 Dimensionality reduction is the methodology involving the coding of a dataset's information into a new one consisting of a smaller number of features. This approach tries to address the curse of dimensionality, which involves the difficulty of handling data that comprises too many variables. This article will explore a primary taxonomy of dimensionality reduction and how this methodology ties into other aspects of data science work, particularly machine learning. There are several types of dimensionality reduction out there. You can split them into two general categories: methods involving the feature data in combination with the target variable, and methods involving the feature data only. Additionally, the second category methods can be split into those involving projection techniques (e.g., PCA, ICA, LDA, Factor Analysis, etc.), and those based on machine learning algorithms (e.g., Isomap, Self-organizing maps, Autoencoders, etc.). You can see a diagram of this classification below. 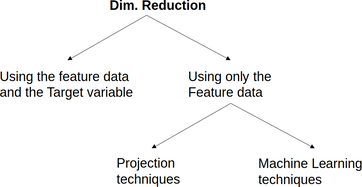 The most noteworthy dimensionality reduction methods used today are Principle Components Analysis (PCA), Uniform Manifold Approximation and Projection (UMAP), and Autoencoders. However, in cases where the target variable is used, feature selection is a great alternative. Note that you can always combine different dimensionality reduction methods for even better results. This strategy works particularly well when the methods come from different families. It's important to remember that dimensionality reduction is not always required, no matter how powerful it is as a methodology. Sometimes the original features are good enough, while the project requires a transparent model, something not always feasible when dimensionality reduction is involved. What's more, dimensionality reduction always involves some loss of information, so sometimes it's not a good idea. It's crucial to gauge all the pros and cons of applying such an approach before doing so, since it may sometimes not be worth it because of the compromises you have to make. Many of the datasets found in data science projects today involve variables that are somehow related to each other, though this correlation is a non-linear one. That's why many traditional dimensionality reduction methods may not be as good, especially if the datasets are complex. That's why machine learning methods are more prevalent in cases like this and why there is a lot of research in this area. What's more, these dimensionality reduction methods integrate well with other machine learning techniques (e.g., in the case of autoencoders). This fact makes them a useful addition to a data science pipeline. In my book Julia for Machine Learning, I dedicate a whole chapter in dimensionality reduction, focusing on these relatively advanced methods. Additionally, I cover other machine learning techniques, including several predictive models, heuristics, etc. So, if you want to learn more about this subject, check it out when you have the chance. Cheers!
0 Comments
 The world of data professionals is sophisticated and diverse, especially nowadays. In involves professionals whose expertise ranges from the design of data flows to databases, data analytics models, machine learning systems, and APIs that connect the users to a cloud-based solution. It's not a simple matter, while the variety and depth of all these roles leave people bewildered and uncertain about what this ecosystem is and what it can do for an organization.
We can attempt to gain an understanding of this world by reviewing the various professionals found in it. First of all, we have the data architects (aka data modelers) responsible for designing data/information flows, facilitating communication among the people in an organization, and developing the infrastructures for all movement and storage of the organization's data. They are often involved in database solutions as well as ETL processes and the creation of glossaries. Data architects are essential in an organization, mainly when there is plenty of data involved, or the data plays a vital role in the organization's workflow. Most modern organizations are like that, while the abundance of data makes these professionals necessary. Beyond this role, there are also data analytics professionals, particularly data scientists. This sort of professionals is involved in deriving values from the available data, usually through discovering insights. Data scientists are more geared towards messy (e.g., unstructured or highly noisy) data and more advanced models. All data analytics professionals work with databases through focused querying of them, while the creation of visuals based on the data is an essential part of their pipeline. Naturally, this role involves some programming (more so in the case of data scientists) and communication with each project's stakeholders. The creation of dashboards is a typical deliverable in this role, though other kinds of data products are sometimes developed instead. Data engineers are also an essential kind of professionals in this ecosystem. This role entails data governance, particularly when big data is involved as well as various ETL processes that facilitate data analytics work. Managing containers in the cloud and specialized software like Spark is part of these professionals' job descriptions. Data engineers are heavy on programming and often deal with computer clusters, be it physical or virtual. Their communication with the project stakeholders is relatively limited, although they liaise with data scientists quite a bit. Some data engineers are well-versed in data science methods, particularly the development and deployment of predictive models. Finally, business intelligence (BI) folks also have a role to play in the data world. This kind of professionals involves liaising with the managers and other project stakeholders. BI professionals tend to be more knowledgeable regarding the inner workings of an organization. Simultaneously, their use of data is limited to basic models, useful graphics, and descriptions of the problem at hand. BI professionals are more related to data analysts, though they tend to be more involved in high-level tasks. Also, their use of programming is minimal. If you want to learn more about the data professionals' world, I invite you to check out some great books, like those available at the Technics Publications' site. Although geared more towards data modeling, this publisher covers the subject quite well, providing practical knowledge from various professionals in the fields as mentioned earlier. If you use the coupon code DSML, you can get a 20% discount on any books purchased. Check it out when you have the chance. Cheers!  