the case of deep learning models), though this is fairly limited. For example, advanced optimization methods are a key application of A.I. that has nothing to do with machine learning per se, even if it is sometimes employed in the more advanced models. Beyond the differences that emerge from the above descriptions of the two fields, there are a few more that's worth keeping in mind. Namely, machine learning models can often be interpreted, at least to some extent. On the other hand, (modern) A.I. models are black boxes, at least for the time being. What's more, machine learning models come in a variety of types, while A.I. ones are graph-based. Additionally, A.I. has a more diverse range of applications, while machine learning is limited to specific ways that are related to data science work. Finally, in machine learning, you need to do some data engineering before you work your models, while in A.I. it's rarely the case (even though it can be very helpful). If you are interested in this topic (particularly classical machine learning), you learn more about it through my book Julia for Machine Learning, published last Spring. This book is very hands-on, having plenty of examples that illustrate how machine learning methods work, be if for data engineering or data modeling tasks. The language used (Julia) is an up-and-coming data science language that boasts several packages under the machine learning umbrella. In this book, we explore the most important of them, which have stood the test of time. Check it out when you have the chance. Cheers!  Recommender systems are specialized models that make recommendations about how data points are connected within a dataset, without a clear distinction between training and testing data. They are based on the concept of interactions, which are the links between pairs of data points. Recommender systems are essential as an application of data science and are widely used today in various domains. This article will explore the various kinds of recommender systems and some useful recommendations about how you can go about building them. First of all, the data recommender systems utilize consists of two main parts: the characteristic information (user data, keywords, categories, etc.) and user-item interactions data (e.g., review scores, number of likes, items bought, etc.). This data usually dwells in two different matrices, which constitute the recommender system's dataset. Note that these matrices can increase in size as new users or new items become available, something quite common in many recommender system scenarios. There are various types of recommender systems, depending on how the data is used. There are collaborative filters (based on the interactions in the user-items data), content-based systems (employing the characteristic data), and combinations of the two, aka, hybrid models. These recommender systems types are useful, but each has its use cases, where it shines. Yet, regardless of what systems are out there, you need to make sure you understand the data at hand before you start building your recommender system. After all, just because a particular kind of RS model works well for some problems, it doesn't mean it would work well with yours. That's why you need to examine your data closely and figure out what model is best suited for it. If, for example, you don't have enough user-item interaction data at your disposal, you may want to go for a content-based model, or perhaps a hybrid one. Also, if you need to add new items or new users to your dataset often, then maybe you should avoid collaborative filters altogether. What's more, you may want to explore the deep learning option since deep neural networks (fully connected ones) handle this sort of problem. Of course, it's best to have lots of data for such a scenario for the DNNs to have a performance edge justifying the computation costs involved. So, it's good to consider other options, such as a simpler model for your recommender system. Also, note that the model you build has to be aligned with the project's requirements at hand. However, it’s not just DNNs that require lots of data to work well. Collaborative filtering models are also in need of lots of information to work with to be useful. This data needs to be mainly in the interactions matrix; otherwise, the model won't work correctly, making more random recommendations. That's why data acquisition and data engineering are particularly crucial for recommender systems in general. Beyond all these suggestions, you ought to have a good understanding of the functionality of recommender systems and the right mindset towards such problems. Additionally, you need to check the models after new data is added to the dataset, particularly new items. That's because these will take the form of empty columns in the user-item matrix, making the latter sparser and, therefore, the model less robust. However, there are ways around this issue, which stems from a good understanding of the recommender systems themselves. If you wish to learn more about RS and the data science mindset in general, I invite you to check out my book Data Science Mindset, Methodologies, and Misconceptions. It’s been a few years now that it was published, but its content is still relevant and useful for any data scientist. So, check it out when you have the chance. Cheers!  