|
What Rust is I may have mentioned Rust in the past, but now I’d like to talk more about it and its role in data science and A.I., as it has passed the test of time, in my view. After having delved into Rust programming a bit, enough to understand that it's much more challenging than I realized at first, I believe I can now write about it with confidence. Also, since it's not so new to me, I'm way past the infatuation stage that characterizes most people who have talked or written about it, usually shortly after they started exploring it. So, Rust is a high-performance language, currently in version 1.51, and with a large enough community of users (and companies) to make a dent in the programming realm. There is even a Rust track in the Exercism platform, where there are dedicated mentors who can help you learn it through the carefully designed and curated programming drills on the Exercism website. What's more, there are a few interesting books on Rust, while there are also conferences and workshops for anyone serious about this language. Rust’s key strengths Rust isn't popular because of its particular name or its cool logo, though. Rust earned its popularity through the strengths it brings to the table and the value-adds that accompany its deployment. First of all, it's high-performance, meaning that you can use it instead of C, C++, or even Java. That's not an easy-to-accomplish thing, and few languages have accomplished that. Also, it offers this performance while maintaining a relatively high-level approach to programming, much like most modern languages that come about. Additionally, Rust is reliable and as safe as it gets. Many consider it to be better in that respect than even C, which has a series of memory management issues resulting in risky code. So, if you want to build a program that just works and won't make you sleep with your phone on at night (in case you'll need to fix an issue of a script you've shipped), Rust is a good option. Finally, Rust is geared towards productivity. It's not an academic language or something a bunch of hobbyists put together, far from that. Rust is built for devs and people who are dead serious about designing and deploying software. The language's well-written documentation adds to this. At the same time, its error messages, although frustrating at first, give you some actual insight as to what's wrong with your scripts (instead of some generic error message that's more of a puzzle than any real help for debugging your code). Rust and Data Science When it comes to data science work, particularly machine learning and AI-related tasks, Rust has the potential of being a great asset. I say this, even though I'm vested in another high-performance language, Julia, for which I've written extensively (my books on Julia) and continue to use up to this day. However, unlike those fanboys of this or the other data science language, I'm open to new possibilities, which I'm always eager to explore. So, even though I'm a long way from being a Rust veteran, I can see its merit in our field. So far, there are a few Rust packages for ML work, such as Smartcore and Linfa (plant juice in Italian), though, in all fairness, this codebase is nowhere near the variety and maturity of the likes of Scikit-learn in Python and the packages in the Julia ecosystem. Still, there is a lot of value Rust offers in this space, and as the community grows, we should be expecting to see the ML and A.I. libraries of Rust grow both in number and sophistication. Final thoughts It may seem a bit too early to tell, but it's not far-fetched to say that Rust is here to stay and make it. While high-level languages like Python had nothing more to offer than simplicity and ease-of-use (probably the main reason they made it to the data science world), Rust is closer to modern languages like Julia and Nim, which offer a serious performance boost. Its business proposition is unquestionable, its adoption higher than many people expected, and its potential of making a dent in machine learning is hard to contest. Once you get past its eccentric programming style, you may begin to view it with the respect and fondness it deserves. So, check it out when you have a moment. Cheers!
0 Comments
 Machine Learning is the field involved in using various algorithms that enable a machine (typically a computer) to learn from the data available, without making any assumptions about it. It includes multiple models, some simpler, others more advanced, that go beyond the statistical analysis of the data. Most of these models are black-boxes, though a few exhibit some interpretability. Yet, despite how well-defined this field is, several misconceptions about it conceal it in a veil of mystique. First of all, machine learning is not the same as artificial intelligence (A.I.). There is an overlap, no doubt, but they are distinct fields. You can spend your whole life working in machine learning without ever using A.I. and vice versa. The overlap between the two takes the form of deep learning, the use of sophisticated artificial neural networks that are leveraged for machine learning tasks. Computer Vision is an area of application related to the overlap between machine learning and A.I. What’s more, machine learning is not an extension of Statistics. Contrary to what many Stats fans say, machine learning is an entirely different field distinct from Statistics. There are similarities, of course, but they have fundamental differences. One of the key ones is that machine learning is data-driven, i.e., it doesn't use any mathematical model to describe the data at hand, while Statistics does just that. It's hard to imagine Statistical models without a data distribution or some function describing the mapping, while machine learning models can be heuristics-based instead. Nevertheless, machine learning is not purely heuristics-based and, therefore, void of theoretical foundations. Even if it doesn't have the 200-year-old amalgamation of the Statistics