As privacy matters gain more value these days, transparency also gains a lot of value in data science work. This is to be expected for another reason, which I hope it has become more obvious if you have been following this blog: transparent models are easier to explain to others. Beyond these advantages, there are other ones too (such as transparent models are easier to tweak and optimize), which I'm not going to elaborate on right now. Instead, I'm going to look at the various data models used in data science and where they fall on the transparency spectrum. On the one extreme of this spectrum lie the most transparent data models. These are usually Stats-based since they can provide exact proportions of each feature's contribution. Also, you know exactly what's going on with the decisions involved in the predictions they yield. Even if you know nothing about data science you can still make sense of these models and understand the predictions they yield. The main disadvantage of these models is that they are not as accurate, partly because of the overly simple processes they use. On the other extreme of the spectrum, you can find the most opaque data models. These are usually AI-based and are referred to as black boxes. Not only do they not tell us anything about feature importance, but trying to explain their inner workings is a futile task. However, they tend to have an edge in performance when it comes to accuracy, plus they require very little prep work for the data they use (data engineering). Somewhere in the middle of the spectrum lie all the other models, mostly under the machine learning category. These include random forests and boosted trees (some transparency), k nearest neighbor (very little transparency), support vector machines (no transparency), and fuzzy logic systems (pretty decent transparency). That’s a category of models most people forget since they tend to think of transparency as a binary attribute. Finally, it’s good to remember that transparency is usually linked to a business requirement. Also, sometimes the performance you obtain from the black box models is a good trade-off since some projects require high accuracy in the predictions involved. So, transparency is not always a necessity even if it can facilitate the communication of these models to the project stakeholders. As a result, it's always good to think about whether you need this extra transparency that a statistical model may offer you if you can achieve better performance with a less transparent model. For more information about transparency and other aspects of data science models (particularly machine learning related), you can check out my latest book, Julia for Machine Learning. It is a very hands-on kind of book, which doesn't neglect to provide a lot of information needed to build the right mindset when it comes to data science work. Also, it includes lots of examples and links to useful resources that can help you understand all the concepts involved.  Although I covered this topic briefly about a year and a half ago, it seems that it's due for an update. After all, many people still are unaware of this terrific tool, while I always get positive feedback when I introduce it to mentees of mine. In a nutshell, Wakelet is a simple collection tool for organizing and sharing content over the internet. The collections (aka wakelets) can be private, public, or shareable with specific individuals via a link. The Wakelet website does a great job of informing people about the merits of this tool, which is quite popular among educators. What it doesn't tell you is that it's great for data science practitioners too. Namely, a wakelet can be a great place to exhibit your portfolio of projects, as well as any other material that you’ve created that’s relevant to a data science career. You can also include any publications you may have, any videos you’ve created, and any programs you’d like to share with the data science world. The big advantage of wakelets is that you can add supplementary text to accompany your material, so the whole thing is more meaningful and accessible to your audience. The free graphics the program offers are also useful for making the collection more appealing to newcomers. So far I’ve developed a few wakelets, mostly around the AI-related articles I’ve written and the books I’ve authored. Also, there are a few wakelets that I keep private as well as another one I’ve shared with an associate of mine. What’s more, I plan to continue creating wakelets as I have more material to share (e.g. webinars, videos, etc.) The community aspect of Wakelet is something I’ve recently discovered and I’m in the process of exploring. In any case, it’s always interesting to view other people’s wakelets and get ideas about how to organize shareable content elegantly. The collaboration aspect of Wakelet is something worth exploring too. It involves two or more people working on the same wakelet, either contributing or editing content. This can be done in the traditional way whereby the contributors access a wakelet independently, or they can collaborate through