Data science knowledge is vast and varied. It entails an in-depth understanding of data, the impact of models on this data, and various ways to refine the data making it more useful for these models. Also, it has to do with ways to depict this data graphically and make useful predictions based on it, using new data as inputs. Specialized data science knowledge also involves depicting this data in different ways (e.g. via a graph structure), gathering it from various sources (e.g. text), and creating interactive applications based on the data models built. Naturally, all this can be of value not just to data scientists but also to other data-related professionals. Let's examine how. So, how can data science knowledge help data analysts and business intelligence professionals? After all, they are the closest to the role of a data scientist and deal with data in similar ways. These professionals can benefit from data science knowledge through a more in-depth understanding of the data, particularly when it comes to ETL processes and data wrangling. Also, for those more geared towards data models, they can learn more advanced models such as the machine learning models data scientists use and start using them in their work. As for data modelers (data architects), data science knowledge can help those professionals too. After all, designing a useful information flow or implementing such a design into a database is closely linked to how this information is used. So, by understanding the potential different variables have (something that's bread and butter for a data scientist), a data modeler can optimize his work and build systems that are more future-tolerant. That is particularly useful in cases where the domain is dynamic, like in the e-commerce field. Programmers can benefit a lot from data science knowledge too, especially those versed in OOP and functional languages (e.g. Julia and Scala). After all, data science involves a great deal of programming so there is a good overlap in the skill set of the two types of professionals. For this reason, many programmers end up getting into data science once they familiarize themselves with data science models, something they can do easily once they get exposed to data science knowledge. Finally, data-driven managers have a lot to gain from data science knowledge, perhaps more than any other professional. The reason is that f you are involved in data-driven projects, you need to know what’s possible with the data you have and what kind of products or services you can build using this data. This is something you can do even without getting your hands dirty, by thinking in terms of data science. So, having some data science knowledge (particularly knowledge related to how data science is applicable and what data products look like), can go a long way. As a bonus, recruiting data scientists to implement your ideas is much easier if you are familiar with data science, something your recruits are bound to appreciate. If you found this article interesting, you can learn more about data science and how it is leveraged in an organization through a book I co-authored last year. Namely, the Data Scientist Bedside Manner book covers this and similar topics thoroughly, along with some other practical knowledge on this subject. So, check it when you have the chance and spread the word about it to friends and colleagues in the aforementioned lines of work. Cheers!  As you may have noticed, data analytics is always evolving as a field, so it's not surprising to see data science changes from year to year. What was hot and trendy in 2020 may not be as prominent soon and vice versa. That's not to say that you should expect to see drastic changes in 2021, but it's good to adapt your expectations, taking into account the latest trends. In this article, we'll explore all that and see how you can benefit from these insights for your career in data science. It's no secret that deep learning is gaining even more popularity, particularly in time series analysis. So, RNNs are bound to rise in demand as a skill, particularly if you are involved in the field's forecasting part. Additionally, healthcare seems to be becoming more aligned with this tech, so it is expected that more medicine-related organizations are going to be looking for data scientists to join their ranks. What's more, IoT is expected to incorporate AI, making our work more relevant to infrastructure projects. Moreover, we should be expecting Reinforcement Learning (RL) to grow further as to use cases of it, such as chat-bots, are growing in popularity. Finally, it seems that more and more people are becoming aware of data science and AI's benefits, so it's easier than ever to make the business case for advanced analytics in a company. Simultaneously, the cloud provides a viable solution for the hardware required, something that's bound to stick in the coming years. Based on the above, it’s reasonable to deduce that the data science specializations more likely to be more relevant this coming year are AI expert, data engineer (particularly the one geared towards machine learning, aka, machine learning engineer), and those data scientists with domain knowledge in healthcare and IoT. Naturally, Natural Language Processing experts are bound to remain in demand, particularly if they possess chat-bot know-how. Beyond all that, it’s important to remember that the one thing that’s bound to remain relevant in the years to come, regardless of these trends, is the data science mindset. This mindset involves various aspects, such as problem-solving skills, creativity applied in analytics work, meeting deadlines, and collaborating with other data professionals, to name a few. The data science mindset is our attitude towards the data science problems we have to solve. As such, it's something essential and perhaps more relevant than whatever skill is in vogue at any given time. You can learn more about the data science mindset and other relevant topics in this field through one of my books, titled Data Science Mindset, Methodologies, and Misconceptions. There I explore the various aspects of the field without getting too technical, all while highlighting those skills that make up the data science mindset. I include some soft skills and some hard ones that are still relevant today, even if some of the tools have evolved since then. So, check it out when you have a moment. Cheers!  