theory, machine learning has some theoretical standing based on the few decades of research on its back. Many of its methods rely on heuristics that "just work," but it's not what people consider alchemy. Machine learning is a respectable scientific field with lots to offer both to the practitioner and the researcher. Beyond the misconceptions mentioned earlier, there are additional ones that are worth considering. For example, machine learning is not plug-and-play, as some people think, no matter how intuitive the corresponding libraries are. What's more, machine learning is not always the best option for the problem at hand, since some projects are okay with something simple that's easy to understand and interpret. In cases like that, a statistical model would do just fine. It's hard to do this topic justice in a single blog post, but hopefully, this has given you an idea of what machine learning is and what it isn't. I talk more about this subject in one of my most recent books, Julia for Machine Learning. Additionally, I plan to cover this topic in some depth in a 90-minute talk at the next Data Modeling Zone conference in Belgium this April. I hope to see you there! Cheers.  Like any project in an organization, a data science project needs to have boundaries regarding how many resources are allocated to it. This resource usage translates into a monetary cost that takes the form of a budget. So, even if many professionals in this field are not aware of it, budgeting plays an essential role in every data science project and provides the framework through which it can manifest. Despite its similarities to other projects, data science projects differ in many ways. First of all, its return isn't clear or even guaranteed. A data science team may investigate a dataset for insights or predictive potential, but it may not dig up something worthwhile. The data in a company's databases may be useful for its day-to-day tasks but useless for anything data science-related. It's next to impossible to know if there is anything worthwhile beforehand, so when starting a project, you have to take significant risks. As for the project's time frame, that's also highly uncertain, especially if it's a new project. This uncertainty can veer the project off-course, and the risk of going over-budget is substantial. When creating a budget for a data science project, several factors are considered to mitigate the risk of failure. First of all, you need to have a clear plan of what you expect from the data science team to find. If possible, you could have some ideas as to how you could translate these findings into a value-add, be it through a revenue stream, some improvement in the customer/user experience, or some enhancement in the organization's workflow efficiency. What’s more, it's good to examine a data science project from various perspectives and ensure that the data scientists involved have peace of mind when working on it. It's not just up to them to make it work, since the other stakeholders have a responsibility in it too. For example, the data owners need to do their part and ensure that the data science teams receive all the data it needs promptly. The developers involved need to have sufficient bandwidth to help with any ETL and other project processes. Finally, the business people need to have realistic expectations of what the data science team can deliver and how to leverage their work. Beyond the above factors that you need to consider, some additional considerations are useful to have when creating a budget. For instance, the cost of cloud computing involved is something that can get out of hand quickly, especially if you are not used to working at a particular scale of data. Sometimes it's more effective to have dedicated servers available to you instead of a leasing computing power in a virtual machine. Also, it would make sense to start with a proof-of-concept project to gain a better understanding of the problem at hand before going at it with full force. You can learn more about this, and the other less technical aspects of data science work through one of the books I co-authored relatively recently. Namely, the Data Scientist Bedside Manner book delves into this topic and explores data science from a perspective few people consider. Using information from various sources, including some experienced professionals in the field, provides guidance both for the data-driven manager and the data science professional, bridging the gap between the two. Check it out when you have the chance. Cheers!  Non-Negative Matrix Factorization (NNMF or NMF) is a powerful method used in Recommender Systems, Topic Modeling in NLP, Image analysis, and various other areas. It involves breaking a matrix into a product of two other matrices, having either positive or zero values in them. The idea is to preserve meaning in the components derived since, in some cases, it doesn't make sense to have negative values in them (e.g., in Topic Modeling, you can't have a document with a negative membership to any given topic). NNMF is not an exact science, since it's an NP-hard problem. As a result, we try to find an approximate solution using various tricks. Although some people view NNMF as Stats-based, it is a machine learning technique based on Linear Algebra and Optimization. The math of NNMF is relatively straight-forward, though not something you would do with pen and paper, or even a calculator! There are various approaches to NNMF, involving finding two matrices W and H, such that the norm of the original matrix X minus W*F is minimal, all while W and H being non-negative: 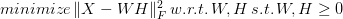 The norm part is the objective function of this minimization problem, by the way. Two common ways to accomplish this are the multiplicative update (gradually approximating W and H, using a particular rule), and the Hierarchical Alternating Least Squares (HALS) method, which attempts to find the columns of W one by one, through.