MS Teams and share content from there (e.g. conversations) through their wakelet. Wakelet collaboration is still fairly new as a feature but it's getting quite popular and it's something worth looking into, for sure. Wakelet is quite popular among content creators but it seems that its target audience is growing as it develops new features and a larger community of users. As a result, it may become the go-to option for sharing any content that's large enough to not fit in a single document. Also, as wakelets can be organized efficiently and elegantly in the wakelet page, it makes sense to create several of these collections and perhaps even link them together, when this makes sense. In any case, the fact that all these collections are also accessible through the corresponding app makes it a versatile and practical tool. So, I invite you to check it out and let me know what you think about it. Cheers!  With all this talk these days about Statistics and other frameworks and their immense value in data science, it’s good to be more pragmatic about this matter. After all, it’s not a coincidence that Machine Learning maintains the top position both as a framework and as a specialization when it comes to data science work. In this article, we'll explore why this is. First of all, machine learning is a more scientific paradigm for data science. It doesn't make any assumptions as it relies on the data at hand and nothing else. Well, there are also the ML models that it makes use of, but it doesn't try to model everything as this or the other distribution and rely on metrics based on these distributions. The scientific approach has proven itself to be very useful in understanding the world, so it only makes sense that it is used (in the form of machine learning methods) in data science too. What’s more, machine learning makes use of more advanced methods than other frameworks. After all, it makes sense that if a framework works well, as in the case of machine learning, more methods are researched and refined. As a result, the models that machine learning brings to the table are more state-of-the-art and efficient. This makes using the machine learning framework a no-brainer, particularly when it comes to critical processes where accuracy and efficiency are key requirements. Also, machine learning nowadays is powered to a great extent by AI, creating powerful models that outperform anything else available to a data scientist. This may be a trend that's here to stay since many AI-based model have proven to be exceptionally good and versatile. Although these models have special requirements that may not be met in every data science option, it's good that there is this option available for data science work. Moreover, machine learning is easier to learn and use since it doesn't have a lot of theory behind it. As a result, you don't need to spend a lot of time learning it or having to worry about the requirements of each model, like in Statistics. Of course, there is some theory in this framework too, but it's fairly straight-forward and doesn't require too specialized math to learn it to an adequate degree. Finally, there are lots of libraries nowadays for every machine learning model or process, making it easy to implement. In other words, you don't have to do a lot of coding to get your machine learning method up and running. Also, the fact that there is usually adequate documentation in these libraries makes it easier to understand the corresponding programs and the techniques too, supplementing your learning. Speaking of learning, if you wish to learn more about machine learning through a hands-on approach to the subject, feel free to check out my latest book, Julia for Machine Learning (Technics Publications). There I talk about the subject in some depth, while I explain how you can use Julia to deploy different kinds of machine learning models and heuristics. Cheers!  In a previous article we talked about the value of data modeling and how it is related to data science as a field. Now let’s look at some great ways to learn more about this field. Specifically, Technics Publications offers a few classes/workshops on data modeling this Autumn:
What’s more, you can get a 20% discount on them, if you use the coupon code DSML. You can use the same code for most of the books available on that site. Check it out!  JuliaCon stands for Julia Conference and it’s an annual educational/promotional event that Julia Computing organizes. The latter is the Massachusetts based company that manages the development and evolution of the programming language. So, JuliaCon is its way of promoting the language and keeping everyone interested in it updated on its recent developments. JuliaCon is primarily for programmers and members of the scientific community employing Julia in their work. However, it also appeals to Julia enthusiasts and anyone interested in the ecosystem of the language, as well as its numerous applications. It’s not targeted at data scientists per se though lately there are several sessions in the conference that involve Machine Learning and A.I. since lots of people are interested in these areas. Note that most of the people involved in these packages are not professional data scientists, though some of them are familiar with the field and have written papers about it (mostly academic papers). So, if you are looking to learn about data science in this conference you may be disappointed, yet if you just wish to explore what Julia brings to the table when it comes to data science tools, you may be in for a treat. This year several interesting things were revealed in the JuliaCon, which I attended. Namely, the Tuesday workshop on improving Julia code performance and compatibility with other programming languages was truly worth it as it covered a variety of tweaks that can make a script use less memory and/or work faster. Also, being able to incorporate Python