Data science work entails a large number of tasks, spanning across the data analytics spectrum, but with an emphasis on predictive analytics. Also, it involves a lot of investigation of the data at hand (Exploratory Data Analysis), the use of advanced math (e.g. Graph Analytics and Optimization), as well as some understanding of the domain to facilitate communication with the stakeholders of the data science project. It also includes querying databases, combining data from various sources (sometimes in real-time), and putting all the findings together in a narrative that's jargon-free and easy to follow. Oftentimes, this is not possible to do with a single individual, which is why data science teams are commonplace, particularly in larger organizations. Data science consultancy is performing these tasks (or at least some of them) on a project basis, without being part of the organization. In this case, the data scientist is a guest star of sorts, working with analysts, data architects, BI professionals, or whoever manages products like this in that organization. She needs to ask questions to understand the problem at hand, what is required of her, the bigger picture of the project, and the data involved. This is something that can take several months and usually starts with a proof-of-concept project, particularly if the organization is new to data science. Naturally, because of the overheads of consultancy, a data scientist like that will be paid more, while it's not uncommon for the organization to cover logistical costs and other expenses. It would make more sense for the consultant data scientist to be at the organization permanently, cutting down the costs, right? Well, although theoretically, that's true, not every organization out there has the budget for an in-house data scientist. Oftentimes, the managers involved are not convinced regarding the value-add of data science, which is why they are more willing to work with consultants, even if that means paying more in the short-term. Besides, a data science consultant is bound to be better value for money since they focus on quality and good customer service. Many data science consultants have vastly more experience and broader domain knowledge too, making them a valuable asset, particularly if you need something done swiftly. Also, note that certain organizations have a strict policy when it comes to recruiting, so it's much easier for someone to hire a data science consultant than to go through the whole process of getting a full-time employee on board, especially if they aren't sure about their budget in the years to come. Since this is a very broad topic and it’s hard to do it justice in a single article, I decided to focus on the highlights of it. If you wish to learn more about the data science work in practice, along with other business-related matters relevant to the role of data scientist, I invite you to check out the Data Scientist Bedside Manner book I co-authored earlier this year. In it, we cover this topic from various angles along with some practical advice as to how you can make the bridging of the technical and the non-technical world smoother and effective. Cheers!  Data analytics is the field that deals with the analysis of data, usually for business-related objectives, though its scope covers any organization. A data analyst handles data with various tools, such as a spreadsheet program (usually MS Excel), a data visualization program (e.g. Tableau), a database program (e.g. PostgreSQL), and a programming language (usually Python), and then presents her findings using a presentation program (e.g. MS PowerPoint). This aids business decisions and provides useful insights into the state of an organization. It's akin to the Business Intelligence role, though a bit more hands-on and programming-related. What about Statistics though? Well, it is a potent data analytics tool but whether it's something a data analyst actually needs is quite debatable. Apart from some descriptive stats that you are bound to use in one way or another, the bulk of Statistics is way too specialized and irrelevant to a data analyst. It doesn't hurt knowing it but it would highly biased to promote this sort of knowledge (in most cases it doesn't even classify as know-how) when there are much more efficient and effective tools out there. For example, being about to handle the data coming from various sources and organize it, be it through an ETL tool or some data platform, is far more of a value-add than trying to do something that's often beyond the scope of your role as an analyst (e.g. an in-depth analysis of the data at hand, through advanced data engineering or predictive modeling). Having said that, Statistics is useful in data science, particularly if you are not well-versed in more advanced methodologies, such as machine learning. That’s why most data science courses start with this part of the toolbox along with the corresponding programming libraries. Also, most time-series analysis models are Stats-based and data scientists are often required to work with them, at least as a baseline before proceeding to build more complex models. Moreover, if you want to test a hypothesis (something quite common in data science work), you need to make use of statistical tests. In data analytics, however, where the objective is somewhat different, Stats seems to be a somewhat unnecessary tool. Perhaps that's why most data analysts focus on other more practical and guaranteed ways to add value, such as dashboards, intuitive spreadsheets, and useful scripts, rather than building statistical models that few people care about. Besides, if someone needs something more in-depth and scientifically sound, they can always hire a couple of data scientists to work alongside with the analysts. Regardless of your role, you can learn more about data science and the mindset behind it in my book Data Science Mindset, Methodologies, and Misconceptions. Although it was published about 4 years ago, it remains relevant and can shed a lot of light on Statistics' role in this field, as well as other methodologies and tools used by data scientists. Check it out when you have some time. Cheers! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
December 2022
Categories
All
|
 RSS Feed
RSS Feed