A common trick for NNMF is to use Singular Value Decomposition (SVD) first to find a rough approximation for W and H and then refine it gradually. Alternatively, we can use regularization to ensure that W and H's elements remain relatively small, resulting in a more stable solution. However, keep in mind that the solutions NNMF yields are approximate and correspond to local minima of the objective function. Fortunately, there are programming libraries that do all the heavy-lifting for us when it comes to NNMF. One such library is the NMF.jl one, in Julia. If you are more of a Python user, you can use the NMF function from the decomposition class of the sklearn package. Both of these libraries are well-documented so getting the hand of them is relatively straight-forward. You can learn more about data science methods like this one in my book, Data Science Mindset, Methodologies, and Misconceptions. In this book, I talk about all kinds of processes and techniques used in data science so that even the non-technical reader can grasp the intuition behind them and gain an understanding and appreciation of them. This book provides several external resources to go more in-depth on these topics and organize how you continue learning about this field, without getting lost in it. So, check it out when you have some time. Cheers!  Data science knowledge is vast and varied. It entails an in-depth understanding of data, the impact of models on this data, and various ways to refine the data making it more useful for these models. Also, it has to do with ways to depict this data graphically and make useful predictions based on it, using new data as inputs. Specialized data science knowledge also involves depicting this data in different ways (e.g. via a graph structure), gathering it from various sources (e.g. text), and creating interactive applications based on the data models built. Naturally, all this can be of value not just to data scientists but also to other data-related professionals. Let's examine how. So, how can data science knowledge help data analysts and business intelligence professionals? After all, they are the closest to the role of a data scientist and deal with data in similar ways. These professionals can benefit from data science knowledge through a more in-depth understanding of the data, particularly when it comes to ETL processes and data wrangling. Also, for those more geared towards data models, they can learn more advanced models such as the machine learning models data scientists use and start using them in their work. As for data modelers (data architects), data science knowledge can help those professionals too. After all, designing a useful information flow or implementing such a design into a database is closely linked to how this information is used. So, by understanding the potential different variables have (something that's bread and butter for a data scientist), a data modeler can optimize his work and build systems that are more future-tolerant. That is particularly useful in cases where the domain is dynamic, like in the e-commerce field. Programmers can benefit a lot from data science knowledge too, especially those versed in OOP and functional languages (e.g. Julia and Scala). After all, data science involves a great deal of programming so there is a good overlap in the skill set of the two types of professionals. For this reason, many programmers end up getting into data science once they familiarize themselves with data science models, something they can do easily once they get exposed to data science knowledge. Finally, data-driven managers have a lot to gain from data science knowledge, perhaps more than any other professional. The reason is that f you are involved in data-driven projects, you need to know what’s possible with the data you have and what kind of products or services you can build using this data. This is something you can do even without getting your hands dirty, by thinking in terms of data science. So, having some data science knowledge (particularly knowledge related to how data science is applicable and what data products look like), can go a long way. As a bonus, recruiting data scientists to implement your ideas is much easier if you are familiar with data science, something your recruits are bound to appreciate. If you found this article interesting, you can learn more about data science and how it is leveraged in an organization through a book I co-authored last year. Namely, the Data Scientist Bedside Manner book covers this and similar topics thoroughly, along with some other practical knowledge on this subject. So, check it when you have the chance and spread the word about it to friends and colleagues in the aforementioned lines of work. Cheers! Fun and Educational Things to Do During the Holidays (Not Only Data Science and AI Related)12/21/2020  The holiday season is upon us, something that translates for many of us to more free time. That’s why I decided to keep this article light and perhaps fun. After all, we all deserve a break after a year like this one! Regardless of your plans for the holidays, there are certain things you can do that are both enjoyable and educational. For starters, if you are interested in programming (particularly recreational programming), you can check out the Exercism.io site. Exercism is an educational non-profit that aims to help people pick up a new programming language, including some of the more esoteric ones like bash. The site comprises of a series of exercises, some of which are on the language track while others are self-paced. As you proceed with the track, you unlock new exercises and explore new concepts in your language of choice. Also, there is some mentoring aid if you choose that option, helping you when you get stuck and/or showing you better ways to solve the exercises through useful tips and hints. Another thing you can do is watch some videos on data science, or even take a course on the subject of data science or A.I. I know it may seem like a lot, but there is a lot of good material out there if you know where to look, which can help you augment your skills and know-how. Also, the cost of all this is fairly low, compared to what it used to be, so this sort of material is more accessible than ever before. If you are up for more hands-on activities, you can play around with some data and do a mini data science project. Pick a dataset you are interested in and see what insights you can dig out from it. The project doesn't have to be 100% covered in explanatory text, but even without it, it can be good practice for you. Bonus points if you use a new technique or method. Furthermore, you can check out some data science articles to be more up to speed on the latest trends or view certain topics from a different perspective. This blog can be a good place to start. Of course, if you want to read something that covers the subject in more depth, you can check out my data science books. You can find all of them at the publisher’s website, along with other technical books on similar subjects (esp. data modeling). Also, if you were to apply the coupon code DSML at the checkout, you can receive a 20% discount on whatever book you buy from that site. So, there you have it. With these suggestions, you can now make good use of your time, without stressing. Besides, when you learn something this way, it tends to stick longer. Who knows, some of these activities may bear good fruits that you can leverage in the new year. Happy holidays!  