and C code in a Julia script was something that was covered thoroughly, more than any documentation page could. Unfortunately, some sessions weren’t properly synced and were either delayed or altogether missing from the live stream (at least on my Firefox browser). This definitely took away from the whole conference experience. Perhaps if the whole conference was done on Zoom, it would have been a smoother experience. The Q&A chat in the workshops was a nice touch though and added a lot to them. The sessions themselves were pretty good overall, covering a variety of topics, from the more technical to the more application-oriented. They were organized in different tracks, making it easy to find the session you were most interested in. The Interactive data dashboards with Julia and Stipple session stood out. Even though it was a fairly short one, it was very relevant to data science work and with good examples, showcasing its functionality. I’d definitely recommend you watch the recording of it, which should be available by now at the Julia YouTube channel, along with the other sessions of the conference. JuliaCon usually takes place in either the US or Europe. This year it was Europe’s turn to host the conference and it was scheduled to take place in Lisbon, Portugal. Although that laid-back Mediterranean capital would be ideal for such a conference (definitely more accessible than London, where it took place a couple of years ago), this year for the first time it took place online. This was due to the safety measures related to Covid-19 that impacted logistics severely. Anyway, if all goes well, it's expected that next year it will take place in the US. If you wish to delve more into Julia feel free to check out my books on the subject. Cheers!  It may seem that we are getting off-track here but this is highly relevant to any data scientist, particularly those on the data engineering path. Yet, as this is an overloaded term, let’s first clarify what we mean when we say data modeling as a field. In a nutshell, data modeling is the field that deals with the design and implementation of databases, and any organization of data flows in an environment. It entails a combination of design elements such as UML diagrams, and some analytical aspects, such as code for creating and querying databases, based on certain specialized diagrams called database schemas (the image used above is one such schema, though in practice they tend to be more detailed). Data modeling professionals also deal with the cloud since many databases these days live there. Also, some data modeling experts work directly with the business and help the stakeholders of a project optimize the flow of information in the various departments of their organization, or build pipelines to better process the data at hand. Data modelers come in different shapes and forms. From the more business-oriented ones to the more hands-on ones (e.g. DBAs), they cover a wide spectrum of roles. This is akin to the data scientists, who also are quite specialized these days. However, data modelers have been around longer so their roles are more established and more acknowledged in the business world. After all, databases have been around since the early days of computing, even if only recently have they evolved enough to be an important component in modern technologies such as big data governance and cloud computing. Also, note that most data modelers these days are involved in NoSQL, even if they are proficient in SQL-based languages. The reason is that most data today is semi-structured, something that NoSQL databases are designed for. Of course, structured data remains but usually, it's not as much nor as easy to produce. Hopefully by now the link between the data modeling field and the data science one has started to become clear. After all, they are both data-oriented fields. The common link is databases since that's the core product of data modelers and the starting point of most data science projects. Without databases, we don't have much to work with so it's not uncommon to work with data modelers, particularly in the initial stages of a data science project. Also, data modelers have an interest in analytics so it's not uncommon for them to dabble with predictive models, e.g. in a proof-of-concept project. What's more, data modeling conferences can be a valuable educational resource for data scientists as it enables us to view parts of an organization that aren't always evident in a data science conference, where the focus is more technical in general. Data modeling is particularly relevant if not essential to data engineers, those data scientists who specialize in the initial stages of a data science project. This involves a lot of ETL work as well as querying and augmenting databases. So, data engineers need to have a more concrete understanding of data modeling, even if it is on the more hands-on part of the field. After all, anyone can do some basic querying or table-creating, but to build an efficient and scalable database it takes much more than that. Fortunately, nowadays it's easier than ever to learn more about data modeling. Also, you can do that without spending too much time, since the material on the field is well organized and in abundance. The fact that it's not a "sexy profession" like that of the data scientist, makes it less prone to hype and halfwits taking advantage of it through low-quality material. What's more, some publishers specialize in data modeling, such as Technics Publications. Finally, using the promo code DSML you can get a 20% discount on all the books and any webinars the publishing house offers.  Throughout our careers in data science and AI, we constantly encounter all sorts of obstacles that hinder our development. This is something inevitable, particularly when we undertake a role that's constantly evolving. However, the biggest obstacle is not something external, as one might think, but something closer to home. On the bright side, this means that it’s more within our control than anything subject to external circumstances. Let’s clarify. The biggest obstacle is related to the limits of our aptitude, something primarily linked to our knowledge and know-how. After all, no one knows all there is to know on a subject so broad as data science (or AI). However, as we gather enough knowledge to do what we are asked to, we are overwhelmed by the idea that we know enough. Eventually, this can morph into a conviction and even expand, letting us cultivate the illusion that we know everything there is to know in our field. Naturally, nothing could be further from the truth since even a unicorn data scientist has gaps in her knowledge. One great way to avoid this obstacle is to constantly challenge yourself in anything related to our field. I'm not talking about Kaggle competitions and other trivial things like that. After all, these are hardly as realistic as data science challenges. I'm referring to challenges to techniques and methods that you are lacking as well as refining those that you already have under your belt. This may seem simple but it's not, especially since no one enjoys becoming aware of the things he doesn't know or doesn't know fully. Perhaps that’s why developing ourselves isn’t something easy or popular. Another way to enhance ourselves is through reading technical books related to our field. Of course, not all such books are worth your while, but if you know where to look, it's not as challenging a task. What's more, it's good to remember that the value of such a book also depends on how you process this new information. For example, in many such books, there are exercises and problems that the reader is asked to solve. By taking advantage of such opportunities, you can learn the new material better and grow a deeper understanding of the topics presented. One way for learning more is through Technics Publications books. Although many of the books from that publishing house are related to data modeling, there are a few data science-related ones as well as a couple on AI. Of course, even the data modeling books can be useful to a data scientist, since we often need to deal with databases, particularly in the initial stages of a project. Also, if you were to buy a book from this publisher using the coupon code DSML, you can get a 20% discount. The same applies to any webinars you may register for. So, if the cost of this material is an obstacle for you, at least with this code you can alleviate it and get a bigger bang for your buck!  Normally I don't do book reviews on this blog but for this one, I thought I'd make an exception. After all, it's not every day I encounter a book that tackles topics like Logic head-on, without getting all abstract and theoretical. This book not only manages to remain practical but also gives a good overview of the topic of logic, something that every data professional can benefit from. Note that this book is on the subject of data modeling, which although related to data science, is its own field and is concerned with databases, as well as the design of such systems.
First of all, the book provides an excellent introduction to Logic, without getting too mathy about the topic. When I was looking into Ph.D. topics, I briefly considered doing my research on this subject. However, I quickly dismissed it because it was too abstract and theoretical. This book addresses this point and presents the subject in a very practical way, making it relatable and interesting. This is something it manages by providing a connection between Logic and databases, with plenty of examples. This enables the reader to maintain a practical viewpoint across the different topics covered in the book and view logic as a useful tool. What’s more, the author does a pretty good review of other books on the subject with a robust criticism of their strengths and weaknesses. In a way, it feels like reading a bunch of books, getting the gist of their approaches, without having to go through their text. It is evident that the author knows the subject in great depth, something that he exhibits through his approach on the subject, which is also quite distinct. For example, he provides a great analysis of topics that weren't covered properly elsewhere such as that of integrity. Also, the author provides lots of references for each topic at the end of each chapter, making the whole book feel a bit academic in that sense, but without the rigid style that characterizes such books. However, for someone who wishes to explore the various topics further, this list of relevant resources at the end of each chapter can be quite handy. Moreover, the book is fairly easy to understand even for non-experts in data modelings or logic. This is important since it’s not common to find a technical book that’s accessible to non-experts in the topic. This book, however, seems to have a very broad audience, even people who know very little about the subject. Finally, there are lots of definitions of key concepts and a scientific approach to the subject overall. This is also not very common since not all technical books are written by scientists. Also, many people nowadays write a book based on their experience and empirical knowledge on a subject. This book, however, was written in a scientific manner, even if it doesn't have the typical academic style. So, if you are interested in buying this book, you can do so directly from the publisher. Also, if you were to use the code coupon DSML you can get a 20% discount, making this purchase a bargain. Note that this code applies to other books available at the Technics Publications site, including some of the webinars. |
Zacharias Voulgaris, PhDPassionate data scientist with a foxy approach to technology, particularly related to A.I. Archives
December 2022
Categories
All
|
 RSS Feed
RSS Feed