JSON stands for JavaScript Object Notation, and it's one of the most popular data file formats, not just for Java but all programming languages. It involves semi-structured data, just like XML, but most data professionals, including data scientists, prefer it. But why is it so popular, and how is it useful in data science work? In this article, we'll explore just that. The usefulness of JSON lies in the fact that it's versatile and relatively concise. What's more, it's faster than other similar file formats, while it's already widely used for web-related applications, making it easy to find mature programming libraries for it. Moreover, JSON is very intuitive, and many text editors have built-in functionality for viewing such files in an easy-to-read way. Furthermore, it's easy to create and edit JSON files yourself using a text editor, while programmatically, it's a walk in the park. JSON’s compatibility with NoSQL databases is one of its fortes. Such systems include databases like MongoDB, which are quite popular in data science. Most new databases are also compatible with JSON as it's become a kind of standard. Additionally, JSON and the dictionary data structure go hand-in-hand, something vital in data science work. So, if you want to load some data from a JSON file, you can store it in a dictionary, while if you have a dataset (any dataset), you can code it as a dictionary (each variable being a key) and store it as a JSON file. The JSON.jl library in Julia is one worth knowing about, especially if you want to use this programming language in your data science work. This fairly simple package enables you to parse and create JSON files, using the primitive Dict structure. A convenient library to know, even if it's still in version 0.21.x. JSON.jl makes use of the FileIO package on the back-end and its most useful functions are parse(), parsefile(), and print(). Note that the latter works different data structures, not just dictionaries. The JSON file format is closely linked to APIs too. The latter are particularly useful in various data-related applications and are instrumental in certain data products developed by data scientists. Also, many APIs are essential for acquiring data, so knowing about them goes without saying. APIs are ideal for proof-of-concept projects, too, as they don't require too much work to get one up-and-running. As a result, they are a versatile tool for all sorts of projects, particularly those with a web presence. The API Success book describes this technology in sufficient depth, without getting too technical. Besides, if you understand APIs' usefulness and how they fit into the bigger picture, it's not too hard to learn the technical aspects too, through a tutorial, for example. Note that you can get a 20% discount on this and any other book available at the publisher's website using the coupon code DSML. Using this code will also help me out, so you can see it as a way to support this blog. Cheers!  Delimited files are specialized files for storing structured (tabular) data. They are uncompressed and easy to parse through a variety of programs, particularly programming languages. Delimited files are widely used in data analytics projects, such as those related to data science. But what are they about, and why are they so popular? There are various types of delimited files, all of which have their use cases. The most common ones are commas separated variables (CSV) files and tab-separated variables (TSV). However, any character can be used to separate the various values of the variables, such as the pipe (|) or the semicolon (;). All of the delimited files are similar, though, in the sense that they contain raw data organized through the use of a delimiter (the character as mentioned earlier). Note that the variable names are included in the delimited file in many cases, usually in the top row. Like the rest of the file, that row also has its values (in this case, the variables) separated by the delimiter. Delimited files are super useful in data science work and data analytics work in general. They are straightforward to produce (e.g., most software has the "export as CSV" option available) and easy to access since they are, in essence, just text files. Also, every data science programming language has a library for loading and saving data in this file format. The fact that many datasets are available in this format is a consequence of that. Additionally, if a delimited file is corrupt, it's relatively manageable to pinpoint the problem and correct it. Yet, even if the problem is unfeasible to remedy, you can still access the healthy part of the file and retrieve the data there. In the case of specialized data files involving compression, this isn't possible most of the time. In Julia, there is a CSV library called CSV.jl (very imaginative name, I know!). Although its functionality is relatively basic, it is super fast (much faster than the Python equivalent), while it has excellent documentation. Despite what the name suggests, this library can be used for delimited files, not just CSVs. The parameter "delim" is responsible for this, though you don't need to set it always, since the corresponding function can figure out the delimiter character on its own, most of the time. Delimited files are instrumental in data science work, but they aren't always the best option. For example, in cases when you are dealing with semi-structured or unstructured data, it's best to use a different format for your data files, such as JSON. Also, suppose you are working with NoSQL databases. In that case, delimited files may not be useful at all, since the data in those databases are best suited for a dictionary data structure, such as that provided by JSON and XML files. If you want to learn more about this topic and other topics related to data science work, feel free to check out my book Data Science Mindset, Methodologies, and Misconceptions. In this book, I talk about all data science-related matters, including data structures and such, providing a good overview of all the material related to this fascinating field. So, check it out when you have the chance. Cheers!  Structured Query Language, or SQL for short, is a powerful database language geared toward structure data. As its name suggests, SQL is adept at querying databases to acquire the data you need, in a useful format. However, it includes commands that involve the creation or alteration of databases so that they can fit the requirements of your data architectural model. SQL is essential for both data scientists and other data professionals. Let's look into it more, along with its various variants. Although the tasks performed by SQL (when it comes to data wrangling), you can perform with other programming languages too, its efficiency and relative ease of use make it a great tool. Perhaps that's why it's so popular, with many variants of it. The most well-known one, MySQL, specializes in web databases, though it can also be used for other applications. Other variants, such as PostgreSQL, are mostly geared towards the industry. All this may seem somewhat overwhelming, considering that each variant has its peculiarities. However, all of these SQL variations are similar in their structure, and it doesn't take long to get accustomed to each one of them if you already know another SQL variant. Yet, all of the SQL databases tend to be limited in the structure of the data. In other words, if your data is semi-structured (i.e., there are elements of structure in it but it's not tabular data), you need a different kind of database. Namely, you require a NoSQL (i.e., Not Only SQL) one. Databases like MongoDB, MariaDB, etc. are of this category. Note that NoSQL databases have many commands in common with SQL, but they are geared toward a different organization of column-based data. This characteristic enables them to be faster and able to handle dictionary-like structures. Naturally, there are plenty more kinds of SQL variants, primarily under the NoSQL paradigm. However, beyond these SQL-like databases, there are also those related to graphs, such as GraphQL. These specialized systems are geared towards storing and querying data in graph format, which is increasingly common nowadays. All these database-related matters are under the umbrella of data modeling, a field geared towards organizing data flows, optimizing the ways this data is stored, and ensuring that all the people involved (the consumers of this data) are on the same page. Although this is not strictly related to the data science field, it's imperative, plus knowing about it, enables better communication between the data architects (aka data modelers) and us. You can learn more about SQL and other data modeling topics through the Technics Publications website. There, you can use the coupon code DSML for a 20% discount on all the titles you purchase. Note that this code may not apply to all the video material you'll find there, such as the courses offered. However, you can use it to get a discounted price for all the books. I hope you find this useful. Cheers!  (the lady in the picture is a metaphor for the "feature" or "set of features" in the dataset at hand)
If data science, a feature is a variable that has been cleaned and processed so that it's ready to use in a model. Most data models are sensitive to their inputs' scale, so most features are normalized before they are useful in these models. Naturally, not all features add value to a model or a data science project in general. That's why we often need to evaluate them, in various ways, before we can proceed with them in our project. Evaluating features is an often essential part of the data engineering phase in the data science pipeline. It involves comparing them with the target variable in a meaningful way to assess how well they can predict it. This assessment can be done by either evaluating the features individually or in combination. Of these approaches, the first one is more scalable and more manageable to perform. Since there are inevitable correlations among the features, the individual approach may not paint the right picture, since two "good" features may not work well together since they depict the same information. That's why evaluating a group of features is often better, even if it's not always practical. Note that the usefulness of a feature usually depends on the problem at hand. So, we need to be clear as to what we are trying to predict. Also, even though a good feature is bound to be useful in all the data models involved, it's not utilized the same way. So, having some intimate understanding of the models can be immensely useful for figuring out what features to use. What's more, the form of the feature is also essential in its value. If a continuous feature is used as is, its information is utilized differently than if it is binarized, for example. Sometimes, the latter is a good idea as we don't always care for all the information the feature may contain. However, it's best not to binarize continuous features haphazardly since that may limit the data models' performance. The methodology involved also plays a vital role in the feature evaluation. For example, if you perform classification, you need to assess your features differently than if you are performing regression. Also, note that features play a different role altogether when performing clustering as the target variable doesn't participate (or it's missing altogether). As a result of all this, evaluating features is crucial for dimensionality reduction, a methodology closely linked to it and usually follows it. You can learn more about features and their use in predictive models in my latest book, Julia for Machine Learning. This book explores the value of data from a machine learning perspective, with hands-on application of this know-how on various data science projects. Feature evaluation is one aspect of all this, which I describe through the use of specialized heuristics. Check out this book when you have a chance and learn more about this essential subject! |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
December 2022
Categories
All
|
 RSS Feed
RSS Feed